Hive是Hadoop的常用工具之一,Hive查询语言(HiveQL)的语法和SQL类似,基本实现了SQL-92标准。
1. 表的建立
编写以下的文件:
USE test; DROP TABLE IF EXISTS student2; CREATE TABLE student2( id INT, name STRING, age INT, course ARRAY<STRING>, body MAP<STRING,FLOAT>, address STRUCT<street:STRING,number:INT> ) PARTITIONED BY (state STRING,city STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY ':' LINES TERMINATED BY ' ' STORED AS TEXTFILE;
保存为test.hql,该文件指定了表的结构和分隔符。Hive的数据类型除了INT、STRING、FLOAT等基本类型以外,还有三种复杂数据类型:STRUCT、MAP和ARRAY。PARTITIONED BY()指定了表的分区字段,分区字段只能出现一次,否则会出错。ROW FORMAT DELIMITED指定了各种分隔符。最后指定了文件存储格式为TEXTFILE。
在Linux终端里输入如下命令:
hive -f test.hql
该命令执行了test.hql文件,创建了表student2(前提是test数据库已经被创建)。可以进入hive,输入
desc student2;
命令查看该表的结构:

2. 从文件导入数据
在Linux中创建一个文本文件,保存为/home/hadoop/student2:
1 Tom 20 Chinese,Maths,English Height:165,Weight:80 South Street,101 Sichuan Chengdu
2 Mike 25 Chinese,Maths,English,Computer Science Height:175,Weight:70 North Street,105 Sichuan Chengdu
