基于概率论的分类方法:朴素贝叶斯
本章内容
- 基于贝叶斯决策理论的分类方法
- 条件概率
- 使用条件概率来分类
- 使用朴素贝叶斯进行文档分类
- 使用 Python 进行文本分类
- 示例:使用朴素贝叶斯过滤垃圾邮件
- 总结
k-近邻算法和决策树都要求分类器做出决策,并通过输入特征输出一个最优的类别猜测结果,同时给出这个猜测值的概率估计值。
概率论是许多机器学习学习算法的基础,例如在计算信息增益的时候我们讲到的每个特征对应不同值所占的权重,即取得某个特征值的概率。
本章则会从一个最简单的概率分类器开始,然后给出一些假设来学习朴素贝叶斯分类器。
基于贝叶斯决策理论的分类方法
朴素贝叶斯的优缺点
优点:在数据较少的情况下仍然有效,可以处理多类别问题
缺点:对于输入数据的准备方式较为敏感
适用数据类型:标称型数据
贝叶斯决策理论
如图4-1所示,假设我们有一个由两类数据组成的数据集
图4-1 两类数据组成的数据集
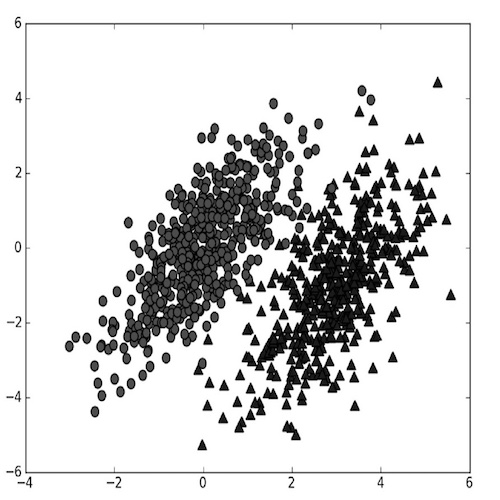
对于图4-1,我们用(p1(x,y))表示数据点((x,y))属于圆点表示的类别的概率;用(p2(x,y))表示数据点((x,y))属于三角形表示的类别的概率。
那么对于一个新数据点((x,y)),可以用下面的规则来判断它的类别:
* 如果(p1(x,y)>p2(x,y)),那么类别为1
* 如果(p2(x,y)>p1(x,y)),那么类别为2
通过该规则,我们可以发现我们始终会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择最高概率的决策。
现如今,假设该图中的整个数据使用6个浮点数来表示,并且只用两行 Python 代码计算类别。我们会可能有以下三种方法可以解决:
1. 使用kNN,进行1000次距离计算
2. 使用决策树,分别由 x 轴,y 轴划分数据
3. 计算数据点属于每个类别的概率,并进行比较
决策树不会非常成功;而使用 kNN 计算量较于方法3过于庞大,因此我们会选择方法3对数据进行分类。
为了能够使用方法3,我们需要通过条件概率这个知识点计算p1和p2的概率大小
条件概率
假设棋盆里有7粒棋子,3枚是灰色的,4枚是黑色的。如果从棋盆里取出一枚棋子,取出白棋子的概率为3/7,取出黑棋子的概率是4/7。
如果我们随机的把这7粒棋子装入两个棋盆中,如图4-2
图4-2 装入两个棋盆的棋子

我们把取到灰棋的概率称为 P(g),取到黑棋的概率称为 P(b)。现在我们想要知道从 B 桶中取到灰棋的概率,需要用到的就是条件概率,记作 P(g|b_B)=1/3。
条件概率的计算公式:P(g|b_B) = P(g and b_B)/P(b_B) = (1/7) / (3/7) = 1/3
另一张有效计算条件概率的方法称为贝叶斯准则,如果已知P(x|c),可以求出P(c|x)的值
(p(c|x)={frac{p(x|c)p(c)}{p(x)}})
使用条件概率来分类
之前介绍贝叶斯决策理论需要计算两个概率p1(x,y)和p2(x,y),但是在本例中真正需要计算的事 p(c~1~|x,y) 和 p(c~2~|x,y)。这些符号代表的意义是:给定某个由 x、y 表示的数据点,那么这个数据点来自类别 c~1~ 和 c~2~的概率是多少?而这个符号我们可以通过贝叶斯准则得到:
(p(c_i|x,y)={frac{p(x,y|c_i)p(c_i)}{p(x,y)}})
使用定义后,可以定义贝叶斯分类准则为:
* 如果 P(c~1~|x,y) > P(c~2~|x,y),那么属于类别 c~1~
* 如果 P(c~2~|x,y) < P(c~2~|x,y),那么属于类别 c~2~
使用朴素贝叶斯进行文档分类
通过观察文档中出现的词,对于现存的一个词汇表,把每个词的出现或者不出现作为一个特征。
朴素贝叶斯的一般过程
1. 收集数据:可以使用任何方法。本章使用 RSS 源
2. 准备数据:需要数值型或者布尔型数据
3. 分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好
4. 训练算法:计算不同的独立特征的条件概率
5. 测试算法:计算错误率
6. 使用算法:一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴素贝叶斯分类器,不一定非要是文本。
假设词汇表中有1000个单词。要得到好的概率分布,就需要足够的数据样本,假设样本数为 N。
由统计学可知,如果每个特征需要 N 个样本,那么对于10个特征将需要 N^10^个样本,对于包含1000个特征的词汇表将需要 N^1000^个样本。
如果特征之间相互独立,那么样本数就可以从 N^1000^减少到1000*N。独立指的是统计意义上的独立,即一个特征或者单词出现的可能性与其他相邻单词没有关系。
使用 Python 进行文本分类
拆分文本之后对比拆分后的词条向量和现有的词汇表,词条出现即不合法词条值为1;词条未出现即合法词条值为0。
准备数据:从文本中构建词向量
为了能够对比词条和词汇表,我们考虑文档中的所有单词并把把文本构造成词条向量,再决定将哪些词纳入词汇表。
