基本用法
要使用<canvas>元素,必须先设置其width和height属性,指定可以绘图的区域大小。出现在开始和结束标签中的内容是后备信息,如果浏览器不支持<canvas>元素,就会显示这些信息。如下例子:
<canvas id="drawing" width="200" height="200"> A drawing of something.</canvas>
与其它元素一样,<canvas>元素对应的DOM元素对象也有width和height属性,可以随意修改。而且,也可以通过CSS为该元素添加样式,如果不添加任何样式或者不绘制任何图形,在页面中是看不到该元素的。
要在这块画布(canvas)上绘图,需要取得绘图上下文。如下代码:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //更多代码 }
使用toDataURL()方法,可以导出在<canvas>元素上绘制的图像。这个方法接收一个参数,即图像的MIME类型格式,而且适合用于创建图像的任何上下文。比如,要取得画布中的一副PNG格式的图像,如下代码:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ //取得图像数据的URI var imgURI = drawing.toDataURL("image/png"); //显示图像 var image = document.createElement("img"); image.src = imgURI; document.body.appendChild(image); }
2D上下文
使用2D绘图上下文提供的方法,可以绘制简单的2D图形,比如矩形、弧线和路径。2D上下文的坐标开始于<canvas>元素的左上角,原点坐标是(0,0)。所有坐标值都基于这个原点计算。x值越大越靠右,y值越大越靠下。
填充和描边
2D上下文的两种基本绘图操作是填充和描边。填充,就是用指定的样式(颜色、渐变或图像)填充图形;描边,就是只在图形的边缘画线。大多数2D上下文操作都会细分为填充和描边两个操作,而操作的结果取决于两个属性:fillStyle和strokeStyle。
这两个属性的值可以是字符串、渐变对象或模式对象。而且他们的默认值都是“#000000”。如果为他们指定表示颜色的字符串值,可以使用CSS中指定颜色值的任何格式,包括颜色名、十六进制码、rgb、rgba、hsl或hsla,如下例子:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); context.strokeStyle = "red"; context.fillStyle = "#0000ff"; }
绘制矩形
矩形是唯一一种可以直接在2D上下文中绘制的形状。与矩形有关的方法包括fillRect()、strokeRect()和clearRect()。这三个方法都能接收4个参数:矩形的x坐标、矩形的y坐标、矩形的宽度和高度。这些参数的单位都是像素。
首先fillRect()方法在画布上绘制的矩形会填充指定的颜色。填充的颜色通过fillStyle属性指定,比如:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //绘制红色矩形 context.fillStyle = "#ff0000"; context.fillRect(10,10,50,50); //绘制半透明的蓝色矩形 context.fillStyle = "rgba(0,0,255,0.5)"; context.fillRect(30,30,50,50); }
strokeRect()方法在画布上绘制的矩形会使用指定的颜色描边。描边颜色通过strokeStyle属性指定。比如:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //绘制红色描边矩形 context.strokeStyle = "#ff0000"; context.strokeRect(10,10,50,50); //绘制半透明的蓝色描边矩形 context.strokeStyle = "rgba(0,0,255,0.5)"; context.strokeRect(30,30,50,50); }
以上代码绘制了两个重叠的矩形。不过,这两个矩形都只有框线,内部并没有填充颜色。
最后,clearRect()方法用于清除画布上的矩形区域。本质上,这个方法可以把绘制上下文中的某一矩形区域变透明。通过绘制形状然后再清除指定区域,就可以生成有意思的效果,例如把某个形状切掉一块。如下例子:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //绘制红色矩形 context.fillStyle = "#ff0000"; context.fillRect(10,10,50,50); //绘制半透明的蓝色矩形 context.fillStyle = "rgba(0,0,255,0.5)"; context.fillRect(30,30,50,50); //在两个矩形重叠的地方清除一个小矩形 context.clearRect(40,40,10,10); }
绘制路径
2D绘制上下文支持很多在画布上绘制路径的方法。通过路径可以创造出复杂的形状和线条。要绘制路径,首先必须调用beginPath()方法,表示要开始绘制新路径。然后,在通过下列方法来实际的绘制路径。
- arc(x,y,radius,startAngle,endAngle,counterclockwise):以(x,y)为圆心绘制一条弧线,弧线半径为radius,起始和结束角度(用弧度表示)分别为startAngle和endAngle。最后一个参数表示startAngle和endAngle是否按逆时针方向计算,值为false表示按照顺时针方法计算。
- arcTo(x1,y1,x2,y2,radius):从上一点开始绘制一条弧线,到(x2,y2)为止,并且以给定的半径radius穿过(x1,y1)。
- bezierCurveTo(c1x,c1y,c2x,c2y,x,y):从上一点开始绘制一条曲线,到(x,y)为止,并且以(c1x,c1y)和(c2x,c2y)为控制点。
- lineTo(x,y):从上一点开始绘制一条直线,到(x,y)为止。
