参考
https://juejin.im/post/5d837cd1e51d4561cb5ddf66#heading-22
https://github.com/markzhai/AndroidPerformanceMonitor
http://blog.zhaiyifan.cn/2016/01/16/BlockCanaryTransparentPerformanceMonitor/
基于消息队列替换 Looper 的 Printer
Looper 暴露了一个方法
public void setMessageLogging(@Nullable Printer printer) { mLogging = printer; }
在Looper 的loop方法有这样一段代码
public static void loop() { ... for (;;) { ... // This must be in a local variable, in case a UI event sets the logger Printer logging = me.mLogging; if (logging != null) { logging.println(">>>>> Dispatching to " + msg.target + " " + msg.callback + ": " + msg.what); } msg.target.dispatchMessage(msg); if (logging != null) { logging.println("<<<<< Finished to " + msg.target + " " + msg.callback); } ... } }
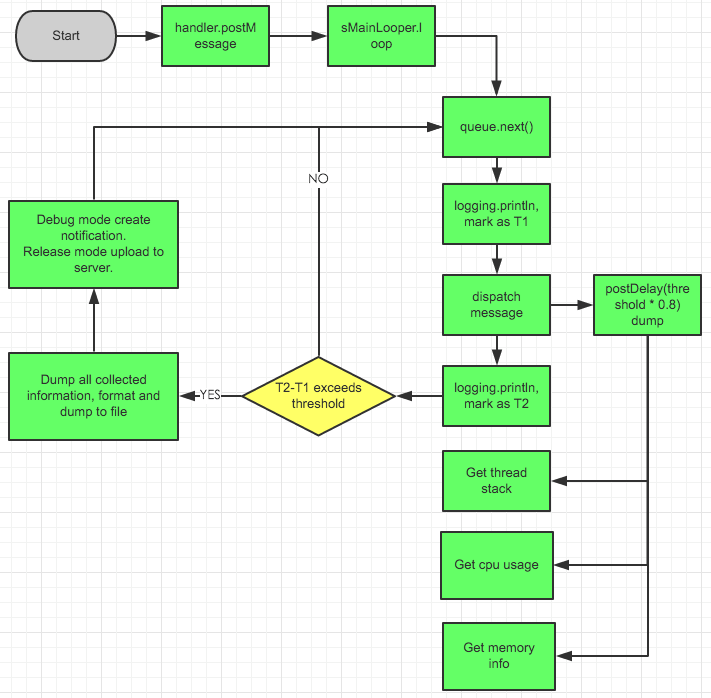
Looper轮循的时候,Printer 在每个message处理的前后被调用 logging.println,我们可以通过设置Printer,计算Looper两次获取消息的时间差,如果时间太长就说明Handler处理时间过长,直接把堆栈信息打印出来,就可以定位到耗时代码。不过println 方法参数涉及到字符串拼接,考虑性能问题,所以这种方式只推荐在Debug模式下使用。
BlockCanary
基于此原理的开源库代表是:BlockCanary,
取名为BlockCanary则是为了向LeakCanary致敬,顺便本库的UI部分是从LeakCanary改来的,之后可能会做一些调整。
看下BlockCanary核心代码:
类:LooperMonitor
public void println(String x) { if (mStopWhenDebugging && Debug.isDebuggerConnected()) { return; } if (!mPrintingStarted) { //1、记录第一次执行时间,mStartTimestamp mStartTimestamp = System.currentTimeMillis(); mStartThreadTimestamp = SystemClock.currentThreadTimeMillis(); mPrintingStarted = true; startDump(); //2、开始dump堆栈信息 } else { //3、第二次就进来这里了,调用isBlock 判断是否卡顿 final long endTime = System.currentTimeMillis(); mPrintingStarted = false; if (isBlock(endTime)) { notifyBlockEvent(endTime); } stopDump(); //4、结束dump堆栈信息 } } //判断是否卡顿的代码很简单,跟上次处理消息时间比较,比如大于3秒,就认为卡顿了 private boolean isBlock(long endTime) { return endTime - mStartTimestamp > mBlockThresholdMillis; }
原理是这样,比较Looper两次处理消息的时间差,比如大于3秒,就认为卡顿了。
细节的话大家可以自己去研究源码。
比如消息队列只有一条消息,隔了很久才有消息入队,这种情况应该是要处理的,BlockCanary是怎么处理的呢?
在Android开发高手课中张绍文说过微信内部的基于消息队列的监控方案有缺陷:

这个我在BlockCanary 中测试,并没有出现此问题,所以BlockCanary 是怎么处理的?简单分析一下源码:
上面这段代码,注释1和注释2,记录第一次处理的时间,同时调用startDump()方法,startDump()最终会通过Handler 去执行一个AbstractSampler 类的mRunnable,代码如下:
abstract class AbstractSampler { private static final int DEFAULT_SAMPLE_INTERVAL = 300; protected AtomicBoolean mShouldSample = new AtomicBoolean(false); protected long mSampleInterval; private Runnable mRunnable = new Runnable() { @Override public void run() { doSample(); //调用startDump 的时候设置true了,stop时设置false if (mShouldSample.get()) { HandlerThreadFactory.getTimerThreadHandler() .postDelayed(mRunnable, mSampleInterval); } } };
可以看到,调用doSample之后又通过Handler执行mRunnable,等于是循环调用mRunnable,直到stopDump被调用。
AbstractSampler 方法有两个类实现,StackSampler和CpuSampler,分析堆栈就看StackSampler的doSample方法
protected void doSample() { StringBuilder stringBuilder = new StringBuilder(); // 获取堆栈信息 for (StackTraceElement stackTraceElement : mCurrentThread.getStackTrace()) { stringBuilder .append(stackTraceElement.toString()) .append(BlockInfo.SEPARATOR); } synchronized (sStackMap) { // LinkedHashMap中数据超过100个就remove掉链表最前面的 if (sStackMap.size() == mMaxEntryCount && mMaxEntryCount > 0) { sStackMap.remove(sStackMap.keySet().iterator().next()); } //放入LinkedHashMap,时间作为key,value是堆栈信息 sStackMap.put(System.currentTimeMillis(), stringBuilder.toString()); } }
所以,BlockCanary 能做到连续调用几个方法也能准确揪出耗时是哪个方法,是采用开启循环去获取堆栈信息并保存到LinkedHashMap的方式,避免出现误判或者漏判。核心代码就先分析到这里,其它细节大家可以自己去看源码。