前几天看到有老外发微博说selenium不是自动化测试工具,在震惊之余我陷入了沉思,这种说法其实是有道理的,原来这个工具用了这么多年,这个隐藏的秘密我竟然一直没有发现。
很久很久之前,我在各种国外的测试论坛发现大家都在讨论一种新的工具:selenium,先入为主,由于在测试论坛最先产生的大范围讨论和关注,我一直把selenium当作是根正苗红的测试工具,这么多年来一直没有对这个观点产生过一点点的怀疑,哪怕selenium其实很多时候被人用作爬虫,很多时候被别有用心的人拿来做自动化的工具以获取不法收入,哪怕很多时候被用来做一些效率提升的工具,我都没有过一丝丝的动摇,在我心里,selenium就是最硬核的浏览器自动化测试工具之一。
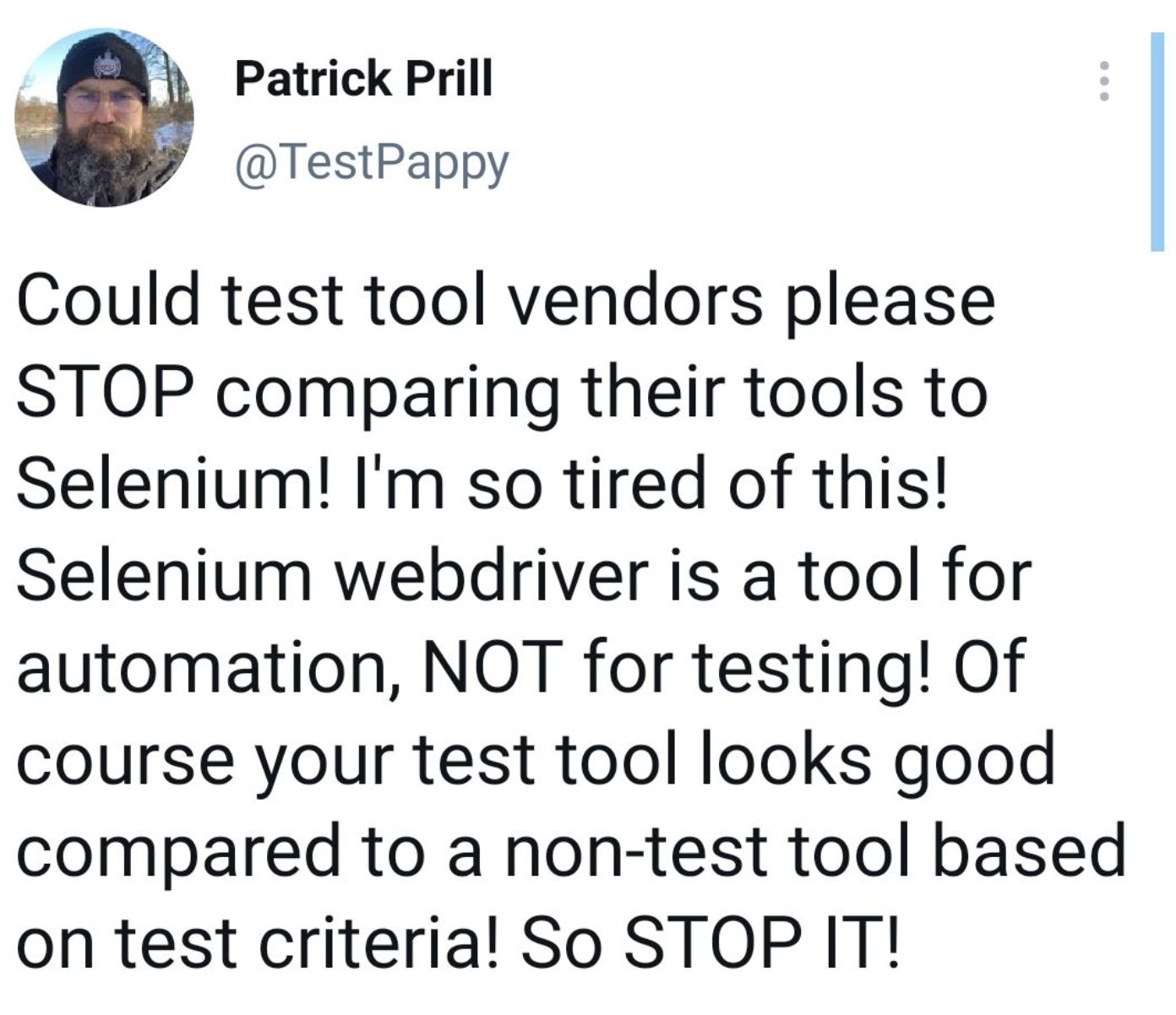
直到最近几天不经意间看到有人说(以下内容来自机翻)
测试工具供应商能否请停止将他们的工具与 Selenium 进行比较! 我厌倦了这个!
