先给一堆学习文档,方便以后查看
官网文档地址大全:
OverView(概述)
http://zookeeper.apache.org/doc/r3.4.6/zookeeperOver.html
Getting Started(开始入门)
http://zookeeper.apache.org/doc/r3.4.6/zookeeperStarted.html
Tutorial(教程)
http://zookeeper.apache.org/doc/r3.4.6/zookeeperTutorial.html
Java Example(Java示例)
http://zookeeper.apache.org/doc/r3.4.6/javaExample.html
Programmer's Guide(开发人员指南)
http://zookeeper.apache.org/doc/r3.4.6/zookeeperProgrammers.html
Recipes and Solutions(技巧及解决方案)
http://zookeeper.apache.org/doc/r3.4.6/recipes.html
3.4.6 API online(在线API速查)
http://zookeeper.apache.org/doc/r3.4.6/api/index.html
另外推荐园友sunddenly的zookeeper系列
http://www.cnblogs.com/sunddenly/category/620563.html
一、安装部署
本文在一台机器上模拟3个 zk server的集群安装
1.1 下载解压
解压到3个目录(模拟3台zk server):
/home/hadoop/zookeeper-1 /home/hadoop/zookeeper-2 /home/hadoop/zookeeper-3
1.2 创建每个目录下conf/zoo.cfg配置文件
/home/hadoop/zookeeper-1/conf/zoo.cfg 内容如下:

tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/hadoop/tmp/zk1/data dataLogDir=/home/hadoop/tmp/zk1/log clientPort=2181 server.1=localhost:2287:3387 server.2=localhost:2288:3388 server.3=localhost:2289:3389
/home/hadoop/zookeeper-2/conf/zoo.cfg 内容如下:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/hadoop/tmp/zk2/data dataLogDir=/home/hadoop/tmp/zk2/log clientPort=2182 server.1=localhost:2287:3387 server.2=localhost:2288:3388 server.3=localhost:2289:3389
/home/hadoop/zookeeper-3/conf/zoo.cfg 内容如下:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/hadoop/tmp/zk3/data dataLogDir=/home/hadoop/tmp/zk3/log clientPort=2183 server.1=localhost:2287:3387 server.2=localhost:2288:3388 server.3=localhost:2289:3389
注:因为是在一台机器上模拟集群,所以端口不能重复,这里用2181~2183,2287~2289,以及3387~3389相互错开。另外每个zk的instance,都需要设置独立的数据存储目录、日志存储目录,所以dataDir、dataLogDir这二个节点对应的目录,需要手动先创建好。
另外还有一个灰常关键的设置,在每个zk server配置文件的dataDir所对应的目录下,必须创建一个名为myid的文件,其中的内容必须与zoo.cfg中server.x 中的x相同,即:
/home/hadoop/tmp/zk1/data/myid 中的内容为1,对应server.1中的1
