一、什么是:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
源于Google MapReduce论文(04年)。
MapReduce的核心是:分而治之,并行处理;以及其调度和处理数据的自动化。
Hadoop中MR的主要内容:
hadoop序列化writable接口,数据类型
应用开发 (debug 单元测试)解决基本数据处理,作业调优
工作机制 作业提交流程,作业调度,shuffle与排序
MR类型 输入输出类型
特性:二次排序(全排、部分排),join
压缩算法
二、基本流程:
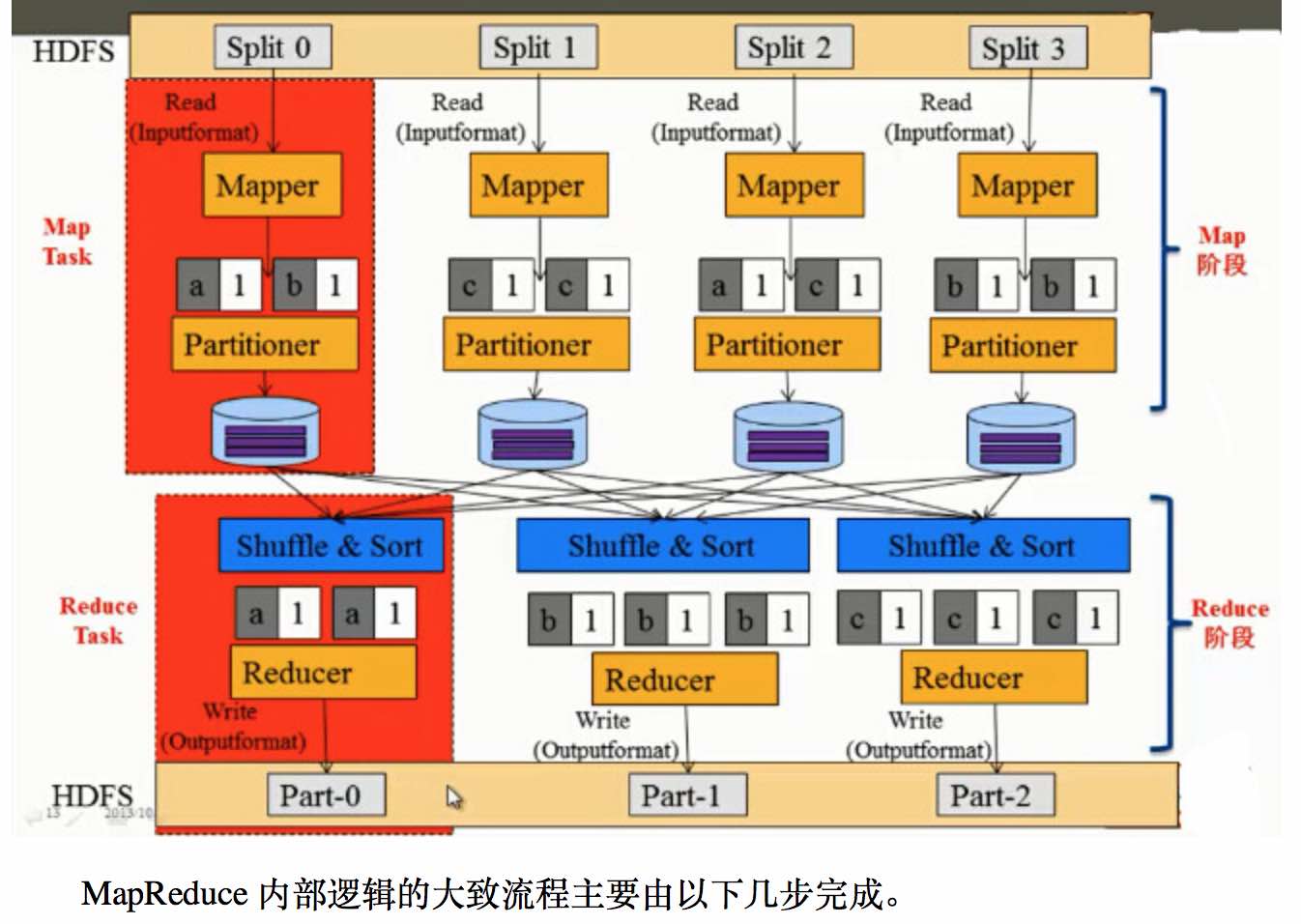
1、MR中主要是Map和Reduce两个阶段,其中基本流程是:
1、mr的数据处理单位是一个split,一个split对应一个map任务,处理时会有多个map任务同时运行;当map从HDFS上读取一个split时,这里会有“移动计算,不移动数据”的机制来减少网络的数据传输,使得效率能最大化;
2、获取到split时,默认会以TextInputFormat的格式读入,文件中的字符位置的偏移量作为 key,以及每一行的数据作为 value;
3、之后则进入map函数中进行处理,这个阶段可以获取需要的数据并加以处理,并以key value的形式写出,作为后面reduce函数的输入;