3 Peter 26 Java,Hadoop Height:168,Weight:68 East Street,12 Sichuan Chengdu
在Hive中输入以下命令将该文件里面的数据导入student2:
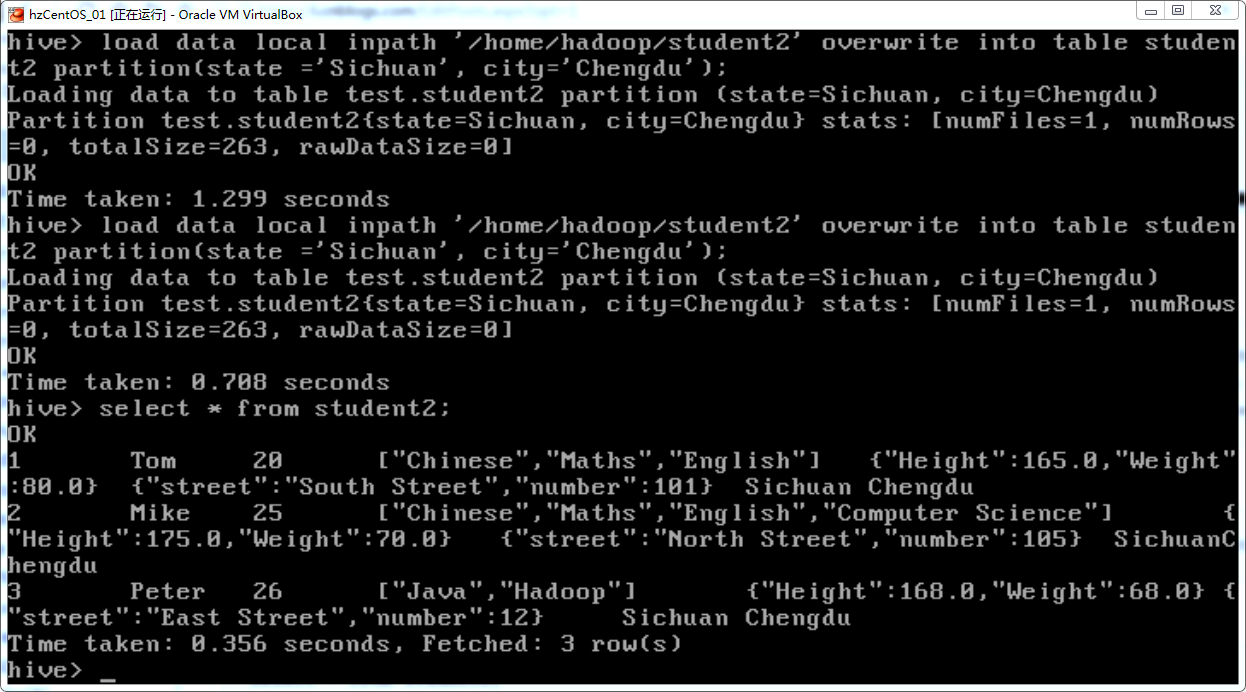
load data local inpath '/home/hadoop/student2' overwrite into table student2 partition(state='Sichuan', city='Chengdu');
overwrite表示将以前的数据覆盖,local表示是从本地文件导入,如果没有写local,则表示从HDFS文件导入。如果文本文件里面没有写最后面的Sichuan和Chengdu,导入数据时会自动把这两个字段分别设置为Sichuan和Chengdu,因为在partition中已经指定了Sichuan和Chengdu。
执行命令:
select * from student2;
可见数据已经被导入表student2:
3. 通过查询语句导入数据
新建一张表student3,结构和student3一致,然后输入命令:
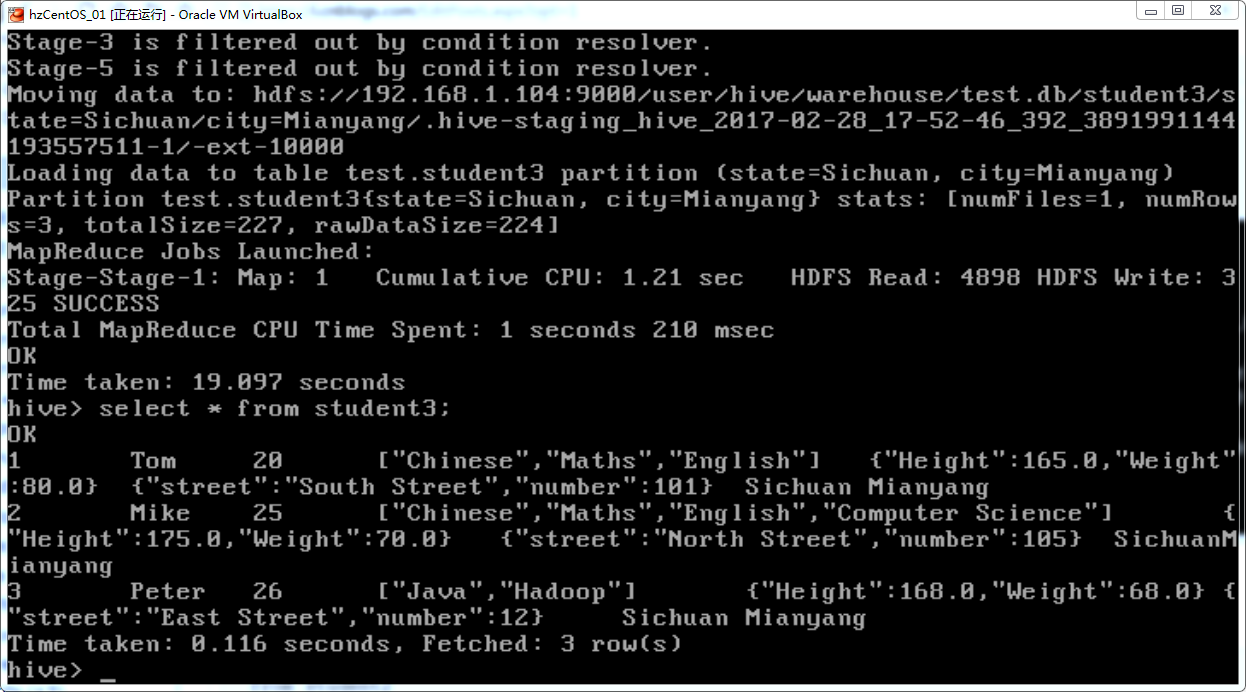
from student2
insert overwrite table student3 partition(state='Sichuan', city='Chengdu') select id,name,age,course,body,address;
该命令将student2中的数据导入到student3。注意select后面不能写"*",否则会出错,只能写除了分区字段以外的其他字段。查看student3,可见数据已经被导入:
4. 数据的导出
输入命令:
insert overwrite local directory '/home/hadoop/hive1' select * from student2;
将数据导出到本地文件。先新建了一个hive1文件夹,然后将数据导入到hive1文件夹里面的000000_0文件。