/home/hadoop/tmp/zk2/data/myid 中的内容为2,对应server.2中的2
/home/hadoop/tmp/zk3/data/myid 中的内容为3,对应server.3中的3
生产环境中,分布式集群部署的步骤与上面基本相同,只不过因为各zk server分布在不同的机器,上述配置文件中的localhost换成各服务器的真实Ip即可。分布在不同的机器后,不存在端口冲突问题,可以让每个服务器的zk均采用相同的端口,这样管理起来比较方便。
1.3 启动验证
/home/hadoop/zookeeper-1/bin/zkServer.sh start /home/hadoop/zookeeper-2/bin/zkServer.sh start /home/hadoop/zookeeper-3/bin/zkServer.sh start
启用成功后,输入 jps 看下进程
20351 ZooKeeperMain
20791 QuorumPeerMain
20822 QuorumPeerMain
20865 QuorumPeerMain
应该至少能看到以上几个进程。
可以启动客户端测试下:
bin/zkCli.sh -server localhost:2181
(注:如果是远程连接,把localhost换成指定的IP即可)
成功后,应该会进到提示符下,类似下面这样:
[zk: localhost:2181(CONNECTED) 0]
然后,就可以用一些基础命令,比如 ls ,create ,delete ,get 来测试了(关于这些命令,大家可以查看文档),特别提一个很有用的命令rmr 用来递归删除某个节点及其所有子节点
二、java 与 zk的连接示例
2.1 maven项目的pom.xml中先添加以下依赖项
<!--zk-->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
2.2 最基本的示例程序
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
package yjmyzz;import java.io.IOException;import org.apache.zookeeper.*;import org.apache.zookeeper.data.Stat;public class ZooKeeperHello { public static void main(String[] args) throws IOException, InterruptedException, KeeperException { ZooKeeper zk = new ZooKeeper("172.28.20.102:2181", 300000, new DemoWatcher());//连接zk server String node = "/app1"; Stat stat = zk.exists(node, false);//检测/app1是否存在 if (stat == null) { //创建节点 String createResult = zk.create(node, "test".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); System.out.println(createResult); } //获取节点的值 byte[] b = zk.getData(node, false, stat); System.out.println(new String(b)); zk.close(); } static class DemoWatcher implements Watcher { @Override public void process(WatchedEvent event) { System.out.println("----------->"); System.out.println("path:" + event.getPath()); System.out.println("type:" + event.getType()); System.out.println("stat:" + event.getState()); System.out.println("<-----------"); } }} |
2.3 与zk集群的连接
