
《深入理解计算机系统》学习笔记与总结
首先一个大的总结:在计算机中,使控制流发生突变的源头被称为异常控制流。异常是分为多个层级的,硬件异常与软件异常。我们在讨论异常的处理时也应该分情况讨论。异常控制流存在的逻辑是:我们的程序除了需要对程序内部状态的变化做出反应外,也应该可以对系统状态的变化做出反应。
而系统状态的变化可能都不是来自程序自身,无法被程序内部捕获。对于这类外部异常状态的变化需要由硬件捕获或者操作系统捕获,后反馈给处理程序。
硬件异常是由硬件与操作系统合作来进行处理的,比如处理器定义的异常以及中断(来自系统调用、I/O设备信号等)。该类异常由硬件捕获,处理器捕获异常后会直接跳转到异常处理程序对异常进行处理。而异常处理程序的指定与实现是由操作系统完成的。
软件异常又可以细分为内核异常与应用层异常。内核异常是由操作系统内核捕获并反馈的,如windows的SEH。除硬件可以直接捕获并反馈给操作系统的异常外,操作系统通常通过返回值判断是否出现了异常,并通过结构化的处理方式对异常进行处理。而应用层异常由应用定义并捕获处理,如C语言的setjmp与longjmp。C++与JAVA的try catch 机制可以看做是setjmp与longjmp更加结构化的版本。可以将catch看做类似setjmp的函数而throw就是类似longjmp的函数。
异常发生的层级不同,异常的处理和传播过程也是不同的,应该区分开来分析。
对于异常的处理,OS的处理与应用层级的处理应该分开来看。以一个除零异常为例子,这是处理器的四大故障之一,由处理器检查并捕获。
处理器捕获到故障的发生,如果处理器蠢一点会怎么办,会直接跑飞或者停机。聪明一点的办法便是通过IDT找到异常向量表并跳转到操作系统的异常处理程序。
操作系统通过异常处理程序拿到了异常,蠢一点的做法便是蓝屏。聪明点的做法是将异常告知应用程序,由应用程序处理。如果应用程序处理不了,再由操作系统处理。告知应用程序的方式就是向进程发送一个信号,将控制交回给进程时,进程会先对信号做出响应,运行信号处理程序。
如果信号的默认行为为终止进程且进程未修改该信号的对应行为,则进程直接终止。
如果进程为该信号注册了更聪明的处理函数,则执行该函数,执行完后继续运行程序或退出进程。
对于硬件级的异常,操作系统进行了对应的封装,异常通过异常处理程序传播到了操作系统。对于操作系统自定义的异常,是在操作系统层级靠返回值判断并抛出的,通过信号传播到了应用程序(也不一定,如windows的SEH就是应用向操作系统注册处理函数而不是通过信号通知)。而对于应用层级自定义的异常,则需要应用层级自己判断并抛出了。
比如linux下,JVM修改了对linux的各种异常信号的默认行为,当发生这些内核级异常时,JVM内部都通过信号处理函数将其对应成了JAVA的异常类型,并在信号处理函数内部对异常进行了处理。而在JAVA中我们自定义的一个异常,在try块中是不能被自动的检测到的,因为其不会被操作系统发现并通知JVM,必须由我们自己显式的throw。
JVM为每个函数都分配了一个异常表,表中详细记录了每种异常生效的 try 块的范围。一旦一个异常传播到了JVM,JVM首先检查函数的异常表,发生异常的指令是否在该异常生效的范围内,如果不在则在上层调用函数的异常表中继续寻找。找到了处理该异常的函数层级,记录堆栈信息后将后续被调函数的栈清空(栈展开)并在该层执行catch块中的处理程序。
对于final关键字是一个语法糖,在编译期会将final中的代码在try块与catch块中都拷贝一份,无论执行到那一个块,都会执行final。也就是说,同样的代码我们在try块与catch块写两遍与使用fianl的效果是一样的(try或catch中有return另说),编译期帮我们做到了这一点。
