中文分词插件很多,当然都有各自的优缺点,近日刚接触自然语言处理这方面的,初步体验中文分词。
首先感谢harry.guo楼主提供的学习资源,博文链接http://www.cnblogs.com/harryguo/archive/2007/09/26/906965.html,在此基础上进行深入学习和探讨。
接下来进入正文。。。大牛路过别喷,菜鸟有空练练手~~完整的项目源码下载在文章末尾~~
因为是在Lucene.Net下进行中文分词解析器编写的,新建项目Lucene.China,然后将Lucene.Net.dll添加到项目中。(附:资源Lucene.Net.rar)
与英文不同,中文词之间没有空格,于是对于中文分词就比英文复杂了些。
第一,构建树形词库,在所建项目目录下的bin/Debug文件下新建一个文件夹data(如果文件夹已经存在,则不用新建),然后在data文件夹中加入sDict.txt。
(附:资源sDict.rar,解压后得到是sDict.txt文档,放入指定文件夹中)
构建树形词库实现代码如下:
 WordTree.cs
WordTree.cs第二,构建一个支持中文的分析器,
需要停用词表 :String[] CHINESE_ENGLISH_STOP_WORDS,下面代码只是构造了个简单的停用词表。 (附资源:相对完整的停用词表stopwords.rar)
具体实现代码如下:
ChineseAnalyzer.cs第三,进行文本切分,文本切分的基本方法:输入字符串,然后返回一个词序列,然后把词封装成Token对象。
当然,要判断将要进行切分的词是中文、英文、数字还是其他。
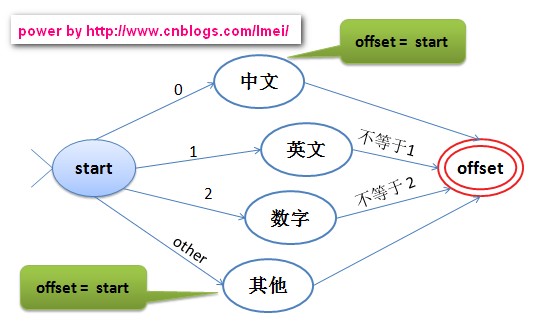
实现源码如下:
ChineseTokenizer.cs第四,编写测试demo的main函数,代码如下:
Program.cs控制器输出显示:

可见被测试的文本为红色框里面所示。
测试结果:
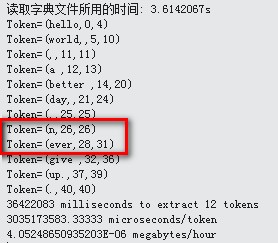
问题出现了,never被拆分成n,ever。于是测试多几次,发现只要是n开头的单词,n都会被拆开,如nnno,会变成n,n,n,o。
那么为什么会这样呢?
回想一下,之前我们构建了字典树。其实一般情况下我们会觉得说中文分析器所需要构建的字典树,当然就是纯文字,但是其实不是这样的。
打开sDict.txt文件,会发现下面这些词语:
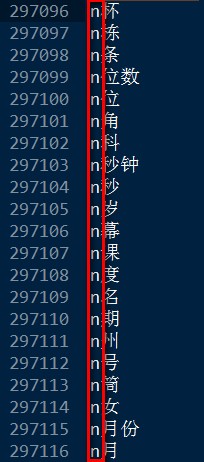
发现问题了吧!!!其实是包含字母的,所以英文单词的n总会被单独切分出来。
那么应该怎么解决呢??
解决方法,就是在sDict.txt文件中加入以n开头的单词表,这样就可以完美切分啦!!
测试一下吧!在文件中加入单词never,如下:
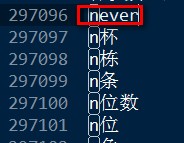
测试结果:
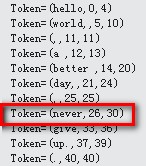
可见单词never已经完美切除。
接下来再来看另外一个在测试过程出现的问题,
测试文本如下:‘开’和‘始’中间有空格,且这段文本最后没有标点和空格。

测试结果如下:

依然完美切分,而且没有报错提示。
然后继续测试英文文本,如下:依然留空格,然后文本末尾没有空格跟标点。
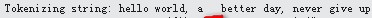
测试结果:出现异常

问题产生的原因是,英文是一个或多个单词相连的,如never,在判断第一个字母是属于英文的时候,会自动继续判断下一个,
当刚好这个单词是最后一个的时候,它依然会去查找下一个是否还是属于英文单词,这样文本要是以英文结束,且后面没有空格跟标点的话,
它就会出现超出索引的错误。
出现问题的代码是下面这句:在ChineseTokenizer.cs中
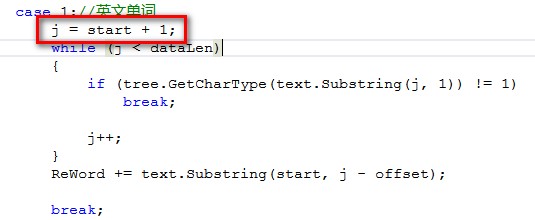
注:由于数字的切分和英文的切分采用的方法相同,所以也会出现同样问题
解决方法:就是在测试的文档的最后加上一个空格。因为空格不会影响到切分,所以只要把要切分的文本都进行事先处理,在文本末尾加多个空格给它,这样就不会出现上面异常。
懒人大礼包^_^
如果你不想进行上面那些多步骤,也是可以的。
第一,还是要把sDict.txt文件放到项目目录/bin/Debug/data文件夾中;
第二,下载Lucene.Fanswo.rar和Lucene.Net.rar,然后将Lucene.Fanswo.dll和Lucene.Net.dll添加到项目中;
注:Lucene.Fanswo.dll实现的功能跟上面写的一样,直接调用就行。
第三,编写Programs.cs测试代码
关键语句:
using Lucene.Fanswo;
创建支持中文的分析器,
Analyzer analyzer = new Lucene.Fanswo.ChineseAnalyzer();
完整代码如下:
Program.cs测试过程中会发现如上问题,解决方法也是按上面的方式解决。
最后,附上完整测试demo项目源码下载,Lucene.China.rar
注:如果是下载项目源码,运行后发现有个空白窗体弹出,不要理它,关注控制台的输出。
@_@|| 终于写完了!!! ~_~zzZ