zk的优点之一,就是高可用性,上面的代码连接的是单台zk server,如果这台server挂了,自然代码就会出错,事实上zk的API考虑到了这一点,把连接代码改成下面这样:
ZooKeeper zk = new ZooKeeper("172.28.20.102:2181,172.28.20.102:2182,172.28.20.102:2183", 300000, new DemoWatcher());//连接zk server
即:IP1:port1,IP2:port2,IP3:port3... 用这种方式连接集群就行了,只要有超过半数的zk server还活着,应用一般就没问题。但是也有一种极罕见的情况,比如这行代码执行时,刚初始化完成,正准备连接ip1时,因为网络故障ip1对应的server挂了,仍然会报错(此时,zk还来不及选出新leader),这个问题详见:http://segmentfault.com/q/1010000002506725/a-1020000002507402,参考该文的做法,改成:
1 ZooKeeper zk = new ZooKeeper("172.28.20.102:2181,172.28.20.102:2182,172.28.20.102:2183", 300000, new DemoWatcher());//连接zk server
2 if (!zk.getState().equals(ZooKeeper.States.CONNECTED)) {
3 while (true) {
4 if (zk.getState().equals(ZooKeeper.States.CONNECTED)) {
5 break;
6 }
7 try {
8 TimeUnit.SECONDS.sleep(5);
9 } catch (InterruptedException e) {
10 e.printStackTrace();
11 }
12 }
13 }
但是这样代码未免太冗长,建议用开源的zkClient,官方地址: https://github.com/sgroschupf/zkclient,使用方法很简单:
<!--zkclient-->
<dependency>
<groupId>com.github.sgroschupf</groupId>
<artifactId>zkclient</artifactId>
<version>0.1</version>
</dependency>
pom.xml先加这一坨,然后这样用:
1 @Test
2 public void testZkClient() {
3 ZkClient zkClient = new ZkClient("172.28.20.102:2181,172.28.20.102:2182,172.28.20.102:2183");
4 String node = "/app2";
5 if (!zkClient.exists(node)) {
6 zkClient.createPersistent(node, "hello zk");
7 }
8 System.out.println(zkClient.readData(node));
9 }
出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
一脸懵逼搭建Zookeeper分布式集群
1:首先将http://zookeeper.apache.org/
下载好的zookeeper-3.4.5.tar.gz上传到三台虚拟机上,之前博客搭建好的(安装Zookeeper之前记得安装好你的jdk哦)。
2:然后对zookeeper-3.4.5.tar.gz进行解压缩操作:
[hadoop@master ~]$ tar -zxvf zookeeper-3.4.5.tar.gz

3:然后进入conf目录(将zoo_sample.cfg修改为zoo.cfg):
mv修改名称或者cp一个,老的作为样本:

4:然后打开zoo.cfg文件:

修改一些配置:
tickTime=2000 心跳间隔
initLimit=10 初始容忍的心跳数
syncLimit=5 等待最大容忍的心跳数
dataDir=/tmp/zookeeper 本地保存数据的目录,tmp存放的临时数据,可以修改为自己的目录;
clientPort=2181 客户端默认端口号
如果有需要,我感觉加上日志很有必要,如果出错了,还有地方可以去查找:
dataLogDir=/home/hadoop/zookeeper/log

修改后的如下所示(红色圈起来的是修改的):
server.1=master:2888:3888 (主机名, 心跳端口、数据端口)
server.2=slave1:2888:3888
server.3=slave2:2888:3888
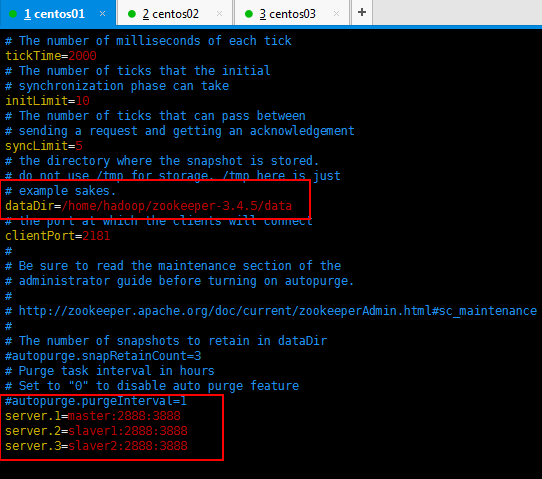
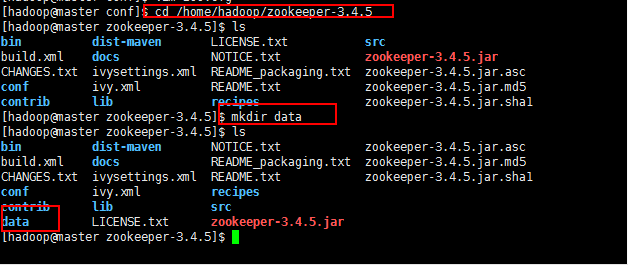
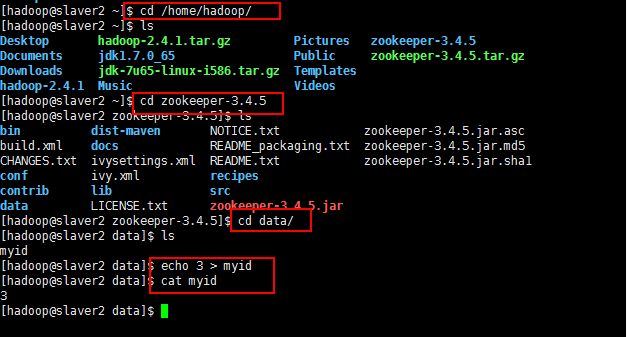
5:由于需要事先创建好data目录,所以现在创建data目录:
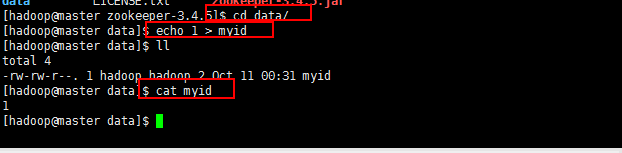
然后在data目录创建一个文件myid,里面写一个1,如下所示:
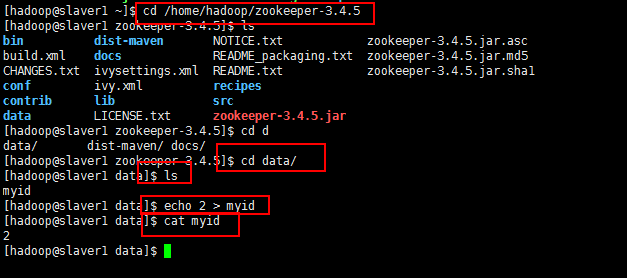
5:然后将修改好的复制到slaver1和slaver2上面


然后分别将slaver1和slaver2的myid修改为2和3,如下所示:
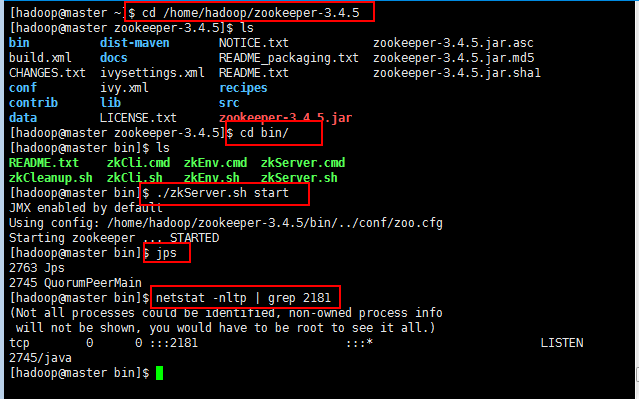
6:至此Zookeeper搭建结束,下面开始启动Zookeeper,分别启动:
如果你不想切换到Zookeeper目录启动,可以配置环境变量:
vi /etc/profile(修改文件)
export ZOOKEEPER_HOME=/home/hadoop/zookeeper
export PATH=PATH:PATH:ZOOKEEPER_HOME/bin
重新编译文件:
source /etc/profile
注意:3台zookeeper都需要修改
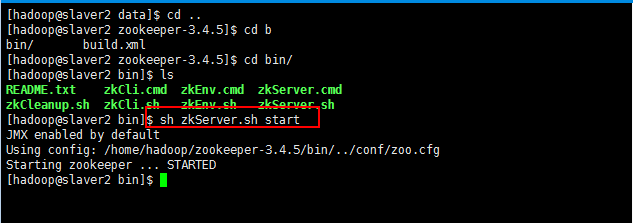
少于三台不会正常工作的,可以通过命令查询状态:

7:接下来启动slaver1和slaver2的服务:

三台机器启动完成以后,可以查看其状态,开始报这个错,就是启动不了Zookeeper,然后百度呗,百度很多方法,还存在版本问题,新生事物永远在争议中成长,name百度的也没帮助我解决,最后重启三台机器,问题解决:
2018/4/8,记录,如果重启没有解决问题,可以将自己建的data目录下面的zookeeper_server.pid文件删除后重新启动。记住关闭防火墙。
1 JMX enabled by default// 2 Using config: /home/hadoop/zookeeper-3.4.5/bin/../conf/zoo.cfg 3 Error contacting service. It is probably not running.
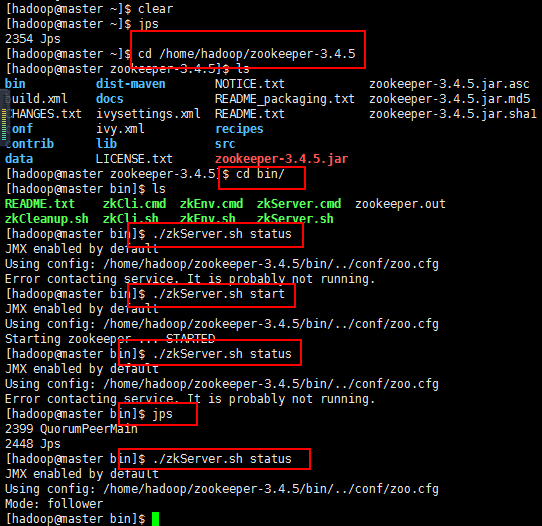
上面的是master节点的,下面的是slaver1节点和slaver2节点的(对于出现这个启动不了的问题,我是这样想的,如果百度的方法不行,就重启一下,
重启以后我开始启动master节点的,然后查看状态,肯定没启动起来,正常,查看一下进程jps,
然后启动slaver1节点的,然后查看状态,肯定没启动起来,正常,查看一下进程jps,
然后启动slaver2节点的,然后查看状态,肯定启动起来,正常,查看一下进程jps,正常,
如果没启动起来,估计问题不好弄了都,我的就解决到这里吧!):
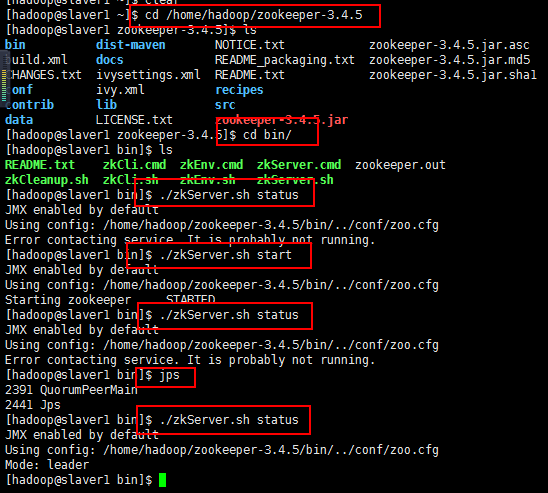
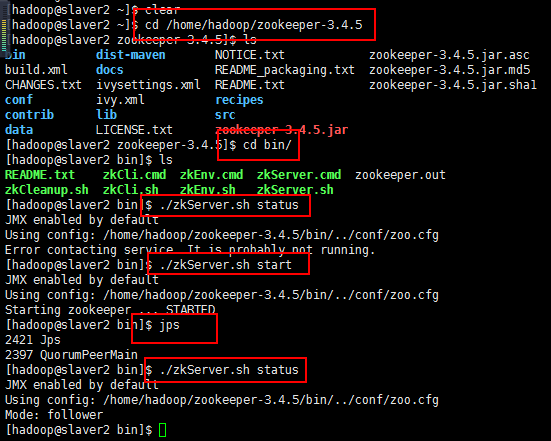
8:至此,Zookerper集群就启动起来了,然后就可以通过java的api往里面写数据,注入分布式应用让Zookerper协调的数据,或者使用命令行的客户端zkCli.sh模式,zkCli.sh连到集群上面去访问数据,可以用来做测试(不带参数连接到本节点上面去):

Connecting to localhost:2181
2017-10-11 02:39:39,035 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.5-1392090, built on 09/30/2012 17:52 GMT
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:host.name=slaver2
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.7.0_65
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/home/hadoop/jdk1.7.0_65/jre
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/home/hadoop/zookeeper-3.4.5/bin/../build/classes:/home/hadoop/zookeeper-3.4.5/bin/../build/lib/*.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/slf4j-log4j12-1.6.1.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/slf4j-api-1.6.1.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/netty-3.2.2.Final.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/log4j-1.2.15.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/jline-0.9.94.jar:/home/hadoop/zookeeper-3.4.5/bin/../zookeeper-3.4.5.jar:/home/hadoop/zookeeper-3.4.5/bin/../src/java/lib/*.jar:/home/hadoop/zookeeper-3.4.5/bin/../conf:
2017-10-11 02:39:39,041 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/i386:/lib:/usr/lib
2017-10-11 02:39:39,041 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2017-10-11 02:39:39,041 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA>
2017-10-11 02:39:39,044 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2017-10-11 02:39:39,044 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=i386
2017-10-11 02:39:39,044 [myid:] - INFO [main:Environment@100] - Client environment:os.version=2.6.32-358.el6.i686
2017-10-11 02:39:39,044 [myid:] - INFO [main:Environment@100] - Client environment:user.name=hadoop
2017-10-11 02:39:39,045 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/home/hadoop
2017-10-11 02:39:39,046 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/home/hadoop/zookeeper-3.4.5/bin
2017-10-11 02:39:39,047 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMainMyWatcher@1a685aeWelcometoZooKeeper!2017−10−1102:39:39,096[myid:]−INFO[main−SendThread(localhost:2181):ClientCnxnMyWatcher@1a685aeWelcometoZooKeeper!2017−10−1102:39:39,096[myid:]−INFO[main−SendThread(localhost:2181):ClientCnxnSendThread@966] - Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181. Will not attempt to authenticate using SASL (unknown error)