再来说 try 中有 return 的情况,final依然会执行,这是很有意思的一点。JVM规范中提到,如果try中有return语句,会先将待return的值存在一个一个本地变量中,执行完final后return这个临时变量的值。而当try与final中均有return时,会忽略try的return。
比如下面的程序会返回0,虽然final试图改变返回的值:
public static int test(){ int i=0; try{ return i; }catch(Exception e){ e.printStackTrace(); }finally{ i=9; } return 10; }
而下面的程序,会返回9,因为final中存在return所以忽略了try中的return:
public static int test(){ int i=0; try{ return i; }catch(Exception e){ e.printStackTrace(); }finally{ return 9; } }
大总结结束,另外针对Java对异常处理进行一下延伸:
如上面所说,异常可能会定义和发生在各个层面。比如硬件层定义的异常由硬件层感知,并通知操作系统由操作系统进行处理;操作系统层定义的异常在调用系统函数时发生,并由操作系统进行直接处理或委托用户进程处理;而应用层定义的异常由用户层自行判断和感知,由应用层自行决定如何处理。异常,即为发生在各个层面的可预料或不可预料的逻辑错误,而异常处理则是异常的定义层面向异常的处理层面发送通知请求其处理的过程。在应用层,如Java中,异常的抛出和捕获也是一样的概念。
异常的处理总是包含了异常的抛出、异常的捕获并处理两个动作。何时捕获、何时抛出是异常处理时不可避免的重要问题。总的来说,异常的捕获和处理需要遵循以下三个原则:
- 具体明确
- 提早抛出
- 延迟捕获
对于 1 不再细说,对于2,提早抛出:
提早抛出的基本目的还是为了防止问题扩散,这样出现异常的话排查起来会比较耗时,比较典型的一种情况是 NPE(NullPointerException),当某个参数对象为null时,如果不提早判断并抛出异常的话,这个null可能会藏的比较深,等到出现NPE时就需要往回追溯代码了。这样就给排查问题增加了难度。所以我们的处理原则是出现问题就及早抛出异常。比如我们的调用层级较深时,我们应当在外层提早预测可能出现的异常并进行抛出,防止错误的逻辑进入下层代码,避免出现问题在向下扩散的过程中出现更多的不确定性,降低异常的排查难度。
而对于3.延迟捕获:
当异常发生时,不应立即捕获,而是应该考虑当前作用域是否有有能力处理这一异常的能力,如果没有,则应将该异常继续向上抛出,交由更上层的作用域来处理。比如我们在MVC模型下,Dao层出现异常我们不应该捕获,而应该抛出给 Service 层。因为同样的一个错误比如 NPE 出现在 Dao 层时,Service 层的不同业务逻辑可能需要对异常做出不同的动作,Dao 层并不清楚它是在Service层中何种情景发生了异常,这种情况下,只需要将异常抛出给Service层,由Service层酌情进行更加合理的处理。
下面开始正文:
1.什么是异常控制流
在操作系统层面,最简单的一种控制流是一个平滑的序列,执行的相邻指令在内存中也是相邻的。
造成控制流的突变(执行的相邻指令在内存中是不相邻的),通常是由跳转、调用和返回这些熟悉的指令造成的,这些指令的存在使得程序可以对由程序变量表示的程序内部状态的变化做出反应。