4、map到reduce之间会有一个shuffle的过程,大致过程是把不同key利用partitioner分散到各个reduce节点上去;
5、在reduce上会先通过 比较排序(前面shuffl会有预排序) 进行文件的归并,之后进入reduce函数,在每个reduce函数中key是唯一的,对应的value则是一个 Iterable接口类型,通过Iterable可以遍历所有当前key对应的所有value;
6、之后在reduce中对数据进行处理后,利用OutputFormat对处理后的key value保存到HDFS上即完成了整个流程。
注:一个split的大小计算:max( minimumSize, min( maximumSize, blockSize ));
通常 blockSize 在 minimumSize和maximumSize之间,所以一般分片大小就是块大小。
2、流程图:
3、编程中可定制的类:
InputFormat —> Mapper —> Partitioner (HashPartitioner) —> Combiner —> Reducer —> OutputFormat
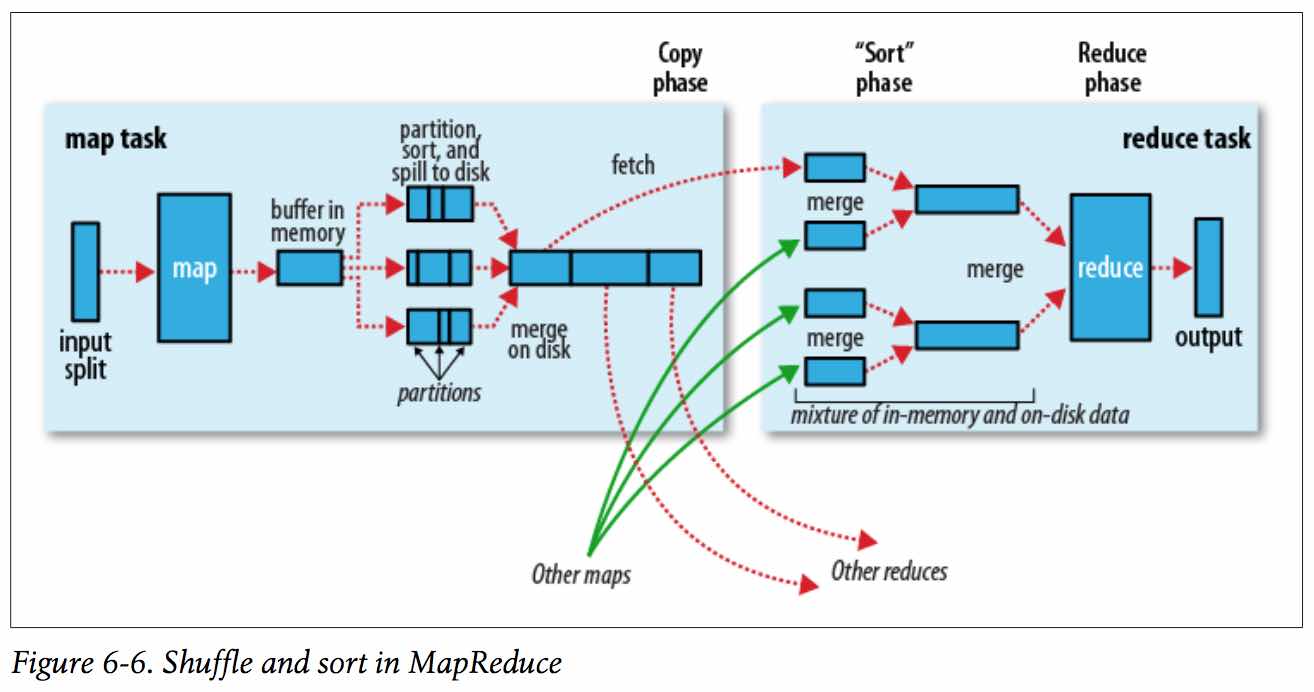
4、shuffle过程:map输出 到 reduce获取数据的过程。
三、优缺点:
优点: