单纯的SAP凭证批量打印,结合SAP Script+python很容易实现。小爬这次遇到的任务有点纠结:我们需要帮档案管理人员批量打印SAP凭证的同时,还要帮助打印这些凭证在OA办公平台中的流程表单+表单对应的各式附件,最后要将两个平台的打印数据进行匹配装订,这是目前的档案管理人员的手工工作模式。经过再三思考,小爬终于找到了该过程的自动化机会,以解决作业人员的痛点。
具体的思路是这样的:我们且先将SAP凭证批量,调用windows系统的PDF虚拟打印机,打印成一个个PDF文件,并以“OA表单编号-0.pdf"的格式进行重命名,最后再用python爬虫把这些表单号对应的URL获取到,并使用selenium驱动浏览器打开这些表单,后台静默下载表单的附件,打印OA表单,也以”OA表单编号-1(1~n).pdf"的格式命名,并与上一个步骤的凭证PDF文件存放于同一个文件夹。最终将这个文件夹以”表单编号“作为关键信息来遍历,并按照顺序自动推送这些文件给打印机,那么这些打印任务在输送给打印机之前就已经在系统内完成了排序,这样做可以解决两个平台单据打印后的线下匹配难&效率低问题。
小爬一开始也是这样做功能实现的,但是这样做,针对步骤一的SAP凭证批量打印为PDF文件,存在两个问题:
1、我们每打印一个凭证为PDF,就要驱动SAP的打印功能,驱动win32桌面的”打印“对话框,直至保存PDF文件成功,这个过程有一定概率失败,无论是findwindow方法还是sendmessage方法,都有较小的概率失败;
2、上面这套打印SAP凭证的组合拳需要频繁调用”打印“界面和”文件另存为PDF“界面,每次都需要3-4秒才能完成,效率不算高;
操作如下图的演示:
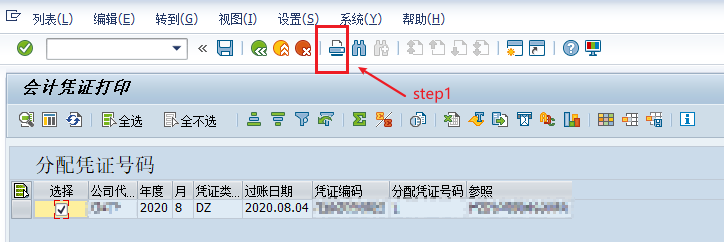

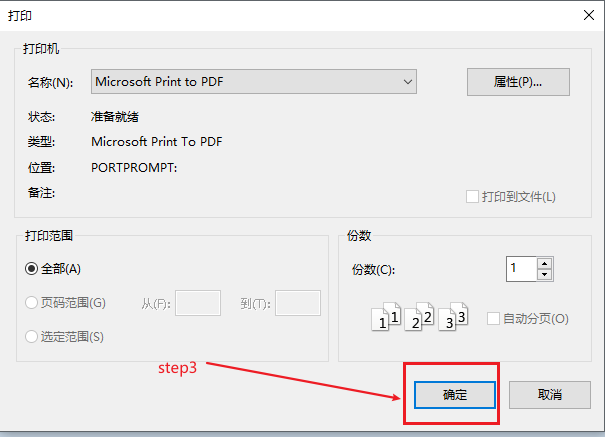
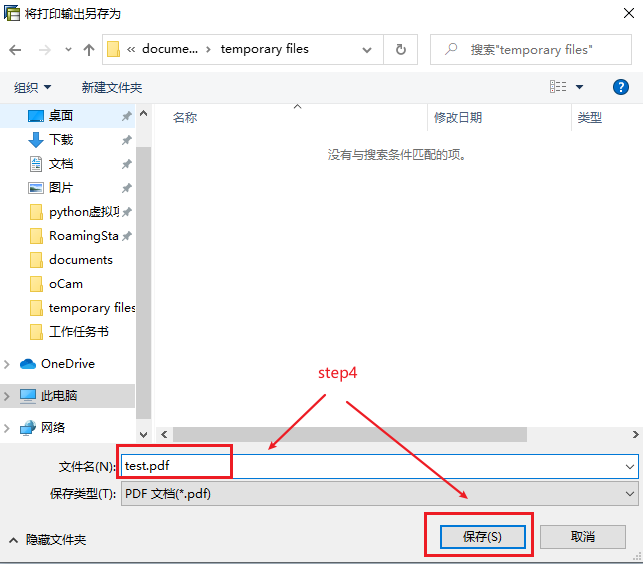
基于以上两个痛点,小爬决定继续寻求优化的方法。上述过程,可以考虑,用sap script驱动SAP全选所有待打印凭证,将所有凭证打印成一个PDF文件,那么就解决了频繁的打印PDF导致的效率问题和稳定性问题。结果表明,打印多个凭证为一个PDF文件,跟打印一个凭证为一个PDF文件耗时相当;
但这样做带来了另一个问题,这个”巨无霸“PDF文件,如何跟我们一个个OA表单文件+表单附件 进行系统内关联呢?
对问题层层分解后,我们发现,其实我们需要的是一个高效的PDF拆分工具、一个高效的PDF文本解析工具,一个高效的PDF文件合并工具。通俗的说,我们将含多个凭证的PDF文件,按页拆成一个个子PDF文件,再解析每个PDF文件的文本内容,将有共同特征(如:同一个SAP凭证编号)的子PDF文件进行组合(merge),还原成我们想要的:一个凭证(可能多页)对应一个PDF文件。这个工具必须得擅长拆分PDF、组合PDF、解析PDF文本,同时务必做到高效,效率如果太低,还不如一开始就打印出一个个PDF文件。
这就是针对这个场景,小爬的完整解决思路,下篇文章,我们将用python的方法,结合一些第三方工具和一些第三方package,一步步coding,来实现我们这一设想。