Perf 简介
Perf 是用来进行软件性能分析的工具。
通过它,应用程序可以利用 PMU,tracepoint 和内核中的特殊计数器来进行性能统计。它不但可以分析指定应用程序的性能问题 (per thread),也可以用来分析内核的性能问题,当然也可以同时分析应用代码和内核,从而全面理解应用程序中的性能瓶颈。
最初的时候,它叫做 Performance counter,在 2.6.31 中第一次亮相。此后他成为内核开发最为活跃的一个领域。在 2.6.32 中它正式改名为 Performance Event,因为 perf 已不再仅仅作为 PMU 的抽象,而是能够处理所有的性能相关的事件。
使用 perf,您可以分析程序运行期间发生的硬件事件,比如 instructions retired ,processor clock cycles 等;您也可以分析软件事件,比如 Page Fault 和进程切换。
这使得 Perf 拥有了众多的性能分析能力,举例来说,使用 Perf 可以计算每个时钟周期内的指令数,称为 IPC,IPC 偏低表明代码没有很好地利用 CPU。Perf 还可以对程序进行函数级别的采样,从而了解程序的性能瓶颈究竟在哪里等等。Perf 还可以替代 strace,可以添加动态内核 probe 点,还可以做 benchmark 衡量调度器的好坏
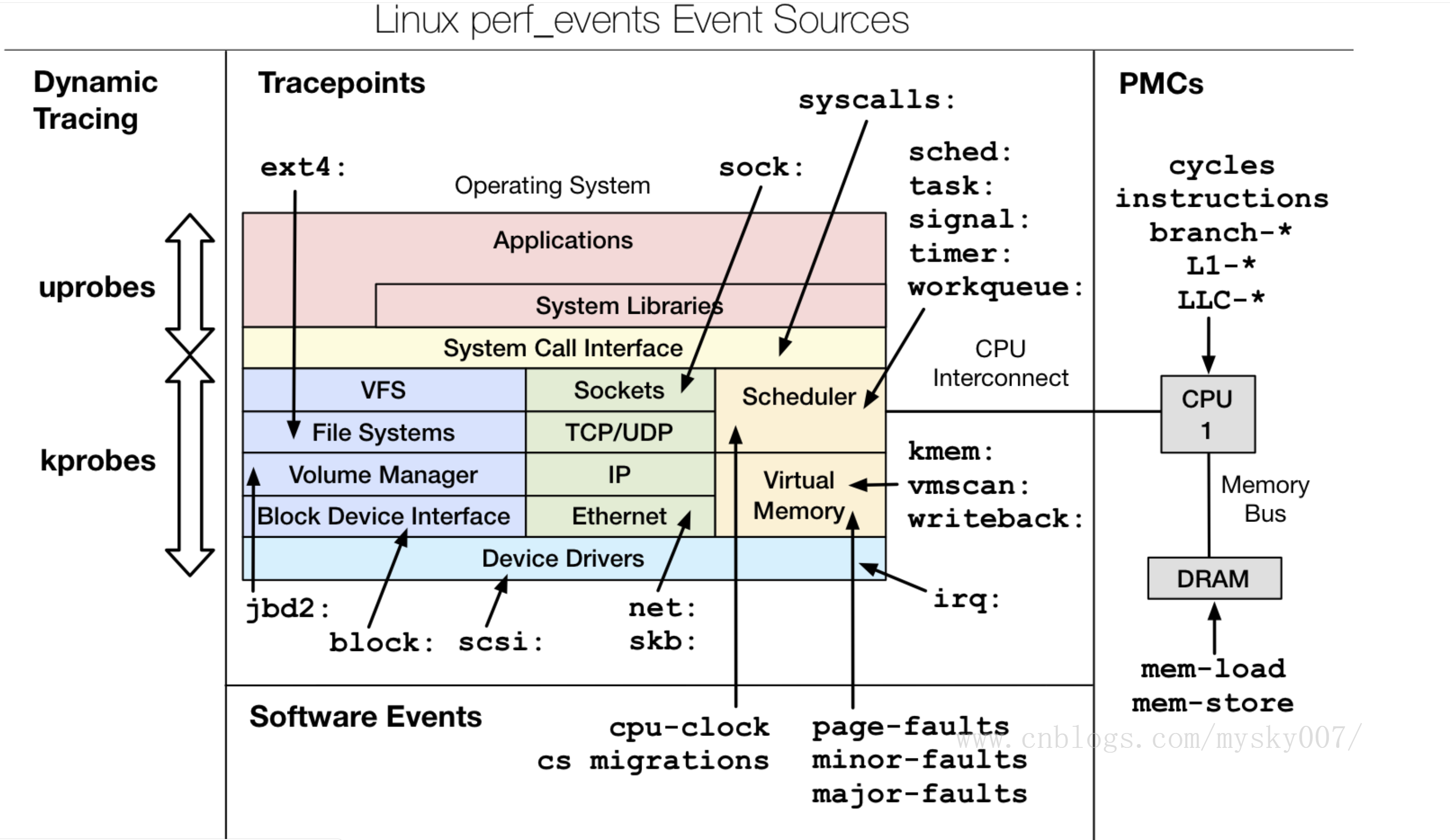
perf 的基本使用
考查下面这个例子程序。其中函数 longa() 是个很长的循环,比较浪费时间。函数 foo1 和 foo2 将分别调用该函数 10 次,以及 100 次
1 //test.c 2 void longa() 3 { 4 int i,j; 5 for(i = 0; i < 1000000; i++) 6 j=i; //am I silly or crazy? I feel boring and desperate. 7 } 8 9 void foo2() 10 { 11 int i; 12 for(i=0 ; i < 10; i++) 13 longa(); 14 } 15 16 void foo1() 17 { 18 int i; 19 for(i = 0; i< 100; i++) 20 longa(); 21 } 22 23 int main(void) 24 { 25 foo1(); 26 foo2(); 27 }
性能调优工具如 perf,Oprofile 等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但我想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
Perf list,perf 事件
使用 perf list 命令可以列出所有能够触发 perf 采样点的事件。比如
$ perf list List of pre-defined events (to be used in -e): cpu-cycles OR cycles [Hardware event] instructions [Hardware event] … cpu-clock [Software event] task-clock [Software event] context-switches OR cs [Software event] … ext4:ext4_allocate_inode [Tracepoint event] kmem:kmalloc [Tracepoint event] module:module_load [Tracepoint event] workqueue:workqueue_execution [Tracepoint event] sched:sched_{wakeup,switch} [Tracepoint event] syscalls:sys_{enter,exit}_epoll_wait [Tracepoint event] …
Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样;
Software Event 是内核软件产生的事件,比如进程切换,tick 数等 ;
Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等。
Perf stat
有些程序慢是因为计算量太大,其多数时间都应该在使用 CPU 进行计算,这叫做 CPU bound 型;有些程序慢是因为过多的 IO,这种时候其 CPU 利用率应该不高,这叫做 IO bound 型;对于 CPU bound 程序的调优和 IO bound 的调优是不同的。
1 $perf stat ./t1 2 Performance counter stats for './t1': 3 4 262.738415 task-clock-msecs # 0.991 CPUs 5 2 context-switches # 0.000 M/sec 6 1 CPU-migrations # 0.000 M/sec 7 81 page-faults # 0.000 M/sec 8 9478851 cycles # 36.077 M/sec (scaled from 98.24%) 9 6771 instructions # 0.001 IPC (scaled from 98.99%) 10 111114049 branches # 422.908 M/sec (scaled from 99.37%) 11 8495 branch-misses # 0.008 % (scaled from 95.91%) 12 12152161 cache-references # 46.252 M/sec (scaled from 96.16%) 13 7245338 cache-misses # 27.576 M/sec (scaled from 95.49%) 14 15 0.265238069 seconds time elapsed 16 17 上面告诉我们,程序 t1 是一个 CPU bound 型,因为 task-clock-msecs 接近 1