Selenium webdriver 是一种自动化工具,而不是用于测试! 当然,与非专业的测试工具相比,你开发的专门用于测试的测试工具看起来当然是很不错的了。拜托,歇歇吧。
看到上面的这条言论我才突然间意识到,selenium webdriver一直在不停的迭代,尽管速度很慢,但webdriver的各个版本里似乎总缺少点什么。于是有人总在搜索selenium的时候加上关键字pytest或者junit,于是我总是喜欢在面试的时候问你们用selenium的时候用的是拿个测试框架,于是专门有人写文章描述如何在断言里使用expected_conditions。这些证据都非常肯定的证明了selenium其实并不是专门为自动化测试设计的工具,selenium的核心是自动化工具,测试只是其应用的一部分场景而已,selenium明显格局更大,路走的更宽,真正掩耳盗铃的是我,我才是那个永远不能被叫醒的装睡的人。
渐渐的我意识到,怪不得我之前在公开课里演示selenium的应用时总是喜欢用selenium做爬虫的例子,怪不得我之前跟一些同学留的练习里,selenium扮演的角色也只是做效率提升的工作,比如每天签到之类,其实大部分时间我使用selenium只是把它当作是自动化的工具,测试真的只是我使用selenium的一个特别的场景,在这个场景里,一些工作变得很难,比如断言;一些情况我需要考虑的更多,比如各种环境和配置问题;一些问题变得很棘手,比如用例的修改速度往往赶不上页面重构的速度等等;我写selenium最有成就感,最得心应手,写着写着有点像读爽文的场景往往是
- 对爬取速度没有要求的爬虫
- 君子能不动手就不动手的场景,比如每天签到领金币
这些场景往往跟测试无关,与兴趣有关。
很久之前写的从知乎爬内容的selenium脚本,那时候firefox driver还是webdriver的自带驱动。
"""
从zhihu.com获取每日最热和每月最热
"""
from selenium import webdriver
from datetime import date
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class Zhihu:
def __init__(self):
self.daily_url = 'https://www.zhihu.com/explore#daily-hot'
self.monthly_url = 'https://www.zhihu.com/explore#monthly-hot'
def __enter__(self):
self.dr = webdriver.Firefox()
return self
def __exit__(self, p1, p2, p3):
self.dr.quit()
def get_daily_hots(self):
result = []
hots_urls = self.get_daily_hots_urls()
for url in hots_urls:
result.append(self.get_answer(url))
return result
def get_answer(self, url):
self.dr.get(url)
# wrap_div = self.dr.find_element_by_css_selector('.zm-item-answer.zm-item-expanded')
article = {}
article['question'] = self.dr.find_element_by_css_selector('#zh-question-title').text
article['author'] = self.dr.find_element_by_css_selector('.author-link').text
article['answer'] = self.dr.find_element_by_css_selector('.zm-editable-content.clearfix').get_attribute('innerHTML')
return article
def get_monthly_hots(self):
pass
def get_daily_hots_urls(self):
self.dr.get(self.daily_url)
wrap_div = self.dr.find_element_by_class_name('tab-panel')
title_url_elements = wrap_div.find_elements_by_class_name('question_link')
assert len(title_url_elements) == 5
urls = []
for title in title_url_elements:
urls.append(title.get_attribute('href'))
return urls
class ZhihuReporter:
def __init__(self, path):
self.report_path = path
self.f = open(path, 'wb')
def write_header(self):
self.f.write('<html><head><meta charset="utf-8">')
self.f.write('<link rel="stylesheet" href="http://cdn.bootcss.com/bootstrap/3.3.6/css/bootstrap.min.css">')
self.f.write('<title>Zhihu Report</title></head>')
def write_body(self):
self.f.write('<body>')
def finish_body(self):
self.f.write('</body>')
def write_article(self, articles):
self.f.write('<h3>知乎%s最热</h3>' %(date.today().strftime('%Y_%m_%d')))
for article in articles:
self.f.write('<div class="container">')
article_html = '<h3>%s<small>%s</small></h3>' %(article['question'], article['author'])
article_html += article['answer']
self.f.write(article_html)
self.f.write('</div>')
self.f.write('<hr>')
def finish_report(self):
self.finish_body()
self.f.write('</html>')
self.f.close()
def build_article_report(self, articles):
self.write_header()
self.write_body()
self.write_article(articles)
self.finish_report()
if __name__ == '__main__':
with Zhihu() as zhihu:
articles = zhihu.get_daily_hots()
report_name = 'zhihu_%s.html' %(date.today().strftime('%Y_%m_%d'))
reporter = ZhihuReporter(report_name)
reporter.build_article_report(articles)
其实这样看来,selenium作为自动化测试工具其实是有一定门槛的,比如需要结合测试框架,需要自定义po,需要手动维护一些复杂的等待情况,需要自己实现重试机制,更被说框架,断言,报告这祖传的三座大山了,正是因为这些痛点的存在,一些新的测试工具应运而生,这些工具为测试这个精准的场景提供了自己的解决方案,比如内置断言,自带测试报告等等,让自动化测试更容易,更稳定,更专业,也正是因为这些工具补齐了selenium所谓的一些“短板”,工具提开发商们便会不停的把selenium拿出来各种比较,以体现自己的先进性和革命性。不过这种比较是偏颇的,就像是在足球的世界里很多球员的头球能力都比梅西要强,但在进攻综合实力上梅西还是独一档的存在。这些专业的自动化测试工具就像是锤子或者起子,在某一方面很强,但selenium更像是个工具箱,适用的场景更多元化一些。

如果你问我这些专业的自动化测试工具我是不是不推荐,其实我的答案是否定的。
如果这些工具能让我们以更小的代价更低的成本来实现自动化测试的工作,我们何乐而不为呢?让工作变得更有效率,有更多的时间去做一些自己感兴趣的事情其实一直都是很多测试同学努力的方向。也许在未来的某一天,我会在工作中使用一些专业的自动化测试工具来帮我低成本实现测试的自动化,然后节省下来的时间写一些随性的selenium脚本,实现一些有趣的功能,这也未尝不是一件令人感到身心愉悦的事情。