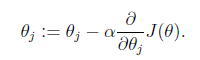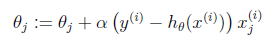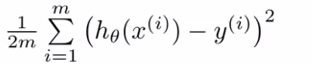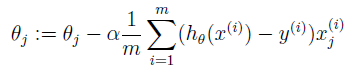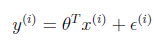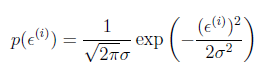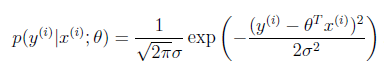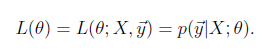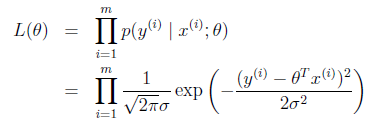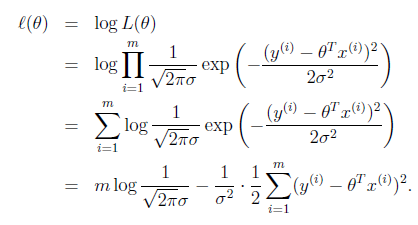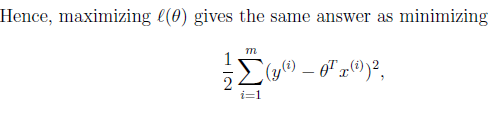版权声明:本文为博主原创文章,转载请注明出处。
https://blog.csdn.net/Dinosoft/article/details/34960693
前言
说到机器学习,非常多人推荐的学习资料就是斯坦福Andrew Ng的cs229。有相关的
视频 和
讲义 。只是好的资料
!= 好入门的资料,Andrew Ng在coursera有另外一个
机器学习课程 ,更适合入门。
课程有video,review questions和programing exercises,视频尽管没有中文字幕,只是看演示的讲义还是非常好理解的(假设当初大学里的课有这么好。我也不至于毕业后成为文盲。。)。最重要的就是里面的programing
exercises,得理解透才完毕得来的,毕竟不是简单点点鼠标的选择题。
只是coursera的课程屏蔽非常一些比較难的内容,假设认为课程不够过瘾。能够再看看cs229的。这篇笔记主要是參照cs229的课程。但也会穿插coursera的一些内容。
至于学习资料,周志华最新的《机器学习》西瓜书已经出了,肯定是首选!曾经的话我推荐《机器学习实战》,能解决你对机器学习怎么落地的困惑。李航的《统计学习方法》能够当提纲參考。cs229除了lecture notes。还有session notes(简直是雪中送炭。夏天送风扇,lecture notes里那些让你认为有必要再深入了解的点这里能够找到),和problem sets。假设细致读。资料也够多了。
线性回归 linear regression
通过现实生活中的样例。能够帮助理解和体会线性回归。 比方某日,某屌丝同事说买了房子,那一般大家关心的就是房子在哪。哪个小区,多少钱一平方这些信息,由于我们知道。这些信息是"关键信息”(机器学习里的黑话叫“feature”)。
那假设如今要你来评估一套二手房的价格(或者更直接点。你就是一个卖房子的黑中介,嘿嘿),假设你对房价一无所知(比方说房子是在非洲),那你肯定估算不准。最好就能提供同小区其它房子的报价。没有的话。旁边小区也行;再没有的话,所在区的房子均价也行;还是没有的话,所在城市房子均价也行(在北京有套房和在余杭有套房能一样么),由于你知道,这些信息是有“參考价值”的。其次,估算的时候我们肯定希望提供的信息能尽量详细,由于我们知道房子的朝向。装修好坏,位置(靠近马路还是小区中心)是会影响房子价格的。
事实上我们人脑在估算的过程,就相似一个“机器学习”的过程。
a)首先我们须要“训练数据”,也就是相关的房价数据,当然。数据太少肯定不行,要尽量丰富。
有了这些数据。人脑能够“学习”出房价的一个大体情况。由于我们知道同一小区的同一户型,一般价格是几乎相同的(特征相近。目标值-房价也是相近的。不然就没法预測了);房价我们一般按平方算,平方数和房价有“近似”线性的关系。
b)而“训练数据”里面要有啥信息?仅仅给你房子照片肯定不行。肯定是要小区地点。房子大小等等这些关键“特征”
c)一般我们人肉估算的时候,比較任意,也就估个大概。不会算到小数点后几位;而估算的时候,我们会參照现有数据,不会让估算跟“训练数据”差得离谱(也就是以下要讲的让损失函数尽量小),不然还要“训练数据”干嘛。 计算机擅好处理数值计算。把房价估算问题全然能够用数学方法来做。把这里的“人肉估算”数学形式化,也就是“线性回归”。
1.我们定义线性回归函数(linear regression)为:
然后用h(x) 来预測y
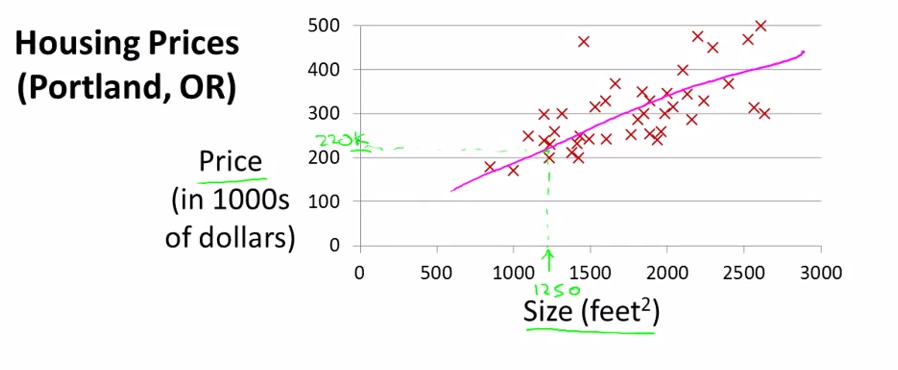