对 t1 进行调优应该要找到热点 ( 即最耗时的代码片段 ),再看看是否能够提高热点代码的效率。
缺省情况下,除了 task-clock-msecs 之外,perf stat 还给出了其他几个最常用的统计信息:
Task-clock-msecs:CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
Context-switches:进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。
Cache-misses:程序运行过程中总体的 cache 利用情况,如果该值过高,说明程序的 cache 利用不好
CPU-migrations:表示进程 t1 运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
Cycles:处理器时钟,一条机器指令可能需要多个 cycles,
Instructions: 机器指令数目。
IPC:是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性。
Cache-references: cache 命中的次数
Cache-misses: cache 失效的次数。
通过指定 -e 选项,您可以改变 perf stat 的缺省事件 ( 关于事件,在上一小节已经说明,可以通过 perf list 来查看 )。假如您已经有很多的调优经验,可能会使用 -e 选项来查看您所感兴趣的特殊的事件
Perf record 解读 report
使用 top 和 stat 之后,您可能已经大致有数了。要进一步分析,便需要一些粒度更细的信息。比如说您已经断定目标程序计算量较大,也许是因为有些代码写的不够精简。那么面对长长的代码文件,究竟哪几行代码需要进一步修改呢?这便需要使用 perf record 记录单个函数级别的统计信息,并使用 perf report 来显示统计结果。
您的调优应该将注意力集中到百分比高的热点代码片段上,假如一段代码只占用整个程序运行时间的 0.1%,即使您将其优化到仅剩一条机器指令,恐怕也只能将整体的程序性能提高 0.1%。俗话说,好钢用在刀刃上,不必我多说了。
1 perf record ./t1 2 perf report
1 Samples: 107 of event 'cycles', Event count (approx.): 889407873 2 Overhead Command Shared Object Symbol 3 99.26% t1 t1 [.] longa 4 0.61% t1 [kernel.kallsyms] [k] nmi 5 0.03% t1 [kernel.kallsyms] [k] __hrtimer_next_event_base 6 0.03% t1 [kernel.kallsyms] [k] __vma_adjust 7 0.02% t1 ld-2.30.so [.] 0x000000000001e378 8 0.02% t1 [kernel.kallsyms] [k] filemap_map_pages 9 0.02% t1 [kernel.kallsyms] [k] do_user_addr_fault 10 0.01% t1 [kernel.kallsyms] [k] move_page_tables 11 0.00% perf [kernel.kallsyms] [k] perf_event_comm_output 12 0.00% perf [kernel.kallsyms] [k] perf_pmu_enable.part.0 13 0.00% perf [kernel.kallsyms] [k] sched_clock 14 0.00% perf [kernel.kallsyms] [k] native_write_msr
不出所料,hot spot 是 longa( ) 函数
火焰图
1、Flame Graph项目位于GitHub上:https://github.com/brendangregg/FlameGraph
2、可以用git将其clone下来:git clone https://github.com/brendangregg/FlameGraph.git
我们以perf为例,看一下flamegraph的使用方法:
1、第一步
$sudo perf record -e cpu-clock -g -p 28591
Ctrl+c结束执行后,在当前目录下会生成采样数据perf.data.
2、第二步
用perf script工具对perf.data进行解析
perf script -i perf.data &> perf.unfold
3、第三步
将perf.unfold中的符号进行折叠:
#./stackcollapse-perf.pl perf.unfold &> perf.folded
4、最后生成svg图:
./flamegraph.pl perf.folded > perf.svg