JLine support is enabled
2017-10-11 02:39:39,111 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxnSendThread@849]−Socketconnectionestablishedtolocalhost/0:0:0:0:0:0:0:1:2181,initiatingsession2017−10−1102:39:39,241[myid:]−INFO[main−SendThread(localhost:2181):ClientCnxnSendThread@849]−Socketconnectionestablishedtolocalhost/0:0:0:0:0:0:0:1:2181,initiatingsession2017−10−1102:39:39,241[myid:]−INFO[main−SendThread(localhost:2181):ClientCnxnSendThread@1207] - Session establishment complete on server localhost/0:0:0:0:0:0:0:1:2181, sessionid = 0x35f0ac132690000, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
连接到本节点的2181端口之后向集群里面写任何数据,在另外两个节点都可以看到(Zookerper管理客户所存放的数据采用的是类似于文件树的结构):
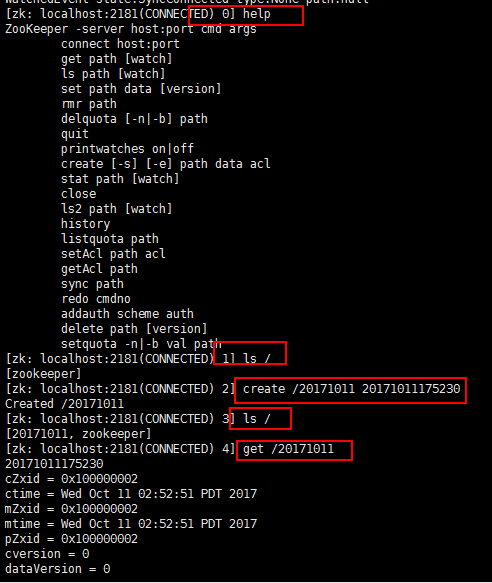
在其他节点也可以看到的:

9:ssh远程开启Zookeeper服务:
[root@master bin]# ssh slaver2 "source /etc/profile;/home/hadoop/soft/zookeeper-3.4.5/bin/zkServer.sh start"
10:Zookeeper启动自动化脚本:
#export a=1 定义的变量,会对自己所在的sheel进程及其子进程生效。 #a=1 定义的变量,只对自己所在的sheel进行生效。 #在script.sh中定义的变量,在当前登陆的sheel进行中,source script.sh时,脚本中定义的变量也会进入当前登陆的进程 #!/bin/bash echo "start zkServer..." for i in 1 2 3 do ssh slaver$i "source /etc/profile;/home/hadoop/soft/zookeeper-3.4.5/bin/zkServer.sh start" done
个人配置自动化脚本执行的操作步骤:
首先在我个人喜欢的目录下面/home/hadoop目录下面创建一个叫做脚本的文件夹,script,然后将自动化脚本拷贝到新建的startzk.sh文件中,然后配置环境变量:
export JAVA_HOME=/home/hadoop/soft/jdk1.7.0_65 export ZOOKEEPER_HOME=/home/hadoop/soft/zookeeper-3.4.5 #自动化脚本的目录 export SCRIPT=/home/hadoop/script #添加到全局环境变量中即可。 export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$SCRIPT
然后在任意目录,执行startzk.sh就可以启动三台Zookeeper了。
但是呢,如果上面你都弄好了,自动化脚本写好了,环境变量配置好了,使用的使用,出现如下问题:
bash: /home/hadoop/script/startzk.sh: Permission denied
上面问题,老司机一眼就明白要干嘛了,那么现在使用chmod 777 startzk.sh命令和chmod 777 stopzk.sh命令赋予你的脚本执行权限即可。
注意:配置好自动化脚本,按tab键不自动弹出,可能是不可以执行的问题,可以赋予文件相应执行权限即可。
待续.....