- moveTo(x,y):将绘图游标移动到(x,y),不画线。
- quadraticCurveTo(cx,cy,x,y):从上一点开始绘制一条二次曲线,到(x,y)为止,并且以(cx,cy)为控制点。
- rect(x,y,width,height):以点(x,y)开始绘制一个矩形,宽度和高度分别为width和height指定。这个方法绘制的是矩形路径,而不是strokeRect()和fillRect()所绘制的独立的形状。
创建了路径后,接下来有几种可能的选择。如果想绘制一条想连接到路径起点的线条,可以调用closePath()。如果路径已经完成,你想用fillStyle填充它,可以调用fill()方法。另外,还可以调用stroke()方法对路径描边,描边使用的是strokeStyle。最后还可以调用clip(),这个方法可以在路径上创建一个剪切区域。
如下例子,绘制一个不带数字的时钟表盘。
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //开始路径 context.beginPath(); //绘制外圆 context.arc(100,100,99,0,2*Math.PI,false); //绘制内圆 context.moveTo(194,100); context.arc(100,100,94,0,2*Math.PI,false); //绘制分针 context.moveTo(100,100); context.lineTo(100,15); //绘制时针 context.moveTo(100,100); context.lineTo(35,100); //绘制描边 context.strokeStyle = "#ff0000"; context.stroke(); }
由于路径的使用很频繁,所以就有了一个名为isPointInPath()的方法。这个方法接收x和y坐标作为参数,用于在路径被关闭之前确定画布上的某一点是否位于路径上,例如:
if(context.isPointInPath(100,100)){ console.log("Point(100,100) is in the path") }
绘制文本
绘制文本主要有两个方法:fillText()和strokeText()。这两个方法都可以接收4个参数:要绘制的文本字符串、x坐标、y坐标和可选的最大像素宽度。而且,这两个方法都以下列3个属性为基础。
- font:表示文本样式、大小及字体,用CSS指定字体的格式来指定,如“10px Arial”。
- textAlign:表示文本对齐方式。可能的值有“start”、“end”、“left”、“right”和“center”。建议使用“start”和“end”,不要使用“left”和“right”,因为前两者的意思更稳妥,能同时适合从左到右和从右到左显示(阅读)的语言。
- textBaseline:表示文本的基线。可能的值有“top”、“hanging”、“middle”、“alphabetic”、“ideographic”和“bottom”。
这几个属性都有默认值,因此没必要每次使用它们都重新设置一遍值。fillText()方法使用fillStyle属性绘制文本,而strokeText()方法使用strokeStyle属性为文本描边。相对来说,还是使用fillText()的时候更多,因为该方法模仿了在网页中正常显示文本。例如下面代码在前面创建的表盘上方绘制了数字12:
context.font = "bold 14px Arial"; context.textAlign = "center"; context.textBaseline = "middle"; context.fillText("12",100,20);
上面坐标(100,20)表示的是文本水平和垂直中点的坐标。
//正常 context.font = "bold 14px Arial"; context.textAlign = "center"; context.textBaseline = "middle"; context.fillText("12",100,20); //起点对齐 context.textAlign = "start"; context.fillText("12",100,40); //终点对齐 context.textAlign = "end"; context.fillText("12",100,60);
由于绘制文本比较复杂,特别是需要把文本控制在某一区域中的时候,2D上下文提供了辅助确定文本大小的方法measureText()。这个方法接收一个参数,即要绘制的文本;返回一个TextMetrics对象。返回的对象目前只有一个width属性,但将来还会增加更多度量属性。
measureText()方法利用font、textAlign和textBaseline的当前值计算指定文本的大小。比如,假设你想在一个140像素宽的矩形区域中绘制文本 Hello world!,下面的代码从100像素的字体大小开始递减,最终会找到合适的字体大小。
var fontSize = 100; context.font = fontSize + "px Arial"; while(context.measureText("Hello world!").width > 140){ fontSize--; context.font = fontSize + "px Arial"; } context.fillText("Hello world!",10,100); context.fillText("Font size is" + fontSize + "px", 10,150);
变换
通过上下文的变换,可以把处理后的图像绘制到画布上。2D绘制上下文支持各种基本的绘制变换。创建绘制上下文时,会以默认值初始化变换矩阵,在默认的变换矩阵下,所有处理都按描述直接绘制。为绘制上下文应用变换,会导致不同的变换矩阵应用处理,从而产生不同的结果。
可以通过如下方法来修改变换矩阵。
- rotate(angle):围绕原点旋转图像angle弧度。
- scale(scaleX,scaleY):缩放图像,在x方向乘以scaleX,在y方向乘以scaleY。scaleX和scaleY的默认值都是1.0。
- translate(x,y):将坐标原点移动到(x,y)。执行这个变换后,坐标(0,0)会变成之前由(x,y)表示的点。