除了对程序内部状态的改变做出反应外,程序也应该能对系统状态的变化做出反应。系统状态的变化并不一定来自程序自身,也并不能被内部程序变量捕获。比如,一个磁盘IO完成后磁盘发出中断信号通知进程继续执行、一个时钟中断信号通知CPU进行进程调度、一个子进程终止并使其父进程得到通知。
现代操作系统通过使控制流发生突变来对这些情况做出反应。一般而言,我们把这些突变称作“异常控制流”(Exception Control Flow,EFC)。
异常控制流是发生在计算机系统的各个层次的,比如:
在硬件层,硬件检测到事件(如中断、指令异常)会触发控制突然转移到异常处理程序。
在操作系统层,内核通过上下文切换将控制从一个进程转移到另一个进程(进程调度)。
在应用层,一个进程可以发送信号给另一个进程,而接收者会将控制突然转移到它的一个信号处理程序。
一个程序可以回避通常的栈规则,并执行到其它函数中任意位置的非本地跳转来对错误做出反应。(像C++、JAVA通过try、catch、throw来提供软件异常机制。软件异常允许程序进行非本地跳转来响应错误情况,是一种应用层ECF)。
应用程序与操作系统的交互都是基于ECF的,其中异常位于硬件与操作系统的交界处,信号位于操作系统与应用的交界处,而非本地跳转是应用层的一种EFC形式。
2.异常
2.1 异常概述
异常是EFC的一种形式,它一部分由硬件实现,一部分由操作系统实现。
异常是为了响应处理器中某种状态变化的控制流的突变。在处理器中,状态被编码为不同的位和信号,状态的变化成为事件(event)。事件可能与当前执行的指令相关,如缺页异常、除零异常或算术溢出;也可能与当前执行的指令无关,如硬件中断的发生。
但在任何情况下,处理器检测的事件的发生,都会通过一个叫异常表的跳转表进行间接过程调用,到一个专门用来处理该事件的操作系统子程序(异常处理程序(exception handler))。在异常处理子程序执行完后,根据引起异常的事件的类型,会发生以下三种情况之一:
1. 重新执行引发事件的指令。
2. 继续执行引发事件指令的下一条指令。
3. 终止引发事件的程序。
在该阶段,处理器对事件进行检测并固定跳转到异常跳转表,而操作系统实现了异常处理的具体程序并在操作系统启动时初始化异常跳转表。操作系统与硬件配合对异常进行处理。
异常处理的基本逻辑如下图所示:
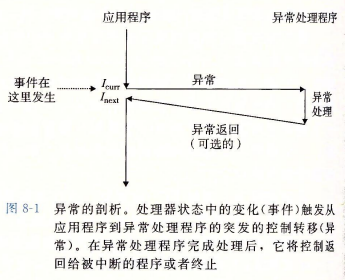
其实无论是硬件异常还是软件异常,处理逻辑均为跳转到一个指定的异常处理程序,即通过控制流的突变对事件作出反应。
区别在于硬件异常由硬件检测并分发给操作系统处理,触发机制为标志硬件状态的状态位。如中断引脚、状态寄存器等。而跳转是由硬件与操作系统配合完成的,硬件将控制转移到一个固定区域进行第一次跳转,操作系统将处理逻辑注册到控制区域,并由这些处理逻辑进行后续跳转。
软件异常是由软件或操作系统定义并检测的,触发机制为系统内的变量或系统外的全局变量,由应用程序内的非本地跳转(如C的setjmp/longjmp)或操作系统的异常处理程序分发(如windows的结构化异常处理SEH)。
2.2 异常的处理
因为异常的处理需要软件与硬件的紧密配合,我们很容易搞混哪个部分执行哪个任务。
系统中的每一个异常都被分配了一个唯一的非负异常号,这些异常有一部分是处理器设计者定义的,有一部分是操作系统设计者定义的。前者包括除零、缺页、内存访问违例、断点以及算数运算溢出。后者包括系统调用和来自I/O设备的信号。
在系统启动时(计算机重启或加电),操作系统分配和初始化一张称为异常表的跳转表,使得表目k包含异常k的处理程序的地址。
在运行时,处理器检测到发生事件,并确定异常号。随后处理器触发异常,方法是执行间接过程调用,经过异常表目k跳转到异常处理程序。
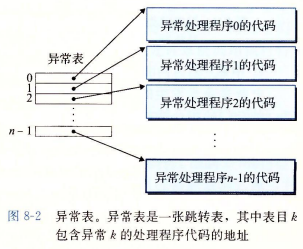