因此我们需要构造一个函数 load_data_set 方法。
# bayes.py
def load_data_set():
"""创建实验样本"""
# 实验样本
posting_list = [['my', 'dog', 'has', 'flea', 'problem', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
# 样本标记
class_vec = [0, 1, 0, 1, 0, 1] # 1代表侮辱性文字,0代表正常言论
return posting_list, class_vec
def create_vocab_list(data_set):
"""创建词汇表"""
vocab_set = set([])
# 创建不含重复单词的词汇表
for document in data_set:
vocab_set = vocab_set | set(document)
return list(vocab_set)
def set_of_words2vec(vocab_list, input_set):
"""创建文档向量"""
# 创建一个和词汇表等长且元素全为0的列表
return_vec = [0] * len(vocab_list)
# 遍历文档
for word in input_set:
# 如果单词出现在词汇表中,则将0替换成1
if word in vocab_list:
return_vec[vocab_list.index(word)] = 1
else:
print('{} 不在词汇表中'.format(word))
return return_vec
def set_of_words2vec_run():
list_of_posts, list_classes = load_data_set()
my_vocab_list = create_vocab_list(list_of_posts)
print(my_vocab_list)
# ['park', 'ate', 'licks', 'steak', 'please', 'love', 'is', 'him', 'maybe', 'how', 'dog', 'has', 'food',
# 'dalmation', 'I', 'my', 'stop', 'worthless', 'help', 'garbage', 'stupid', 'quit', 'cute', 'mr', 'buying',
# 'posting', 'not', 'flea', 'problem', 'so', 'to', 'take']
return_vec = set_of_words2vec(my_vocab_list, list_of_posts[0])
print(return_vec)
# [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1]
if __name__ == '__main__':
set_of_words2vec_run()
训练算法:从词向量计算概率
如果我们将上述公式中的(x,y)替换成粗体 w,粗体 w 表示一个由多个值组成的向量。即上述的 return_vec。
(p(c_i|w)={frac{p(w|c_i)p(c_i)}{p(w)}})
对上述公式的解释:p(c~i~)指的是类别 i 中文档数除以总的文档数;p(w|c~i~)需要用到朴素贝叶斯假设,即将 w 展开为一个独立特征,那么就可以写作p(w~0~,w~1~,w~2~...w~N~|c~i~)。假设所有词都相互独立,即可以使用p(w~0~|c~i~)p(w~1~|c~i~)p(w~2~|c~i~)...p(w~N~|c~i~)来计算上述概率。
函数的伪代码如下:
```
计算每个类别中的文档数目
对每篇训练文档:
对每个类别:
如果词条出现在文档中-》增加该词条的计数值
增加所有词条的计数值
对每个类别:
对每个词条:
将该词条的数目除以总词条数目得到条件概率
返回每个类别的条件概率
```
我们构造一个 train_nb_0 方法来实现我们的伪代码:
# bayes.py
def train_nb_0(train_matrix, train_category):
"""计算每个类别中的文档数目"""
import numpy
num_train_docs = len(train_matrix)
num_words = len(train_matrix[0])
# 计算属于侮辱性文档的概率,因为侮辱为1,非侮辱为0,使用 sum 函数可以计算
p_abusive = sum(train_category) / float(num_train_docs)
# 初始化概率
p0_num = numpy.zeros(num_words)
p1_num = numpy.zeros(num_words)
p0_denom = 0
p1_denom = 0
# 遍历文档矩阵
for i in range(num_train_docs):