- transform(m1_1,m1_2,m2_1,m2_2,dx,dy):直接修改变换矩阵,方式是乘以如下矩阵。
m1_1 m1_2 dx
m2_1 m2_2 dy
0 0 1
- setTransform(m1_1,m1_2,m2_1,m2_2,dx,dy):将变换矩阵重置为默认状态,然后再调用transform()。
变换有可能很简单,也有可能很复杂,这都要视情况而定。比如,就那前面的绘制表针来说,如果把原点变换到变盘的中心,然后在绘制表针就容易多了,如下例子:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //开始路径 context.beginPath(); //绘制外圆 context.arc(100,100,99,0,2*Math.PI,false); //绘制内圆 context.moveTo(194,100); context.arc(100,100,94,0,2*Math.PI,false); //变换原点 context.translate(100,100); //绘制分针 context.moveTo(0,0); context.lineTo(0,-85); //绘制时针 context.moveTo(0,0); context.lineTo(-65,0); //绘制描边 context.strokeStyle = "#ff0000"; context.stroke(); }
把原点变换到时钟表盘的中心点(100,100)后,在同一方向上绘制线条就变成了简单的数学问题了。所有数学计算都基于(0,0),而不是(100,100)。还可以更进一步,像下面这样使用rotate()方法旋转时针的表针。
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //开始路径 context.beginPath(); //绘制外圆 context.arc(100,100,99,0,2*Math.PI,false); //绘制内圆 context.moveTo(194,100); context.arc(100,100,94,0,2*Math.PI,false); //变换原点 context.translate(100,100); //旋转表针 context.rotate(1); //绘制分针 context.moveTo(0,0); context.lineTo(0,-85); //绘制时针 context.moveTo(0,0); context.lineTo(-65,0); //绘制描边 context.strokeStyle = "#ff0000"; context.stroke(); }
虽然没有什么办法把上下文中的一切都重置回默认值,但有两个方法可以跟踪上下文的状态变化。如果你知道将来还要返回某组属性与变换的组合,可以调用save()方法。调用这个方法后,当时的所有设置都会进入一个栈结构,得以妥善保管。然后可以对上下文进行其它修改。等想要回到之前保存的设置时,可以调用restore()方法,在保存设置的栈结构中向前返回一级,恢复之前的状态。连续调用save()可以把更多设置保存到栈结构中,之后在连续调用restore()则可以一级一级返回,如下例子:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); context.fillStyle = "#ff0000"; context.save(); context.fillStyle = "#00ff00"; context.translate(100,100); context.save(); context.fillStyle = "#0000ff"; context.fillRect(0,0,100,200); //从点(100,100)开始绘制蓝色矩形 context.restore(); context.fillRect(10,10,100,200); //从点(110,110)开始绘制绿色矩形 context.restore(); context.fillRect(0,0,100,200); //从点(0,0)开始绘制红色矩形 }
需要注意的是,save()方法保存的只是对绘图上下文的设置和变换。不会保存绘图上下文的内容。
绘制图像
使用drawImage()方法可以把图像绘制到画布上。调用这个方法时,可以使用三种不同的参数组合。最简单的调用方式是传入一个HTML<img>元素,以及绘制该图像的起点的x和y坐标,如下:
window.onload = function(){ var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); var img = document.images[0]; context.fillStyle = "#000000"; context.fillRect(0,0,200,200); context.drawImage(img,10,10); } }
如果你想改变绘制后的图像大小,可以多传两个参数,分别表示目标宽度和目标高度。如下:
window.onload = function(){ var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); var img = document.images[0]; context.fillStyle = "#000000"; context.fillRect(0,0,200,200); context.drawImage(img,10,10,100,200); } }
执行后图像的大小变成了100*200。
除了上述两种方式,还可以选择把图像中的某个区域绘制到上下文中。drawImage()方法的这种调用方式总共需要传入9个参数:要绘制的图像、源图像的x坐标、源图像的y坐标、源图像的宽度、源图像的高度、目标图像的x坐标、目标图像的y坐标、目标图像的宽度、目标图像的高度。如下:
context.drawImage(img,0,10,50,50,0,100,40,60);
这行代码只把原始图像的一部分绘制到画布上。原始图像的这一部分起点为(0,10),宽和高都是50像素。最终绘制到上下文中的图像的起点为(0,100),而大小变成了40*60像素。