异常表的基址存放在一个叫异常表基址寄存器的CPU特殊寄存器中。
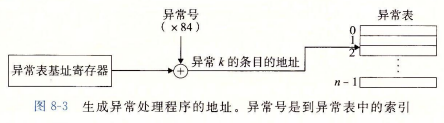
一旦硬件触发了异常,剩下的工作是由异常处理程序在软件中完成。在程序处理完后,通过一个“从中断返回”的特殊指令可选的返回到被中断的程序,该指令将适当的状态弹回到处理器的控制和数据寄存器中。
2.3 异常的类别
异常可以分为四类:故障(fault)、中断(interrupt)、终止(abort)和陷阱(trap)。

中断
中断我外面有专门的博客写过,略。
陷阱和系统调用
陷阱是有意的异常。可以理解为,我们用一条指令触发了中断(或者说模拟了中断)。就像中断处理程序一样,陷阱处理程序将控制返回给下一条指令。
陷阱最重要的用途是在用户程序和系统内核之间提供一个像过程一样的接口,叫做系统调用。
可以想象,通过陷阱指令触发一个中断。CPU通过异常表找到对应的内核处理程序,执行完后控制权返回给下一条指令。该过程虽然涉及到了用户态到内核态的转换,但对于程序编写者来说,执行与调用过程与调用了一个本地的函数并没有区别。
用户程序经常需要向内核请求服务,如读文件(read)、创建新进程(fork)、加载一个新程序(execve)或终止当前进程(exit)。为允许对这些内核服务的受控访问,处理器提供了一个特殊的指令 “syscall n” ,当用户程序想要请求服务 n 时,可以执行者条指令。
故障
故障由错误引起,它可能会被异常处理程序修正。如果可以修正,控制返回到引起故障的指令并重新执行(如缺页异常杨),否则返回内核的abort例程终止该应用程序。
终止
由不可恢复的致命错误造成。如 DRAM 或 SRAM 位损坏时造成的奇偶错误。终止处理程序从不将控制返回应用程序而是直接终止应用程序。
2.4 Linux/x86-64 异常类型
在 x86-64 系统中有高大 256 种异常。其中 0-31 号异常是由Intel架构师定义的,对任何 x86-64 系统都是一样的。32-255 号码对应的是操作系统定义的中断或陷阱。
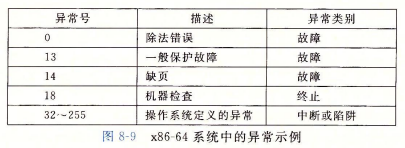
Linux/x86-64中的故障和终止
除法错误:浮点异常。
缺页异常:会加载所缺页并重新执行引起该异常的指令。
一般保护故障:段故障。尝试访问非法地址或写入只读地址等内存错误。
机器检查:致命硬件错误。
Linux/x86-64中的系统调用
在x86-64系统上,通过一个syscall指令进行系统调用。所有到 linux 系统调用的参数都是通过寄存器传递的而不是栈。按照惯例 %rax 包含系统调用号,%rdi,%rsi,%rdx,%r10,%r8 和 %r9 包含最多6个参数。第一个参数在 %rdi 中,第二个参数在 %rsi 中,以此类推。
调用返回时,%rcx 和 %r11 都会被破坏,%rax 包含返回值,-4095到-1之间的负数值代表发生了错误。对应于负的 errno 。

比如一个简单的系统调用,先设置寄存器的值后执行 syscall 指令:

当 Unix 系统级函数遇到错误时,它们通常会返回 -1 ,并设置全局的 errno 变量标识错误类型,我们应该总是检查错误是否发生。该处的返回 -1 是函数逻辑的结果,我们可以将其作为异常控制流(可以作为异常的源头进行抛出),进行异常处理。
3.信号
相对于前面所说的硬件与软件的配合实现的基本的低层异常机制,信号是一种更高层的软件形式的异常。它允许进程和内核中断其它进程。
信号就是一个小消息,它通知进程系统发生了一个某种类型的事件。比如下面是linux中的一些信号: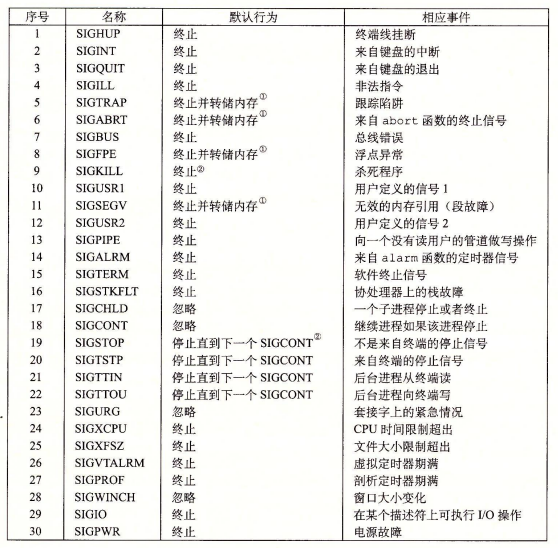
