学习曲线总是这样,简单样例“浅尝”。在从理论+实践慢慢攻破。理论永远是基础,切记“勿在浮沙筑高台”。
一. 核心架构
关于核心架构。在官方文档中阐述的非常清晰,地址:http://doc.scrapy.org/en/latest/topics/architecture.html。
英文有障碍可查看中文翻译文档。笔者也參与了Scraoy部分文档的翻译。我的翻译GitHub地址:https://github.com/younghz/scrapy_doc_chs。源repo地址:https://github.com/marchtea/scrapy_doc_chs。
以下就直接转载部分文档(地址:http://scrapy-chs.readthedocs.org/zh_CN/latest/topics/architecture.html):
概述
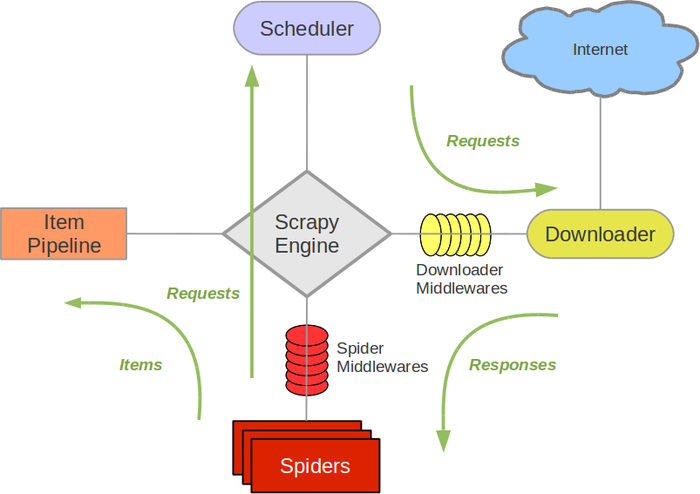
接下来的图表展现了Scrapy的架构,包含组件及在系统中发生的数据流的概览(绿色箭头所看到的)。以下对每一个组件都做了简介,并给出了具体内容的链接。
数据流例如以下所描写叙述。
Scrapy architecture
组件
Scrapy Engine
引擎负责控制数据流在系统中全部组件中流动,并在相应动作发生时触发事件。 具体内容查看以下的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。每一个spider负责处理一个特定(或一些)站点。 很多其它内容请看 Spiders 。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(比如存取到数据库中)。 很多其它内容查看 Item Pipeline 。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。其提供了一个简便的机制。通过插入自己定义代码来扩展Scrapy功能。很多其它内容请看 下载器中间件(Downloader Middleware) 。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook)。处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制。通过插入自己定义代码来扩展Scrapy功能。很多其它内容请看 Spider中间件(Middleware) 。
数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其步骤例如以下:
1.引擎打开一个站点(open a domain),找到处理该站点的Spider并向该spider请求第一个要爬取的URL(s)。
2.引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
3.引擎向调度器请求下一个要爬取的URL。
4.调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5.一旦页面完成下载。下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6.引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7.Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
8.引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
9.(从第二步)反复直到调度器中没有很多其它地request,引擎关闭该站点。
二. 数据流与代码执行分析
这里主要分析数据流部分并与代码结合起来。与上面的流程1-9相应。
(1)找spider——在spider目录下查找相关定义爬虫文件
(2)引擎获取URL——自己定义spider中start_urls列表中获取
(3)...
(4)...
(5)通过(3)(4)(5)就在内部实现了依据URL生成request。下载器依据request生成response这个过程。即URL-》request-》reponse。
(6)...
(7)在自己定义spider中调用默认的parse()方法或是制定的parse_*()方法处理接收到的reponse,处理的结果非常重要:
第一个,抽取item值。
第二个,假设须要继续爬取。这里会返回request给引擎。(这是“自己主动”爬取多个网页的关键)。
(8)(9)引擎继续调度。直至无request。
进阶:
Scrapy架构呈现星型拓扑结构。“引擎”作为整个架构的核心协调、控制整个系统的执行。
原创,转载注明:http://blog.csdn.net/u012150179/article/details/34441655