最简单的样例,一个特征size,y是Price,把训练数据画在图上,例如以下图。(举最简单的样例仅仅是帮助理解,当特征仅仅有一维的时候。画出来是一条直线。多维的时候就是超平面了)
这里有一个问题,假设真实模型不是线性的怎么办?所以套用线性回归的时候是须要预判的。不然训练出来的效果肯定不行。这里不必过于深究,后面也会介绍怎么通过预处理数据处理非线性的情况。
2.目标就是画一条直线尽量靠近这些点。用数学语言来描写叙述就是cost function尽量小。
为什么是平方和? 直接相减取一下绝对值不行么, | h(x)-y | ? (后面的Probabilistic interpretation会解释。这样求出来的是likelihood最大。另外一个问题。 | h(x)-y |大的时候 ( h(x)-y )^2 不也是一样增大,看上去好像也一样?!
除了后者是凸函数,好求解,所以就用平方和? 不是的,单独一个样本纵向比較确实一样,但别漏了式子前面另一个求和符号,这两者的差异体如今样本横向比較的时候,比方如今有两组差值,每组两个样本,第一组绝对值差是1,3,第二组是2,2,绝对值差求和是一样,4=4。
算平方差就不一样了,10 > 8。事实上,x^2求导是2x,这里的意思就是惩处随偏差值线性增大,终于的效果从图上看就是尽可能让直线靠近全部点)
3 然后就是怎么求解了。
假设h(x)=y那就是初中时候的多元一次方程组了,如今不是。所以要用高端一点的方法。
曾经初中、高中课本也有提到怎么求解回归方程,都是按计算器。难怪我一点印象都没有。囧。
。
还以为失忆了
notes 1里面介绍3种方法
1.gradient descent (梯度下降)
a.batch gradient descent
b.stochastic gradient descent (上面的变形)
3.Newton method(Fisher scoring)
1.gradient descent algorithm
α is called the learning rate.
仅仅有一个训练数据的样例:
这个式子直观上也非常好理解,假设xj是正数。y比预測值h(x)大的话,我们要加大θ,所以α前面是+号(当xj是负数同理)
举一个数据的样例仅仅是帮助我们理解,实际中是会有多个数据的,你会体会到矩阵的便利性的。
上面的式子在详细更新的时候有小的不同
方法 a.batch gradient descent
注意,要同一时候进行更新。由于更新θ(j+1)的时候要用hθ(x),这里的hθ(x)用的还是老的θ1 到 θj。
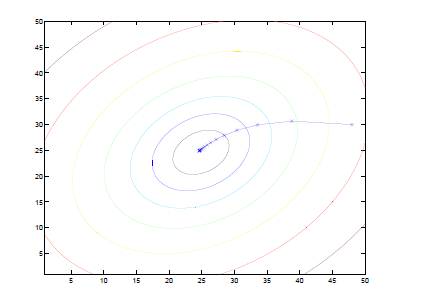
直观上看,等高线代表cost function的值,横纵坐标是θ1 θ2两个參数。梯度下降就是每次一小步沿着垂直等高线的方向往等高线低(图的中心)的地方走。
显然步子不能太大,不然easy扯着蛋(跨一大步之后反而到了更高的点)
方法 b.stochastic gradient descent (also incremental gradient descent)
这两种方法看公式可能不好理解。看后面的代码实现就easy区分。
2.the normal equations。
刚開始学习的人能够先跳过推导过程(不是鼓舞不看。),直接先记住结论
。
(在线性代数的复习课件cs229-linalg会说明。这个式子事实上是把y投影到X)
3.牛顿法
Another algorithm for maximizing ℓ(θ)
Returning to logistic regression with g(z) being the sigmoid function, lets now talk about a different algorithm for minimizing -ℓ(θ)。(感觉notes1里面少了个负号)
牛顿法求函数0点。即 f (Θ) = 0
这样迭代即可,f′(θ)是斜率,从图上看,就是“用三角形去拟合曲线。找0点”
由于我们是要求导数等于0。把上面的式子替换一下f(θ) = ℓ′(θ)
θ是多维的。有
where
When Newton’s method is applied to maximize the logistic regression log likelihood function ℓ(θ), the resulting method is also called Fisher scoring.