传送一个信号到目的进程是由两个不同的步骤组成的。
发送信号:内核通过更新进程上下文中的某个状态,发送一个信号给目的进程。发送信号有如下两种原因:
1. 内核检测到一个事件,如除0错误或子进程终止。
2. 一个进程调用了 kill 函数。
接收信号:当目的进程被内核强迫以某种方式对信号的发送做出反应时,它就接收了信号。进程可以忽略这个信号、终止或者通过执行一个叫做信号处理函数的用户层函数来捕获该信号。
当内核把进程p从内核模式切换到用户模式时(如从系统调用返回或者进行了一次进程调度),它会检查p的待处理信号集合。由于进程调度的存在,使得信号响应的时效性得到了一定的保障。每个信号都有一个预定义的默认行为,是下述四种情况之一:
进程终止、进程终止并转储内存、进程挂起直到被SIGCONT信号唤醒、进程忽略该信号。
进程可以使用 signal 函数修改信号关联的默认行为。唯一的例外是SIGKILL 和SIGSTOP ,它们的默认行为不能被修改。

signal函数可以通过下述三种方式改变与信号signum关联的行为:
1. 如果 handler 为 SIG_IGN,则行为为忽略signum。
2. 如果 handler 为SIG_DFL,则恢复signum的默认行为。
3. 否则,handler就是用户自定义的函数的地址,这个函数被称为信号处理程序。只要进程接收到一个类型为signum的信号则会调用该程序。
下图中我们将处理 SIGINT 信号的行为改为输出一条消息后退出进程:

信号处理程序可以被其它信号处理程序中断,逻辑如下图所示:
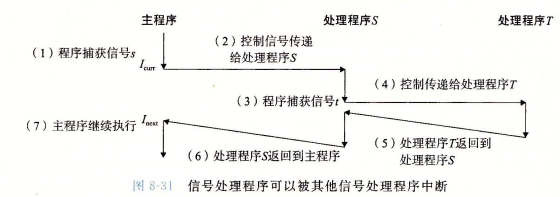
信号有一个有违直觉地方就是同类型的信号是不会排队的,如果排队信号中已有了一个信号k,那么再来的信号k就会被简单的丢弃。一个典型的例子便是在子进程结束通知父进程时,如果有多个子进程的结束信号 SIGCHLD 同时到达父进程,那么会有部分信号被丢弃。未被处理的子进程则变成了僵死进程。
所以每当父进程接收到一个 SIGCHLD 信号时并不代表只有一个子进程结束了,而是代表至少有一个子进程结束了。其它信号也是如此,在linux中,如果父进程接收到一个 SIGCHLD 信号,并不是回收一个子进程,而是尽可能多的回收结束的子进程。
另外因为信号是可以穿插在进程的运行过程中的任意阶段执行的,所以会带来一些并发问题。比如 fork 函数,父进程创建子进程并在进程表种种添加子进程。如果创建子进程之后,在进程表中添加子进程之前,父进程被时钟信号打断转而执行子进程,而子进程在这一次时钟时间内结束并向父进程发送SIGCHLD
信号。那么当父进程再次被调度时,会先响应信号删除表中的子进程,而此时表中还没有子进程。响应完信号后父进程才执行将子进程加入进程表的操作,而此时子进程已经不存在了。
这是一个称为竞争(race)的经典同步错误示例。目前的解决方法是在执行 fork 函数时先显示的禁止对信号的响应(显示的阻塞信号),然后在将紫禁城添加到进程表后解除阻塞,以此来避免类似的并发问题。
在通常的并发编程中,我们的重点在于不同线程对共享变量的访问安全问题。而在信号带来的并发问题中(信号处理程序与源程序的并发),我们关注的重点是信号处理程序可能在逻辑流的任意时刻执行,因为我们无法预知进程的调度时间,如果某一信号的处理会导致某个函数的逻辑错乱,那么在执行该函数前我们应该阻塞对信号的处理,函数执行结束时再恢复对该信号的响应。
4.非本地跳转
C语言提供了一种用户级异常控制流形式,称为非本地跳转。
受限于栈规则,普通的跳转指令如 goto 仅能将控制转移到当前执行函数内部的某处代码处。而非本地跳转无视栈规则,直接将控制从一个函数转到另一个当前正在执行的函数,而不需要经过正常的调用-返回序列。
