ElasticSearch
基于的lucene开发的搜索服务技术;天生支持分布式;
Es的结构
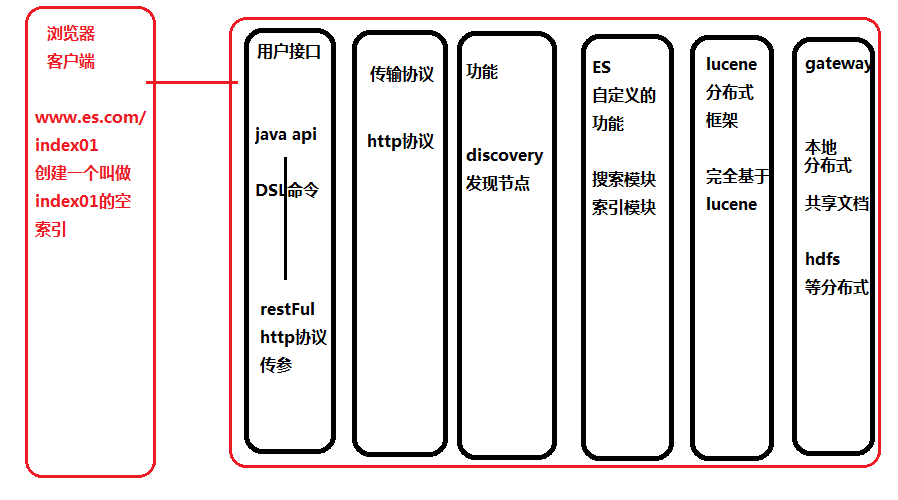
- gatway:存储层,所有的数据可以存储在本地(多个es节点形成分布式存储),hdfs输出位置,共享文件等
- 分布式lucene框架:把lucene缺少的分布式支持,做成一个基于lucene的框架
- ES自定义功能:ES自己的功能实现,例如关闭,打开索引,设置索引的读写权限等
- 功能插件:实现集群的管理,形成各种自定义插件,discovery自动发现功能
- 传输协议:支持http协议,支持thrift(AVRO)
- 用户接口: java api DSL操作命令基于http协议,发起的restFul传参操作ES
ElasticSearch存储应用概念
索引index:lucene中提到的索引文件,这个整体看来类似数据库中的某个库
类型Type: 在一个索引中,可以有不同结构的document存在,一批一批的相似结构,把同一批结构相同的document定义为一个类型(field结构相同);类似于数据库的表格
映射mapping: 不同类型中的各种field的属性(String int,分词计算器指定谁,长度,特性等等),都可以在mapping映射中体现;类似数据库的schema(结构)
文档document:搜索的数据基本单位,一个数据整体,document.类似数据库中一行数据记录row,类似java中的一个pojo对象
域属性field:类似于数据库中的一个列column
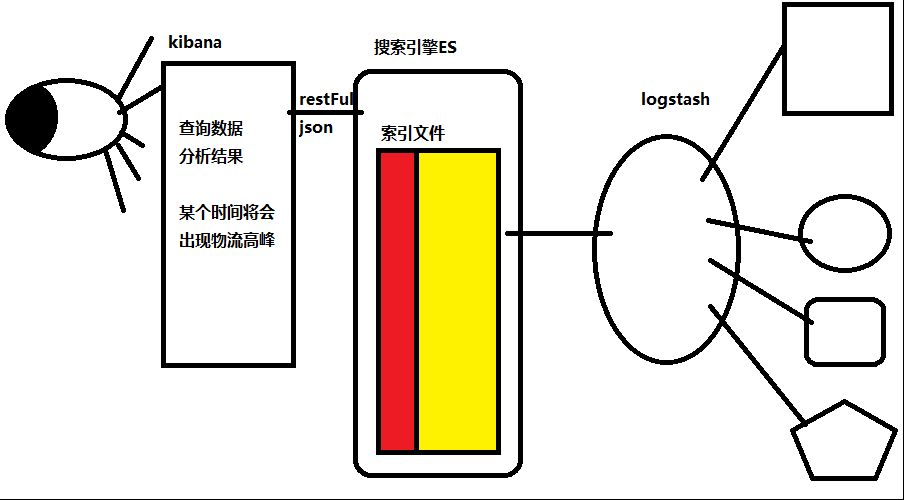
ELK家族:es衍生了一系列的开源软件,统称 Elastic Stack,包括分布式搜索引擎es,日志采集logstash,可视化平台分析kibana
ES的安装
https://www.cnblogs.com/nanlinghan/p/10084639.html
ES的配置
https://www.cnblogs.com/nanlinghan/p/10084647.html
java API 连接操作ES
代码没有实现连接集群名称不是ealasticsearch的settings
1 依赖pom的jar包,与lucene测试分开有冲突
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.5.2</version>
</dependency>
2 测试案例
• 连接es
创建一个连接对象TransportClient
3 操作步骤
• 索引的操作
新增
删除
• 文档的操作
新建文档
curl 命令传递的是请求体中的json字符串,es解析json创建不同结构不同类型的document对象,代码中把对象转化的json字符串,添加的请求体中,完成document的创建
{"id":10,
"name":"**",
"age":18
}
jackson 将pojo对象;easymall中的逻辑 es层,就是将数据库数据获取(持久层封装的就是pojo类对象),存入到es中需要转化成json
添加jackson-bind的依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.8</version>
</dependency>
创建一个对象pojo
User对象
Integer id
String name;
Integer age
1 package com.jt.es.test; 2 3 import java.io.IOException; 4 import java.net.InetAddress; 5 6 import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; 7 import org.elasticsearch.action.admin.indices.mapping.put.PutMappingRequest; 8 import org.elasticsearch.action.get.GetRequestBuilder; 9 import org.elasticsearch.action.index.IndexResponse; 10 import org.elasticsearch.action.search.SearchResponse; 11 import org.elasticsearch.client.IndicesAdminClient; 12 import org.elasticsearch.client.Requests; 13 import org.elasticsearch.client.transport.TransportClient; 14 import org.elasticsearch.common.settings.Settings; 15 import org.elasticsearch.common.transport.InetSocketTransportAddress; 16 import org.elasticsearch.common.xcontent.XContentBuilder; 17 import org.elasticsearch.common.xcontent.XContentFactory; 18 import org.elasticsearch.index.query.MatchQueryBuilder; 19 import org.elasticsearch.index.query.Operator; 20 import org.elasticsearch.index.query.QueryBuilders; 21 import org.elasticsearch.search.SearchHit; 22 import org.elasticsearch.search.SearchHits; 23 import org.elasticsearch.transport.client.PreBuiltTransportClient; 24 import org.junit.Before; 25 import org.junit.Test; 26 27 import com.fasterxml.jackson.core.JsonProcessingException; 28 import com.fasterxml.jackson.databind.ObjectMapper; 29 import com.jt.es.pojo.User; 30 31 32 public class ESTest { 33 private TransportClient client; 34 //测试连接对象 35 @Before 36 public void initial() throws Exception{ 37 //自定义Settings 38 //默认的empty中有一个就是集群名称 elasticsearch 39 client= 40 new PreBuiltTransportClient(Settings.EMPTY); 41 //传递ip和端口 9300,client可以调用多次add方法将集群其他可连接的 42 //节点同时传递 43 client.addTransportAddress( 44 new InetSocketTransportAddress( 45 InetAddress.getByName("10.9.100.26"),9300)); 46 } 47 //创建索引 48 @Test 49 public void createIndex(){ 50 //利用连接客户端client,获取索引的管理对象indexAdminClient 51 IndicesAdminClient indexClient = client.admin().indices(); 52 CreateIndexResponse cResponse = indexClient.prepareCreate("index05").get(); 53 //返回json {"acknowledged":true,"shards_acknowledged":true} 54 System.out.println(cResponse.isAcknowledged()); 55 System.out.println(cResponse.isShardsAcked()); 56 } 57 //删除 58 @Test 59 public void deleteIndex(){ 60 //利用连接客户端client,获取索引的管理对象indexAdminClient 61 IndicesAdminClient indexClient = client.admin().indices(); 62 indexClient.prepareDelete("index05").get();// 63 } 64 65 //新建文档 66 @Test 67 public void createDoc() throws Exception{ 68 //准备json字符串 69 User user=new User(); 70 user.setId(1); 71 user.setName("王首富"); 72 user.setAge(18); 73 ObjectMapper mapper=new ObjectMapper(); 74 String userJson=mapper.writeValueAsString(user); 75 //连接对象创建 index05,user类型,1的document 76 IndexResponse response = client.prepareIndex("index05", "user","1"). 77 setSource(userJson).execute().actionGet(); 78 System.out.println(response.toString()); 79 } 80 81 //获取document 82 @Test 83 public void getDoc(){ 84 GetRequestBuilder response = client.prepareGet("index05", "user", "1"); 85 System.out.println(response.get().getSourceAsString()); 86 87 } 88 89 //matchquery 90 @Test 91 public void query(){ 92 //封装查询对象query 93 MatchQueryBuilder query = QueryBuilders.matchQuery("title", "java编程思想hadoop") 94 .operator(Operator.OR);//查询结果必须包含条件中的所有分词 95 //客户端调用查询对象获取查询结果 96 // page rows 97 int page=1; 98 int rows=5; 99 int start= (page-1)*rows; 100 SearchResponse response = client.prepareSearch("book"). 101 setQuery(query).setFrom(start).setSize(rows).get(); 102 //获取响应结果中的数据,hits中 103 SearchHits hits = response.getHits(); 104 System.out.println("共搜索到:"+hits.totalHits); 105 for (SearchHit hit : hits) { 106 //获取响应结果中的source 107 System.out.println("title:"+hit.getSource().get("title")); 108 System.out.println("content:"+hit.getSource().get("content")); 109 } 110 } 111 }
ES集群
集群分布式和高可用在ES中都是默认配置和计算
• 集群的分布式,es的所有数据默认5个分片,每个分片默认一个副本(总共每个分片有2分,一份值主分片,一份是从分片)
• 集群配置完成后,启动所有集群节点,分片和副本的数据将会自动计算分配到不同的节点存储,只有从少到多的移动,没有从多到少的移动
• 分片默认5片,副本默认1片,自动根据集群节点数量最优的分配,分片越多,节点越多,副本越多的时候,整个集群的分布式性能越高,高可用能力越高