阴影
2D上下文会根据以下几个属性的值,自动为形状或路径绘制出阴影。
- shadowColor:用CSS颜色格式表示的阴影颜色,默认为黑色。
- shadowOffsetX:形状或路径x轴方向的阴影偏移量,默认为0。
- shadowOffsetY:形状或路径y轴方向的阴影偏移量,默认为0。
- shadowBlur:模糊的像素数,默认0,即不模糊。
这些属性都可以通过context对象来修改。
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //设置阴影 context.shadowOffsetX = 5; context.shadowOffsetY = 5; context.shadowBlur = 4; context.shadowColor = "rgba(0,0,0,0.5)"; //绘制红色矩形 context.fillStyle = "#ff0000"; context.fillRect(10,10,50,50); //绘制蓝色矩形 context.fillStyle ="rgba(0,0,255,1)"; context.fillRect(30,30,50,50); }
渐变
渐变由CanvasGradient实例表示,很容易通过2D上下文来创建和修改。要创建一个新的线性渐变,可以调用createLinearGradient()方法。这个方法接收4个参数:起点的x坐标、起点的y坐标、终点的x坐标、终点的y坐标。调用这个方法后,它就会创建一个指定大小的渐变,并返回CanvasGradient对象的实例。
创建了渐变对象后,下一步就是使用addColorStop()方法来指定色标。这个方法接收2个参数:色标位置和CSS颜色值。色标位置是一个0(开始的颜色)到1(结束的颜色)之间的数字。如下:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); var gradient = context.createLinearGradient(30,30,70,70); gradient.addColorStop(0,"white"); gradient.addColorStop(1,"black"); //绘制红色矩形 context.fillStyle = "#ff0000"; context.fillRect(10,10,50,50); //绘制渐变矩形 context.fillStyle =gradient; context.fillRect(30,30,50,50); }
确保渐变也形状对齐,如下代码:
function createRectLinearGradient(context,x,y,width,height){ return context.createLinearGradient(x,y,x+width,y+height); }
这个函数基于起点的x和y坐标以及宽度和高度值来创建渐变对象,从而让我们可以在fillRect()中使用相同的值,如下:
function createRectLinearGradient(context,x,y,width,height){ return context.createLinearGradient(x,y,x+width,y+height); } var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); var gradient = createRectLinearGradient(context,30,30,50,50); gradient.addColorStop(0,"white"); gradient.addColorStop(1,"black"); //绘制红色矩形 context.fillStyle = "#ff0000"; context.fillRect(10,10,50,50); //绘制渐变矩形 context.fillStyle =gradient; context.fillRect(30,30,50,50); }
要创建径向渐变(或放射渐变),可以使用createRadialGradient()方法。这个方法接收6个参数,对应这两个圆的圆心和半径。前三个参数指定的是起点圆的原心(x和y)以及半径,后三个参数指定的是终点圆的原心(x和y)以及半径。
如果想从某个形状的中心点开始创建一个向外扩散的径向渐变效果,就要将两个圆定义为同心圆。比如,拿前面创建的矩形来说,径向渐变的两个圆的圆心都应该在(55,55),因为矩形的区域是从(30,30)到(80,80),看下面代码:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); var gradient = context.createRadialGradient(55,55,10,55,55,30); gradient.addColorStop(0,"white"); gradient.addColorStop(1,"black"); //绘制红色矩形 context.fillStyle = "#ff0000"; context.fillRect(10,10,50,50); //绘制渐变矩形 context.fillStyle =gradient; context.fillRect(30,30,50,50); }
效果如下所示:

模式
模式其实就是重复的图像,可以用来填充或描边图形。要创建一新模式,可以调用createPattern()方法并传入两个参数:一个THML<img>元素和一个 表示如何重复图像的字符串。其中,第二个参数的值与CSS的background-repeat的属性值相同,包括“repeat”、“repeat-x”、“repeat-y”和“no-repeat”。如下例子:
window.onload = function(){ var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); var image = document.images[0], pattern = context.createPattern(image,"repeat"); //绘制矩形 context.fillStyle =pattern; context.fillRect(10,10,150,150); } }