coursera的课件提到其它方法,预计刚開始学习的人没空深究,了解一下有这些东西就好。
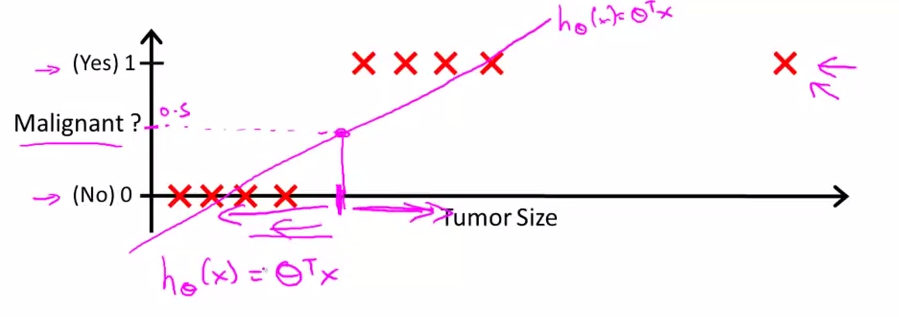
逻辑回归logistic regression
如今假设有一个0和1的2分类问题的。套进去线性回归去解,例如以下图
离群点会对结果影响非常大,比方上图(我们以h(x)>0.5时预測y=1。一个离群点让直线大旋转。一下子把不少点误分类了)(coursera的课程仅仅提到这个原因,但貌似不止),并且另一个问题,Intuitively, it also doesn’t make sense for h(x) to take values larger than 1 or smaller than 0 when we know that
y ∈ {0, 1}. (那h(x)在[0,1]又代表什么呢?呵呵)
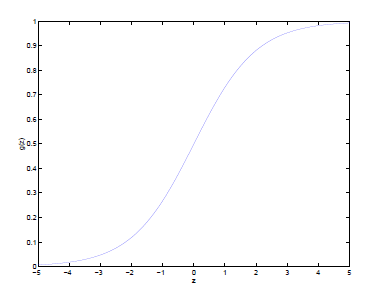
换成这个曲线就好多了,这个函数是sigmoid function
g(z) 值域 (0,1)
把线性回归套进去g(z)就是
为什么是sigmoid函数?换个形状相似的函数不行么?这个后面一样有概率解释的。
注意,这个函数输出值代表“y为1的概率”,再回过头看看,前面y用1和0来表示正反也是有讲究的(讲svn的时候又换成+1。-1),直观上看sigmoid越接近1表示1的概率大,接近0表示0的概率大,另一个好处就是以下算likelihood的时候用式子好表示。
建模好,还缺一个cost function,是不是跟linear regression一样求平方差即可?