# 计算文档中侮辱性的句子总和以及单词在词汇表中的计数总和
if train_category[i] == 1:
p1_num += train_matrix[i]
p1_denom += sum(train_matrix[i])
# 计算文档中非侮辱性的句子总和以及单词在词汇表中的计数总和
else:
p0_num += train_matrix[i]
p0_denom += sum(train_matrix[i])
# 计算每个元素除以该类别中的总词数,即矩阵中的每个元素除以int(p1_denom)
p1_vect = p1_num / p1_denom
p0_vect = p0_num / p0_denom
return p0_vect, p1_vect, p_abusive
def train_nb_0_run():
# 创建词汇表
list_of_posts, list_classes = load_data_set()
my_vocab_list = create_vocab_list(list_of_posts)
# 把数据集中的所有单词转化成0,1的值,即不在词汇表中、在词汇表中
train_mat = []
for post_in_doc in list_of_posts:
# 比较词汇表与句子,在词汇表中则词汇表中单词数+1
train_mat.append(set_of_words2vec(my_vocab_list, post_in_doc))
# 每个元素除以该类别总词数,返回每个类别的条件概率
p0_v, p1_v, p_ab = train_nb_0(train_mat, list_classes)
print(p0_v)
print(p1_v)
print(p_ab)
# 0.5
if __name__ == '__main__':
# set_of_words2vec_run()
train_nb_0_run()
测试算法:根据现实情况修改分类器
利用贝叶斯对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算 p(w~0~|1)p(w~1~|1)p(w~2~|1)。如果其中一个概率值为0,那么最后的乘积也为0.因此将所有词的出现次数初始化为1,并将分母初始化为2。
因此修改 bayes.py 文件下的 train_nb_0 方法
# bayes.py
def train_nb_0(train_matrix, train_category):
"""计算每个类别中的文档数目"""
import numpy
num_train_docs = len(train_matrix)
num_words = len(train_matrix[0])
p_abusive = sum(train_category) / float(num_train_docs)
# 用1填充矩阵
p0_num = numpy.ones(num_words)
p1_num = numpy.ones(num_words)
p0_denom = 2
p1_denom = 2
for i in range(num_train_docs):
if train_category[i] == 1:
p1_num += train_matrix[i]
p1_denom += sum(train_matrix[i])
else:
p0_num += train_matrix[i]
p0_denom += sum(train_matrix[i])
p1_vect = p1_num / p1_denom
p0_vect = p0_num / p0_denom
return p0_vect, p1_vect, p_abusive
另一个问题是下溢出,即由于太多很小的数相乘造成的。当计算p(w~0~|c~i~)p(w~1~|c~i~)p(w~2~|c~i~)...p(w~N~|c~i~)时,由于大部分因子都非常小,Python 得出的计算结果可能四舍五入之后会得到0。因此我们利用代数中的 ln(a*b)=ln(a)+ln(b),即修改 train_nb_0 方法中的返回结果
def train_nb_0(train_matrix, train_category):
"""计算每个类别中的文档数目"""
import numpy
num_train_docs = len(train_matrix)
num_words = len(train_matrix[0])
p_abusive = sum(train_category) / float(num_train_docs)
# 用1填充矩阵
p0_num = numpy.ones(num_words)
p1_num = numpy.ones(num_words)
p0_denom = 2
p1_denom = 2
for i in range(num_train_docs):
if train_category[i] == 1:
p1_num += train_matrix[i]
p1_denom += sum(train_matrix[i])
else:
p0_num += train_matrix[i]
p0_denom += sum(train_matrix[i])
p1_vect = numpy.log(p1_num / p1_denom)
p0_vect = numpy.log(p0_num / p0_denom)
return p0_vect, p1_vect, p_abusive
通过 classify_nb 方法构建完整的分类器:
# bayes.py
def classify_nb(vec2_classify, p0_vec, p1_vec, p_class1):
"""构建完整的分类器"""
import math
p1 = sum(vec2_classify * p1_vec) + math.log(p_class1)
p0 = sum(vec2_classify * p0_vec) + math.log(1 - p_class1)
if p1 > p0:
return 1
else:
return 0
def testing_nb_run():
import numpy
list_of_posts, list_classes = load_data_set()
my_vocab_list = create_vocab_list(list_of_posts)
train_mat = []
for post_in_doc in list_of_posts:
train_mat.append(set_of_words2vec(my_vocab_list, post_in_doc))
p0_v, p1_v, p_ab = train_nb_0(train_mat, list_classes)
test_entry = ['love', 'my', 'dalmation']
this_doc = numpy.array(set_of_words2vec(my_vocab_list, test_entry))
print('{} 分类结果 {}'.format(test_entry, classify_nb(this_doc, p0_v, p1_v, p_ab)))
# test_entry = ['stupid', 'garbage']
# this_doc = numpy.array(set_of_words2vec(my_vocab_list, test_entry))
# print('{} 分类结果 {}'.format(test_entry, classify_nb(this_doc, p0_v, p1_v, p_ab)))
if __name__ == '__main__':
# set_of_words2vec_run()
# train_nb_0_run()
testing_nb_run()
准备数据:文档词袋模型
如果一个词在文档中只出现一次作为特征,那么该模型称作词集模型;如果一个词在文档中出现不止一次,那么文档是否出现作为特征并不能确切的表达出某种信息,这种模型称作词袋模型。
为了适应词袋模型,我们把 set_of_words2vec 方法修改成 bag_of_words2vec 方法
# bayes.py
def bag_of_words2vec(vocal_list, input_set):
"""词袋模型"""
return_vec = [0] * len(vocal_list)
# 遍历词汇表有对应的单词计数加1
for word in input_set:
if word in vocal_list:
return_vec[vocal_list.index(word)] += 1
return return_vec
示例:使用朴素贝叶斯过滤垃圾邮件
我们已经手动构建了一个朴素贝叶斯分类器,我们可以通过上述的分类器过滤垃圾邮件。但是下面我们将介绍如何使用通用框架来解决该问题。
1. 收集数据:提供文本文件
2. 准备数据:将文本解析成词条向量
3. 分析数据:检查词条确保解析的正确性
4. 训练算法:使用我们之前建立的 train_nb_0 方法
5. 测试算法:使用 classify_nb 方法,并且构建一个新的测试函数来计算文档集的错误率
6. 使用算法:构建一个完整的程序对一组文档进行分类,将错分的文档输出到屏幕上
准备数据:切分文本
前面创建分类器的词列表是直接给出的。
作为程序猿的我们应该自己切分文本得到词向量,因此我们构造一个 text_parse 方法构造词列表:
# bayes.py
def text_parse(my_text):
import re
# 使用正则切分句子,分隔符是除单词、数字外的任意字符串
# 加上[]是避免报警告:不能用零长度字符串切分
reg_ex = re.compile('[W*]')
list_of_tokens = reg_ex.split(my_text)
# 只返回长度大于0的单词并把切分的单词全小写
tok_list = [tok.lower() for tok in list_of_tokens if len(tok) > 0]
return tok_list
def text_parse_run():