效果如图:

createPattern()方法的第一个参数也可以是一个<video>元素,或者另一个<canvas>元素。
使用图像数据
2D上下文的一个明显长处就是,可以通过getImageData()取得原生图像数据。这个方法接收4个参数:要取得其数据的画面区域的x和y坐标以及该区域的像素宽度和高度。例如要取得左上角坐标为(10,5)、大小为50*50像素区域的图像数据,如下代码:
var imageData = context.getImageData(10,5,50,50);
这里返回的对象是imageData的实例。每个imageData对象都有三个属性:width、height和data。其中data属性是一个数组,保存着图像中每一个像素的数据。在data数组中,每一个像素用4个元素来保存,分别表示红、绿、蓝和透明度值。因此,第一个像素的数据就保存在数组的第0到第3个元素中,例如:
var data = imageData.data, red = data[0], green = data[1], blue = data[2], alpha = data[3];
数组中每个元素的值都介于0到255之间(包括0和255)。能够直接访问到原始图像数据,就能够以各种方式来操作这些数据。例如,通过修改图像数据,可以像下面这样创建一个简单的灰阶过滤器。
window.onload = function(){ var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"), image = document.images[0], imageData,data, i,len,average, red,green,blue,alpha; //绘制原始图像 context.drawImage(image,0,0); //取得图像数据 imageData = context.getImageData(0,0,image.width,image.height); data = imageData.data; for( i = 0, len = data.length; i < len; i+=4){ red = data[i]; green = data[i+1]; blue = data[i+2]; alpha = data[i+3]; //求得rgb平均值 average = Math.floor((red + green + blue) / 3); //设置颜色值,透明度不变 data[i] = average; data[i+1] = average; data[i+2] = average; } //回写图像数据并显示结果 imageData.data = data; context.putImageData(imageData,0,0); } }
如上代码,在把data数组回写到imageData对象后,调用putImageData()方法把图像数据绘制到画布上。最终得到了图像的黑白版。
效果如下:

合成
还有两个会应用到2D上下文中所有绘制操作的属性:globalAlpha和globalCompositionOperation。其中globalAlpha是一个介于0到1之间的值(包括0和1),用于指定所有绘制的透明度。默认值为0。如果所有后续操作都要基于相同的透明度,就可以先把globalAlpha设置为适当的值,然后绘制,最后再把它设置为默认值0。如下例子:
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //绘制红色矩形 context.fillStyle = "#ff0000"; context.fillRect(10,10,50,50); //修改全局透明度 context.globalAlpha = 0.5; //绘制蓝色矩形 context.fillStyle = "rgba(0,0,255,1)"; context.fillRect(30,30,50,50); //重置全局透明度 context.globalAlpha = 0; }
在上面例子中,我们把蓝色矩形绘制到了红色矩形上面,因为在绘制蓝色矩形前,globalAlpha设置为了0.5,所以蓝色矩形会呈现半透明效果,透过它可以看到下面的红色矩形。
第二个属性globalCompositionOperation表示后绘制的图形怎样与先绘制的图形结合。这个属性的值是字符串,可能的值如下:
- source-over(默认值):后绘制的图形位于先绘制的图形上方。
- source-in:后绘制的图形与先绘制的图形重叠的部分可见,两者其它部分完全透明。
- source-out:后绘制的图形与先绘制的图形不重叠的部分可见,先绘制的图形完全透明。
- source-atop:后绘制的图形与先绘制的图形重叠的部分可见,先绘制图形不受影响。
- destination-over:后绘制的图形位于先绘制的图形下方,只有之前透明像素下的部分才可见。
- destination-in:后绘制的图形位于先绘制的图形下方,两者不重叠的部分完全透明。
- destination-out:后绘制的图形擦除与先绘制的图形重叠的部分。
- destination-atop:后绘制的图形位于先绘制的图形下方,在两者不重叠的地方,先绘制的图形会变透明。
- lighter:后绘制的图形与先绘制的图形重叠部分的值相加,使该部分变亮。
- copy:后绘制的图形完全替代与之重叠的先绘制图形。
- xor:后绘制的图形与先绘制的图形重叠的部分执行“异或”操作。
var drawing = document.getElementById('drawing'); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var context = drawing.getContext("2d"); //绘制红色矩形 context.fillStyle = "#ff0000"; context.fillRect(10,10,50,50); //设置合成操作 context.globalCompositeOperation = "xor"; //绘制蓝色矩形 context.fillStyle = "rgba(0,0,255,1)"; context.fillRect(30,30,50,50); }