非本地跳转是通过 setjmp 和 longjmp 提供的。

setjmp 在 env 缓冲区中保存当前环境,已供 longjmp 调用恢复到当前的执行节点。longjmp可以显式的改变 setjmp 的返回值。
setjmp有违直觉的地方是这个函数被调用了一次却返回了两次。但真正的情况是,setjmp被调用了两次,一次是我们在代码中进行的显式调用,返回0。另一次是longjmp 跳转到当前执行节点后(这个节点是setjmp第一次执行的节点),setjmp再次被执行,并返回了不同的结果,这个结果是 longjmp 指定的。
非本地跳转的一个重要作用是允许从一个深层嵌套的函数中立即返回(这里如果不理解看一下函数调用时栈的变化过程),通常是由检测到某个错误引起的。如果一个深层嵌套的函数发生错误,我们可以直接使用非本地跳转将控制返回到一个普通的本地化错误处理程序,而不是费力的解开调用栈。
longjmp 允许所有中间调用的特性可能导致的后果。比如中间调用函数中分配了某些数据结构,本来打算在函数调用结尾释放它们,那么这些释放代码会被跳过,因而产生内存泄漏。
非本地跳转的另一个重要应用是使信号处理程序分支到一个特殊的程序位置,而不是被信号处理程序中断的指令位置。比如下述代码实现了使用 SIGINT 信号对应用的重启:

执行结果:

下面是一个C语言中使用非本地跳转处理除0异常的例子:
#include<stdio.h> #include<stdlib.h> #include<setjmp.h> int divide(int a, int b, jmp_buf jmpBuf){ char *s = (char *)malloc(sizeof(char) * 10); if(b == 0){ free(s); printf("b == 0 "); longjmp(jmpBuf,1); } printf("b != 0 "); return a/b; } int main(int argc, char const *argv[]) { jmp_buf jmpBuf; if( (setjmp(jmpBuf)) !=0 ){ printf("divide by zero "); goto end; } divide(10,0,jmpBuf); end: return 0; }
下面我们再来看一下 JS 中处理异常的代码:
var longJump=function(reason){ try{ var result=1/reason; if(reason===10){ throw new Error("值为10"); } if(reason===20){ throw new Error("值为20"); } console.log(result); }catch(err){ console.log("错误信息为 : "+err.message); } } longJump("sss"); longJump(10); longJump(20);
对于 JS 解释器或更底层所捕获的异常,由底层直接通过信号将发生的异常通知进程,进行异常的处理。但未被底层定义的逻辑错误必须由我们自己创建异常对象进行处理,其实底层定义的异常也是底层的逻辑错误。我们想一下,硬件层定义的异常由硬件层反馈给操作系统,操作系统进行处理(操作系统也会有委托用户进程处理异常的逻辑,比如windows中我们注册异常处理程序);操作系统定义的异常在调用系统函数时触发,陷入异常处理流程,由操作系统通过信号反馈给相关进程,进程进行处理;而进程层面的逻辑错误,由我们自己判断和处理。
异常处理的过程是一个层层递进,由异常定义层到异常处理层的向上反馈和委托的过程。