论文笔记:SoundNet: Learning Sound Representations from Unlabeled Video
SoundNet: Learning Sound Representations from Unlabeled Video
Yusuf Aytar∗ Carl Vondrick∗ Antonio Torralba
2016 NIPS
这篇文章是顺着一维卷积相关的内容找过来的,主要是看一下模型实现。这篇文章要解决的问题是自然语音的表示问题,利用深度学习的方法。由于这个任务缺乏带有label的训练集合,所以作者用一些无标签的video进行训练,这种训练集很容易获得。We propose to scale up by capitalizing on the natural synchronization between vision and sound to learn an acoustic representation from unlabeled video.
网络结构如图所示:
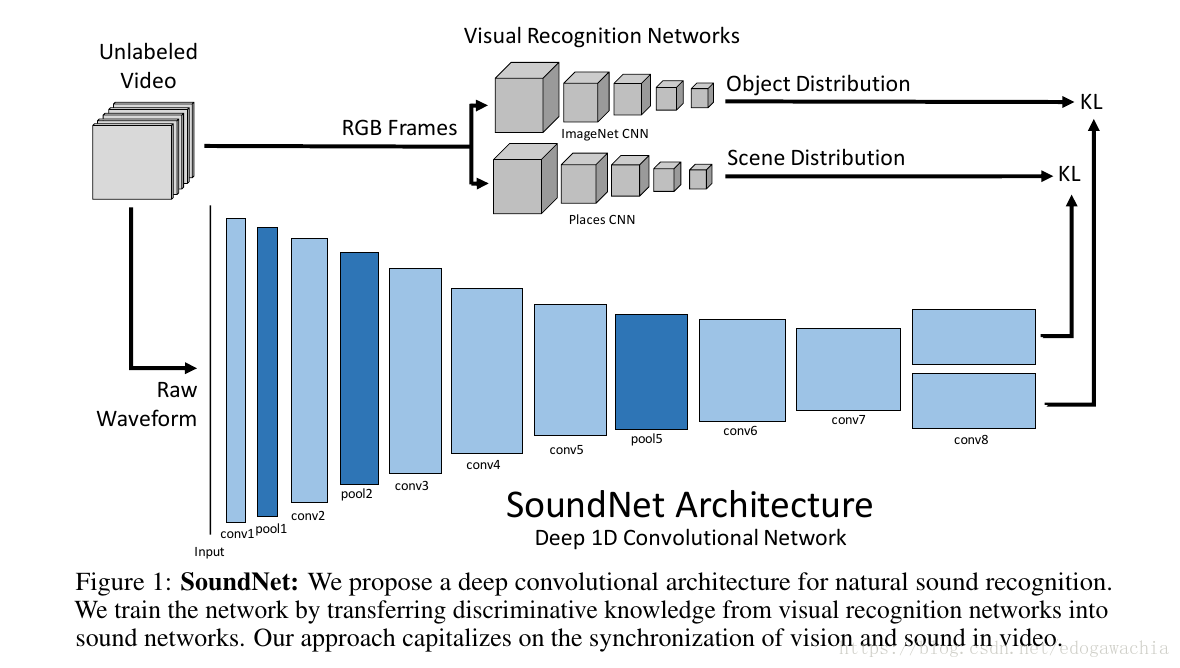
网络的配置情况configuration如下:

背景相关的就略过了。主要看一下模型:这里说语音也适用于conv net,因为语音信号的模式我们希望也是 translation invariant 的,并且conv还可以用来降低参数数量。而且,conv比全连接好,可以stack起来,并且认为后面的是higher level concepts。
另外需要注意的是,由于是conv1d,所以fm是二维的(而conv2d实际上是三维的,但是在tf中考虑batch_size放在第一维度所以是4d tensor)。那么为了适应变长度的输入,那么可以考虑做global pooling,和图像的conv2d想法一样,就是把当前的fm的尺寸的参数消除,都变成1(图像就是1×1),然后输出的实际上是一个vector,这时候这个vec的尺寸就只和设定的末层的filter 的个数一致了。
关于network depth的问题,由于这个实验中的dataset较大,所以可以设计的深一点,也能避免过拟合。
这里由于用的是video做输入,所以需要把scene和object的网络模型CNN迁移过来,作为reference,代替标签的作用。用KL散度度量loss。此处从略。
以上就是模型 SoundNet 的基本情况。
2018年05月11日23:52:23
在我们以前,“人生”已被反复了数千万遍,都像昙花泡影地倏现倏灭。 —— 漫画家,丰子恺