webGL
webGL是针对Canvas的3D上下文。与其它web技术不同,webGL并不是W3C指定的标准。而是由Khronos Group制定的。Khronos Group也设计了其他图像处理API,比如openGL ES2.0。浏览器使用的webGL就是基于openGL ES2.0制定的。
类型化数组
webGL涉及的复杂计算需要提前知道数值的精度,而标准的JavaScript数值无法满足需要。为此,webGL引入了一个概念,叫类型化数组(typed arrays)。类型化数组也是数组,只不过其元素被设置为特定类型的值。
类型化数组的核心就是一个名为ArrayBuffer的类型。每个ArrayBuffer对象表示的只是内存中指定的字节数,但不会指定这些字节用于保存什么类型的数据。通过ArrayBuffer所能做的,就是为了将来使用而分配一定数量的字节。例如,下面这行代码会在内存中分配20B。
var buffer = new ArrayBuffer(20);
创建了ArrayBuffer对象后,能够通过该对象获得的信息只有它包含的字节数,方法是访问其byteLength属性:
var bytes = buffer.byteLength;
虽然ArrayBuffer对象本身没有什么可说的,但对webGL而言,使用它是极其重要的。而且,在涉及视图的时候,你才会发现它原来还是很有意思的。
1.视图
使用ArrayBuffer(数组缓冲器类型) 的一种特别的方式就是用它来创建数组缓冲器视图。其中,最常见的视图是DataView,通过它可以选择ArrayBuffer的一小段字节。为此,可以在创建DataView实例的时候传入一个ArrayBuffer、一个可选的字节偏移量(从该字节开始选择)和一个可选的要选择的字节数。例如:
var buffer = new ArrayBuffer(20); //基于整个缓冲器创建一个新视图 var view = new DataView(buffer); //创建一个开始于字节9的新视图 var view = new DataView(buffer,9); //创建一个从字节9开始到字节18的新视图 var view = new DataView(buffer,9,10);
实例化后,DataView对象会把字节偏移量以及字节长度信息分别保存在byteOffset和byteLength属性中。
console.log(view.byteOffset); //9 console.log(view.byteLength); //10
读取和写入DataView的时候,要根据实际操作的数据类型,选择相应的getter和setter方法。下表列出了DataView支持的数据类型以及相应的读写方法。
| 数据类型 | getter | setter |
| 有符号8位整数 | getInt8(byteOffset) | setInt8(byteOffset,value) |
| 无符号8位整数 | getUint8(byteOffset) | setUint8(byteOffset,value) |
| 有符号16位整数 | getInt16(byteOffset,littleEndian) | setInt16(byteOffset,value,littleEndian) |
| 无符号16位整数 | getUint16(byteOffset,littleEndian) | setUint16(byteOffset,value,littleEndian) |
| 有符号32位整数 | getInt32(byteOffset,littleEndian) | setInt32(byteOffset,value,littleEndian) |
| 无符号32位整数 | getUint32(byteOffset,littleEndian) | setUint32(byteOffset,value,littleEndian) |
| 32位浮点数 | getFloat32(byteOffset,littleEndian) | setFloat32(byteOffset,value,littleEndian) |
| 64位浮点数 | getFloat64(byteOffset,littleEndian) | setFloat64(byteOffset,value,littleEndian) |
littleEndian:可选。如果为 false 或未定义,则应写入 big-endian 值;否则应写入 little-endian 值。详细了解《MSDN:DataView对象》
所有这些方法的第一个参数都是一个字节偏移量,表示要从哪个字节开始读取或者写入。不要忘了,要保存有些数据类型的数据,可能需要不止1B。比如,无符号8位整数要用1B,而32为浮点数则要用4B。使用DataView,就需要你自己来管理这些细节,即要明确自己的数据需要多少字节,并选择正确的读写方法。例如:
var buffer = new ArrayBuffer(20), view = new DataView(buffer), value; view.setUint16(0,25); view.setUint16(2,50); //不能从字节1开始,因为16位整数要用2B value = view.getUint16(0);
以上代码把两个无符号16位整数保存到了数组缓冲器中。因为每个16位整数要用2B,所以保存第一个数的字节偏移量为0,而保存第二个数的字节偏离量为2。
可以通过几种不同的方式来访问同一字节。例如:
var buffer = new ArrayBuffer(20), view = new DataView(buffer), value; view.setUint16(0,25); value = view.getInt8(0); console.log(value); //0
在这个例子中,数值25以16位无符号整数的形式被写入,字节偏移量为0。然后,再以8位有符号整数的方式读取该数据,得到的结果为0。这是因为25的二进制形式的前8位(第一个字节)全是0,如图所示:
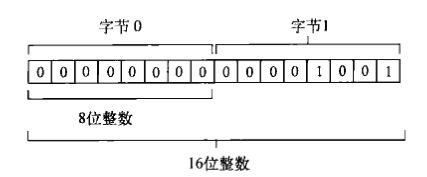
可见,虽然DataView能让我们在字节级别上读写数组缓冲器中的数据,但我们必须自己记住要将数据保存到哪里,需要占用多少字节。这样一来,就会带来很多工作量,因此,类型化视图也就应运而生。
