一、Spark Streaming的介绍
1. 流处理
流式处理(Stream Processing)。流式处理就是指源源不断的数据流过系统时,系统能够不停地连续计算。所以流式处理没有什么严格的时间限制,数据从进入系统到出来结果可能是需要一段时间。然而流式处理唯一的限制是系统长期来看的输出速率应当快于或至少等于输入速率。否则的话,数据岂不是会在系统中越积越多(不然数据哪去了)?如此,不管处理时是在内存、闪存还是硬盘,早晚都会空间耗尽的。就像雪崩效应,系统越来越慢,数据越积越多。
2、spark架构
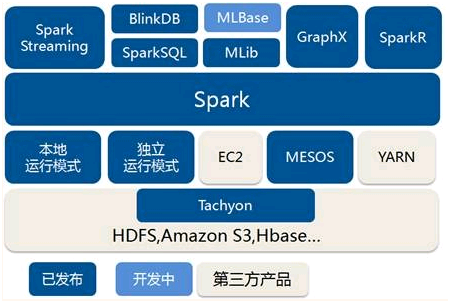
3、Spark Streaming特点
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
Spark Streaming的优势在于:
能运行在100+的结点上,并达到秒级延迟。
使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
能集成Spark的批处理和交互查询。
为实现复杂的算法提供和批处理类似的简单接口。
Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
4、程序流程
引入头文件
|
import org.apache.spark._
import org.apache.spark.streaming._
|
1. 创建StreamingContext对象 同Spark初始化需要创建SparkContext对象一样,使用Spark Streaming就需要创建StreamingContext对象。创建StreamingContext对象所需的参数与SparkContext基本一致,包括指明Master,设定名称(如NetworkWordCount)。需要注意的是参数Seconds(1),Spark Streaming需要指定处理数据的时间间隔,如上例所示的1s,那么Spark Streaming会以1s为时间窗口进行数据处理。此参数需要根据用户的需求和集群的处理能力进行适当的设置;
|
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf,
Seconds(1))
|
- 创建InputDStream Spark Streaming需要指明数据源。如上例所示的socketTextStream,Spark Streaming以socket连接作为数据源读取数据。当然Spark Streaming支持多种不同的数据源,包括Kafka、 Flume、HDFS/S3、Kinesis和Twitter等数据源;
|
val lines =
ssc.socketTextStream("10.2.5.3", 9999
|
- 操作DStream对于从数据源得到的DStream,用户可以在其基础上进行各种操作,如上例所示的操作就是一个典型的WordCount执行流程:对于当前时间窗口内从数据源得到的数据首先进行分割,然后利用Map和ReduceByKey方法进行计算,当然最后还有使用print()方法输出结果;
|
val words =
lines.flatMap(_.split(" "))
val pairs =
words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
|
- 启动Spark Streaming之前所作的所有步骤只是创建了执行流程,程序没有真正连接上数据源,也没有对数据进行任何操作,只是设定好了所有的执行计划,当ssc.start()启动后程序才真正进行所有预期的操作。
|
ssc.start()
ssc.awaitTermination()
|
5、单词统计例子
|
object Count
{
def main(args: Array[String]): Unit =
{
val conf = new
SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val
ssc = new StreamingContext(conf, Seconds(1))
val lines =
ssc.socketTextStream("10.2.5.3", 9999)
val words =
lines.flatMap(_.split(" "))
val pairs = words.map(word =>
(word, 1))
val wordCounts =
pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
|
二、SparkStreaming累加器及广播变量的使用
Spark Streaming的累加器和广播变量无法从checkpoint恢复。如果在应用中既使用到checkpoint又使用了累加器和广播变量的话,最好对累加器和广播变量做懒实例化操作,这样才可以使累加器和广播变量在driver失败重启时能够重新实例化。
定义累加器
|
Object DroppedWordsCounter {
@volatile private var instance:
LongAccumulator = null
def getInstance(sc: SparkContext):
LongAccumulator = {
if (instance == null) {
synchronized {
if (instance == null) {
instance =
sc.longAccumulator("WordsInBlacklistCounter")
}
}
}
instance
}
}
|
定义广播变量
|
object
WordBlacklist {
@volatile private var instance:
Broadcast[Seq[String]] = null
def getInstance(sc: SparkContext):
Broadcast[Seq[String]] = {
if (instance == null) {
synchronized{
if (instance == null) {
val wordBlacklist =
Seq("a", "b", "c")
instance =
sc.broadcast(wordBlacklist)
}
}
}
instance
}
}
|
删除重复的单词
|
object
RecoverableNetworkWordCount {
def createContext(ip: String, port:
Int, outputPath: String, checkpointDirectory: String)
: StreamingContext = {
println("Creating new
context")
val outputFile = new
File(outputPath)
if (outputFile.exists())
outputFile.delete()
val sparkConf = new
SparkConf().setAppName("RecoverableNetworkWordCount").setMaster("local[2]")
val ssc = new StreamingContext( sparkConf,
Seconds(120) )
ssc.checkpoint( checkpointDirectory
)
val lines =
ssc.socketTextStream(ip, port)
val words =
lines.flatMap(_.split(" "))
val wordCounts = words.map((_,
1)).reduceByKey(_ + _)
wordCounts.foreachRDD { (rdd:
RDD[(String, Int)], time: Time) =>
val blacklist =
WordBlacklist.getInstance(rdd.sparkContext)
val droppedWordsCounter =
DroppedWordsCounter.getInstance(rdd.sparkContext)
val counts = rdd.filter { case
(word, count) =>
if
(blacklist.value.contains(word)) {
droppedWordsCounter.add(count)
false
} else {
true
}
}.collect().mkString("[", ", ", "]")
val output = "Counts at time
" + time + " " + counts
println(output)
println("Dropped " +
droppedWordsCounter.value + " word(s) totally")
println("Appending to "
+ outputFile.getAbsolutePath)
Files.append(droppedWordsCounter.value + "
", outputFile,
Charset.defaultCharset())
}
ssc
}
|
主函数
|
def
main(args: Array[String]) {
val Array(ip, port,
checkpointDirectory, outputPath) =
Array("10.2.5.3","9999","E:\point","E:\out\test.txt")
val ssc =
StreamingContext.getOrCreate(checkpointDirectory,
() => createContext(ip,
port.toInt, outputPath, checkpointDirectory))
ssc.start()
ssc.awaitTermination()
}
|