import os
email_filename = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'data-set/email/ham/6.txt')
with open(email_filename, 'r') as fr:
email_text = fr.read()
tok_list = text_parse(email_text)
print(tok_list)
if __name__ == '__main__':
# set_of_words2vec_run()
# train_nb_0_run()
# testing_nb_run()
text_parse_run()
这只是一个很简单的分词方法,显示业务一定不是这样的。千万别套用。
测试算法:使用朴素贝叶斯进行交叉验证
下面我们把文本解析器集成到一个完整分类器中。
因此我们构造 spam_test 方法
# bayes.py
def span_test():
import os
import numpy
# 导入并解析文件
doc_list = []
class_list = []
full_text = []
email_filename = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'data-set/email/{}/{}.txt')
for i in range(1, 26):
# 切割垃圾邮件文本并添加标记
word_list = text_parse(open(email_filename.format('spam', i),errors='ignore').read())
doc_list.append(word_list)
full_text.extend(word_list)
class_list.append(1)
# 切割非垃圾邮件文本并添加标记
word_list = text_parse(open(email_filename.format('ham', i),errors='ignore').read())
doc_list.append(word_list)
full_text.extend(word_list)
class_list.append(0)
# 构造词汇表
vocab_list = create_vocab_list(doc_list)
# 从50封邮件中随机取10封邮件当做测试集
training_set = list(range(50))
test_set = []
for i in range(10):
rand_index = int(numpy.random.uniform(0, len(training_set)))
print(rand_index)
test_set.append(training_set[rand_index])
del (training_set[rand_index])
# 创建词汇向量
train_mat = []
train_classes = []
for doc_index in training_set:
train_mat.append(set_of_words2vec(vocab_list, doc_list[doc_index]))
train_classes.append(class_list[doc_index])
# 通过词汇向量和向量标记得到垃圾邮件和非垃圾邮件概率
p0_v, p1_v, p_spam = train_nb_0(numpy.array(train_mat), numpy.array(train_classes))
# 测试集测试分类器
error_count = 0
for doc_index in test_set:
word_vector = set_of_words2vec(vocab_list, doc_list[doc_index])
if classify_nb(numpy.array(word_vector), p0_v, p1_v, p_spam) != class_list[doc_index]:
error_count += 1
print('错误率:{}'.format(float(error_count) / len(test_set)))
if __name__ == '__main__':
# set_of_words2vec_run()
# train_nb_0_run()
# testing_nb_run()
# text_parse_run()
span_test()
总结
对于分类而言,使用概率有时要比使用应规则更为有效。贝叶斯概率及贝叶斯准则提供了一种利用已知值来估计未知概率的有效方法,也因此该分类决策存在一定的错误率。
由于基础高等数学《概率论》学得不扎实。刚开始看朴素贝叶斯也有点懵逼,所以代码注释较少,本篇博客写的可能不是很好,但是今天抽空看了几篇相关博客,下次有空会单独写一篇有关朴素贝叶斯的博客,有不懂的可以私聊,这相当于学习笔记,不是最终稿,更不是个人心得改就懒得改了。