2.类型化视图
类型化视图一般也被称为类型化数组,因为他们除了元素必须是某种特定的数据类型外,与常规的数组无异。类型化视图也分为几种,而且它们都继承了DataView。
- Int8Array:表示8位二补整数。
- Uint8Array:表示8位无符号整数。
- Int16Array:表示16位二补整数。
- Uint16Array:表示16位无符号整数。
- Int32Array:表示32位二补整数。
- Uint32Array:表示32位无符号整数。
- Float32Array:表示32位IEEE浮点值。
- Float64Array:表示64位IEEE浮点值。
每种视图类型都以不同的方式表示数据,而同一数据视选择的类型不同有可能占用一或多字节。例如,20B的ArrayBuffer可以保存20个Int8Array或Uint8Array,或者10个Int16Array或Uint16Array,或者5个Int32Array、Uint32Array或Float32Array,或者2个Float64Array。
由于这些视图都继承自DataView,因而可以使用相同的构造函数参数来实例化。第一个参数是要使用ArrayBuffer对象,第二个参数是作为起点的字节偏移量(默认为0),第三个参数是要包含的字节数。三个参数只有第一个是必须的。如下例子:
var buffer = new ArrayBuffer(200); //创建一个新数组,使用整个缓冲器 var int8s = new Int8Array(buffer); //只使用从字节10开始的缓冲器 var int16s = new Int16Array(buffer,10); //只使用从字节10到字节19的的缓冲器 var uint16s = new Uint16Array(buffer,10,10);
能够指定缓冲器中可用的字节段,意味着能在同一个缓冲器中保存不同类型的数值。比如,下面的代码就是在缓冲器的开头保存8位整数,而在其它字节中保存16位整数。
var buffer = new ArrayBuffer(32); //使用缓冲器的一部分保存8位整数另一部分保存在16位整数 var int8s = new Int8Array(buffer,0,11); var uint16s = new Uint16Array(buffer,12,10);
每个视图构造函数都有一个名为BYTES_PER_ELEMENT的属性,表示类型化数组的每个元素需要多少字节。因此,Uint8Array.BYTES_PER_ELEMENT就是1,而Float32Array.BYTES_PER_ELEMENT则为4。可以利用这个属性来辅助初始化。
var buffer = new ArrayBuffer(32); //需要11个元素空间 var int8s = new Int8Array(buffer,0,11*Int8Array.BYTES_PER_ELEMENT); //需要5个元素空间 var uint16s = new Uint16Array(buffer,int8s.byteOffset + int8s.byteLength + 1,5*Uint16Array.BYTES_PER_ELEMENT);
类型化视图的目的在于简化对二进制数据的操作。除了前面看到的优点之外,创建类型化视图还可以不用首先创建ArrayBuffer对象。只要传入希望数组保存的元素数,相应的构造函数就可以自动创建一个包含足够字节数的ArrayBuffer对象,例如:
//创建一个数组保存10个8位整数(10字节) var int8s = new Int8Array(10); //创建一个数组保存10个16位整数(20字节) var int16s = new Int16Array(10);
另外,也可以把常规数组转换为类型化视图,只要把常规数组传入到类型化视图的构造函数即可:
//创建一个数组保存5个8位整数(10字节) var int8s = new Int8Array([10,20,30,40,50]);
这是用默认值来初始化类型化视图的最佳方式,也是webGL项目中最常用的方式。
使用类型化视图时,可以通过length属性确定数组中有多少元素,如下:
//创建一个数组保存5个8位整数(10字节) var int8s = new Int8Array([10,20,30,40,50]); for(var i = 0,len = int8s.length; i < len; i++){ console.log("value at position" + i + " is " + int8s[i]); }
当然也可以使用方括号语法为类型化视图的元素赋值。如果为相应的元素指定字节数放不下相应的值,则实际保存的值是最大可能值的模。例如,无符号16位整数所能表示的最大数值是65535,如果你想保存65536,那实际保存的值是0;如果你想保存65537,那实际保存的值是1,依次类推。
var uint16s = new Uint16Array(10); uint16s[0] = 65537; console.log(uint16s[0]); //1
类型化视图还有一个方法subarray(),使用这个方法可以基于底层数组缓冲器的子集创建一个新视图。这个方法接收两个参数:开始元素的索引和可选的结束元素的索引。返回的类型与与调用该方法的视图类型相同。例如:
var uint16s = new Uint16Array(10), sub = uint16s.subarray(2,5); console.log(sub); //[0, 0, 0]
在以上代码中,sub也是Uint16Array的一个实例,而且底层与uint16s都基于同一个ArrayBuffer。
webGL上下文
目前,在支持的浏览器中,webGL的名字叫“experimental-webgl”,这是因为webGL的规范仍然未制定完成。制定完成后,这个名字就会变成简单的“webgl”。如果浏览器不支持webGL,取得上下文时会返回null。在使用webGL时,务必先检测一下返回值:
var drawing = document.getElementById("drawing"); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var gl = drawing.getContext("experimental-webgl"); if(gl){ //使用webGL } }