呵呵。不是。coursera课程给出的原因是套入sigmoid后,这个函数不是凸函数。不好求解了。但事实上h(x) -y 算出来是一个概率。多个训练数据的概率相加是没意义的。得相乘。
p(x,y) = p(x)* p(y)。
先讲一个useful property
推导公式时能够用,
习题也会用到的
把两个概率公式合到一起
=>
likelihood of the parameters:
一个训练数据的时候(代入前面的结论
)
注意,前面linear regression,我们求cost function的最小值。所以是减号 对于logistic regression。我们要求的是likelihood最大(附录提到,是等价的),所以要换成加号。这样θ终于的迭代式子才跟前面linear regression一样,这是巧合么?隐隐约约感觉这当中有一腿。
machine learning in practice
我总认为计算机科学动手实践非常重要,纸上谈兵不接地气。coursera有programing exercise,必须完毕下。octave用起来挺爽的。
这里记录一下关键点。
1.coursera的cost function多除了一个m
事实上起到一个归一化的作用,让迭代步长α与训练样本数无关(你能够当作α=α'/m)
2.batch gradient descent和stochastic gradient descent的区别
batch gradient descent
for iter = 1:num_iters
A = ( X * theta - y )';
theta = theta - 1/m * alpha * ( A * X )';
end
stochastic gradient descent
for iter = 1:num_iters
A = ( X * theta - y )';
for j = 1:m
theta = theta - alpha * ( A(1, j) * X(j, :) )';
end
end
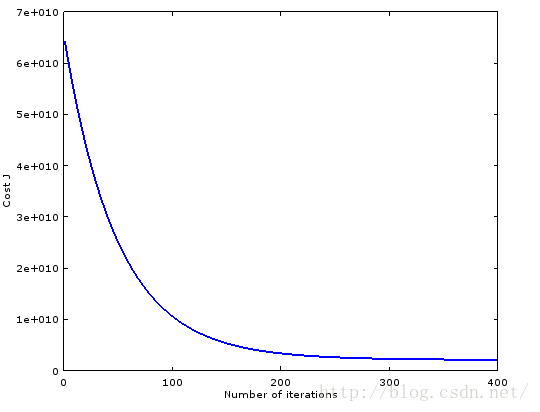
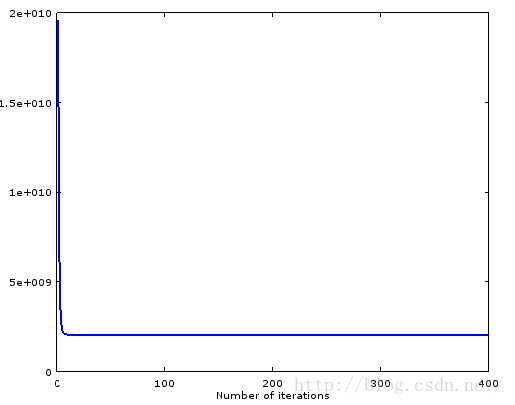
用ex1_multi.m改改,生成两个cost下降图。能够发现stochastic gradient descent挺犀利的。
。
3.feature scaling的作用是啥?
(详细模型详细分析,这里仅仅针对LR模型,不要把结论任意推广) coursera提到的作用是加速收敛。那会影响结果么?直觉上,把一个feature扩大10倍,那算cost function的时候岂不是非常占廉价。算出来的权重会偏向这个feature么?
对这样的问题,数学家会理论证明,project师做实验验证,我习惯粗略证明,然后实验验证自己对不正确。
(以下都是粗略的想法,不是严谨证明。!
)假设每一个样本的feature j 乘以10,那算出来的θj除以10不就结果跟原来一样了?我猜不会影响。看一下我们迭代时候的式子
xj变大,h(x) 也变大,粗略迭代步长要扩大10倍(那就起到抑制θ的作用)但终于的θ要变为1/10。想想略蛋疼,比方如今100每次降低1,减99次后变为1,如今每次要降低10。却要让终于的结果到0.1,得改α才行啊。看来feature scaling能起到归一化α的作用。
把ex1.m改一下。做做实验。
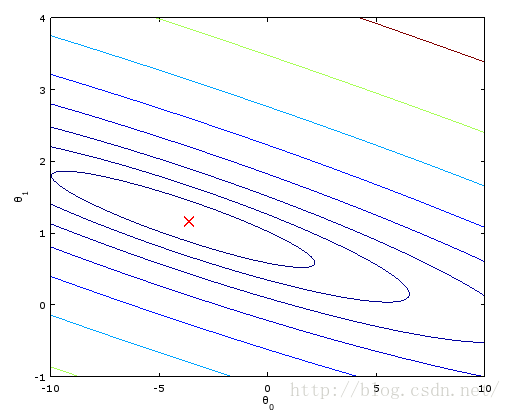
会发现缩放一个feature后,收敛非常困难啊,我仅仅乘以2,原来的代码就输出NaN了。
。我把alpha平方一下 alpha^2。
能够发现等高线变密集了,椭圆形变得非常扁,所以步长不能非常大,收敛非常困难。一直在一个相似直线的椭圆跳来跳去慢慢挪。至于结果会不会变。用normal equation来验证,由于梯度下降有困难。
改下ex1_muliti.m
X2 = X;
X2(:,2) = X2(:, 2)* 2;
theta2 = pinv(X2' * X2) * X2' * y;
theta2
theta
theta2 =
8.9598e+004
6.9605e+001
-8.7380e+003
theta =
8.9598e+004
1.3921e+002
-8.7380e+003
前面是linear regression,对logistic regression能够改ex2.m也验证下
X2(:,2)= X2(:,2)*2;
[theta2, cost] = fminunc(@(t)(costFunction(t, X2, y)), initial_theta, options);
theta2theta:
-25.161272
0.206233
0.201470
theta2 =
-25.16127
0.10312
0.20147
附录
cost function的概率解释
我们知道h(x)和真实的y是有偏差的,设偏差是ε
假设ε是iid(独立同分布)的。符合高斯分布(通常高斯分布是合理的,详细不解释),联想到高斯分布的式子。有平方就不奇怪了。
得到
likelihood function:
求解技巧,转成 log likelihood ℓ(θ)(这个是个非常基础的技巧,后面会大量用到) :
To summarize: Under the previous probabilistic assumptions on the data,
least-squares regression corresponds to finding the maximum likelihood esti mate of θ.
