enmmm,今天困在了如何对知乎进行下拉操作上了,虽然可以用selenium操作,但我还不是很熟悉这个东西。。。。
首先啊,根据要求创建了数据库

首先,在知乎等网站进行初步爬取,
分析知乎的网页结构:
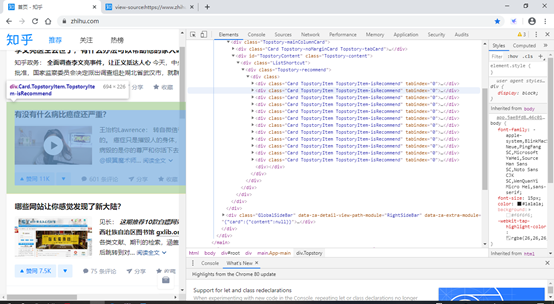
就是这里了,下面来整理具体位置:page.getHtml().xpath("//div[@class=Card]/div[@class=List-item]/div[@class=ContentItem]/h2/a/@href")
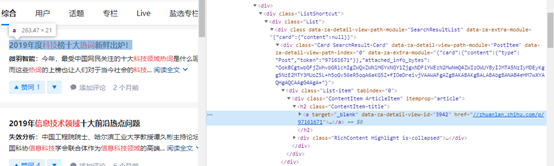
得到初步想要的结果:

经检验页面是对的。
下一步就是模拟下拉刷新,并获取更多的页面。(这一步好难啊。。。。正在查找相关视频和前辈的经验,但奈何用webmagic写爬虫的人实在是太稀缺了,我都想放弃改写python了。)
在下一步是进入详细页面对页面进行分词解析,
首先要把页面的内容下载下来(这一步是比较简单,但还没写)
其次进行数据分析,就是自动分词,以及这些;