通过给getContext()传递第二个参数,可以为webGL上下文设置一些选项。这个参数本身是一个对象,可以包含下列属性。
- alpha:值为true,表示为上下文创建一个Alpha通道缓冲区;默认值为true。
- depth:值为true,表示可以使用16位深缓冲区;默认值为true。
- stencil:值为true,表示可以使用8位模板缓冲区;默认值为false。
- antialias:值为true,表示将使用默认机制执行抗锯齿操作;默认值为true。
- premultipliedAlpha:值为true,表示绘图缓冲区有预乘Alpha值;默认值为true。
- preserveDrawingBuffer:值为true,表示在绘图完成后保留绘图缓冲区;默认值为false。建议确实有必要的情况下再开启这个值,因为可能影响性能。
传递这个选项对象的方式如下:
var drawing = document.getElementById("drawing"); //确定浏览器支持<canvas>元素 if(drawing.getContext){ var gl = drawing.getContext("experimental-webgl",{alpha:false}); if(gl){ //使用webGL } }
大多数上下文选项只在高级技巧中使用。很多时候,各个选项的默认值就能满足我们的需求。
如果getContext()无法创建webGL上下文,最好把调用封装在try-catch块中,如下:
var drawing = document.getElementById("drawing"), gl; //确定浏览器支持<canvas>元素 if(drawing.getContext){ try{ gl = drawing.getContext("experimental-webgl"); }catch(ex){ //什么也不做 } if(gl){ //使用webGL }else{ alert("webGL context could not be created"); } }
1.常量
如果你属性openGL,那肯定会对各种操作中使用非常多的常量印象深刻。这些常量在openGL中都带前缀GL_。在webGL中,保存在上下文对象中的这些常量都没有GL_前缀。比如,GL_COLOR_BUFFER_BIT常量在webGL上下文就是gl.COLOR_BUFFER_BIT。webGL以这种方式支持大多数openGL常量(有一部分常量是不支持的)。
2.方法命名
openGL(以及webGL)中的很多方法都视图通过名字传达有关数据类型的信息。如果某种方法可以接收不同类型以及不同数量的参数,看方法名的后缀就可以知道。方法名的后缀会包含参数个数(1到4)和接收的数据类型(f表示浮点数,i表示整数)。例如,gl.uniform4f()意味着要接收4个浮点数,而gl.uniform3i()则表示要接收3个整数。
也有很多方法接收数组参数而非一个个单独的参数。这样的方法其名字中会包含字母v(即vector,矢量)。因此,gl.uniform3iv()可以接收一个包含3个值的整数数组。请大家记住以上命名约定,这样对理解后面关于webGL的讨论很有帮助。
3.准备绘图
在实际操作webGL上下文之前,一般都要使用某种实色清除<canvas>,为绘图做好准备。为此,首先必须使用clearColor()方法来指定要使用的颜色值,该方法接收4个参数:红、绿、蓝和透明度。每个参数必须是一个0到1之间的数值,表示每种分量在最终颜色中的强度,如下代码:
gl.clearColor(0,0,0,1); //black gl.clear(gl_COLOR_BUFFER_BIT);
以上代码把清理颜色缓冲区的值设置为黑色,然后调用clear()方法,这个方法与openGL中的glClear()等价。传入的参数gl_COLOR_BUFFER_BIT告诉webGL使用之前定义的颜色来填充相应区域。一般来说,都要先清理缓冲区,然后再执行其他绘图操作。
4.视口与坐标
开始绘图之前,通常要先定义webGL的视口(viewport)。默认情况下视图可以使用整个<canvas>区域。要改变视口大小,可以调用viewport()方法并传入4个参数:(视口相对于<canvas>元素的)x坐标、y坐标、宽度和高度。例如,下面的调用就使用了<canvas>元素:
gl.viewport(0,0,drawing.width,drawing.height);
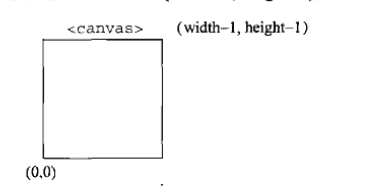
视口坐标与我们熟悉的网页坐标不一样。视口坐标的原点(0,0)在<canvas>元素的左下角,x轴和y轴的正方向分别是向右和向上,可以定义为(width-1,height-1),如下图所示:
知道怎么定义视口大小,就可以只在<canvas>元素的部分区域中绘图。如下例子:
//视口是<canvas>左下角的四分之一区域 gl.viewport(0,0,drawing.width/2,drawing.height/2); //视口是<canvas>左上角的四分之一区域 gl.viewport(0,drawing.height/2,drawing.width/2,drawing.height/2); //视口是<canvas>右下角的四分之一区域 gl.viewport(drawing.width/2,0,drawing.width/2,drawing.height/2);
另外,视图内部的坐标系与定义视口的坐标系也不一样。在视口内部,坐标原点(0,0)是视口的中心点,因此,视口左下角坐标为(-1,-1),而右上角坐标为(1,1)。如下图所示:

如果在视口内部绘图时使用视口外部的坐标,结果可能被视口剪切。比如,要绘制的形状有一个顶点在(1,2),那么该形状在视口右侧的部分会被剪切掉。
5.缓冲区
创建缓冲区:gl.createBuffer(),使用gl.bindBuffer()绑定到webGL上下文,gl.deleteBuffer()释放内存。
6.错误
webGL操作一般不会抛出错误,手工调用gl.getError()方法。
7.着色器
webGL有两种着色器:顶点着色器和片段(或像素)着色器。