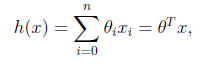
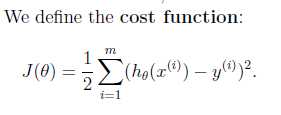
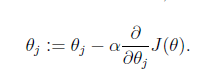
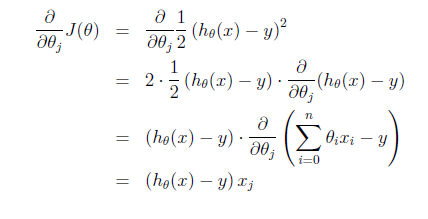
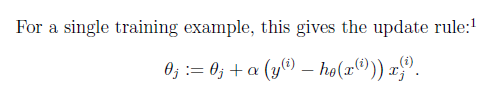
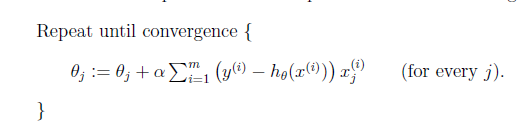
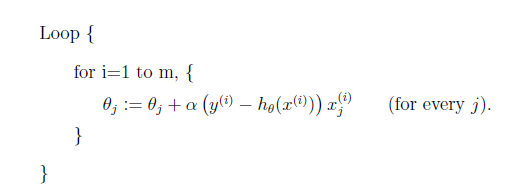
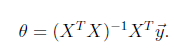 。
。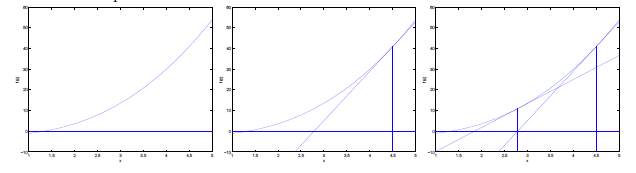
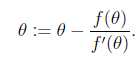 这样迭代即可,f′(θ)是斜率,从图上看,就是“用三角形去拟合曲线。找0点”
这样迭代即可,f′(θ)是斜率,从图上看,就是“用三角形去拟合曲线。找0点”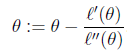
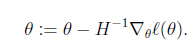
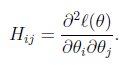

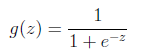 g(z) 值域 (0,1)
g(z) 值域 (0,1)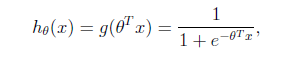
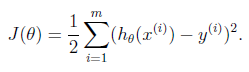 呵呵。不是。coursera课程给出的原因是套入sigmoid后,这个函数不是凸函数。不好求解了。但事实上h(x) -y 算出来是一个概率。多个训练数据的概率相加是没意义的。得相乘。
呵呵。不是。coursera课程给出的原因是套入sigmoid后,这个函数不是凸函数。不好求解了。但事实上h(x) -y 算出来是一个概率。多个训练数据的概率相加是没意义的。得相乘。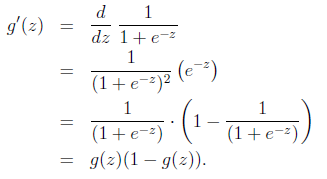 推导公式时能够用,习题也会用到的
推导公式时能够用,习题也会用到的 =>
=> 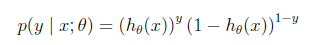
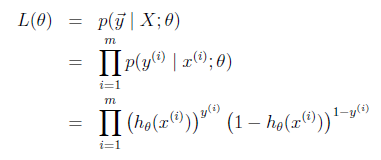
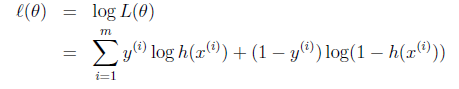
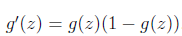 )
)