一、Hadoop介绍
一个开发和运行处理的大规模是数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
1.Hadoop特性优点
●扩容能力(Scalable):
Hadoop 是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
●成本低(Economical ):
Hadoop 通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
●高效率(Efficient):
通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
●可靠性(Rellable):
能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy) 计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
Hadoop特性缺点
不支持高并发写入和任意的修改
无法高效的存储大量小文件(默认128M)
不适合处理低延迟的数据访问
2.Hadoop的核心组件有:
HDFS(分布式文件系统)
MAPREDUCE(M2:分布式运算编程框架)
YAEN(运算资源调度系统)
3.分布式系统概念:分布式系统是由一组通过网络进行通信,为了完成共同的任务而协调工作的计算机节点组成的系统。
*目的:分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储服务,是利用更多的机器,处理更多的数据。
4.Hadoop集群中,需要启动的进程:
*1. NameNode,它是hadoop. 中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有metadate。
*2. SecondaryNameNode它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并editslog,减少NN启动时间。
*3. DataNode,它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。
*4. ResourceManager, (JobTracker) JobTracker. 负责调度DataNode上的工作。每个DataNode有一个TaskTracker,它们执行实际工作。
*5. NodeManager, (TaskTracker)执行任务
6. DFSZKFailoverControl1er高可用时它负责监控NN的状态,并及时的把状态信息写入ZK.它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN 的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
7. Journa1Node.高可用情况下存放namenode的editlog文件.
二、Hadoop 2.0
Hadoop 2.0包含一个支持NameNode横向扩展的HDFS,一个资源管理系统 YARN 和一个运行在 YARN 上的离线计算框架MapReduce。相比于Hadoopl.0,Hadoop 2.0功能更加强大,且具有更好的扩展性、性能,并支持多种计算框架。
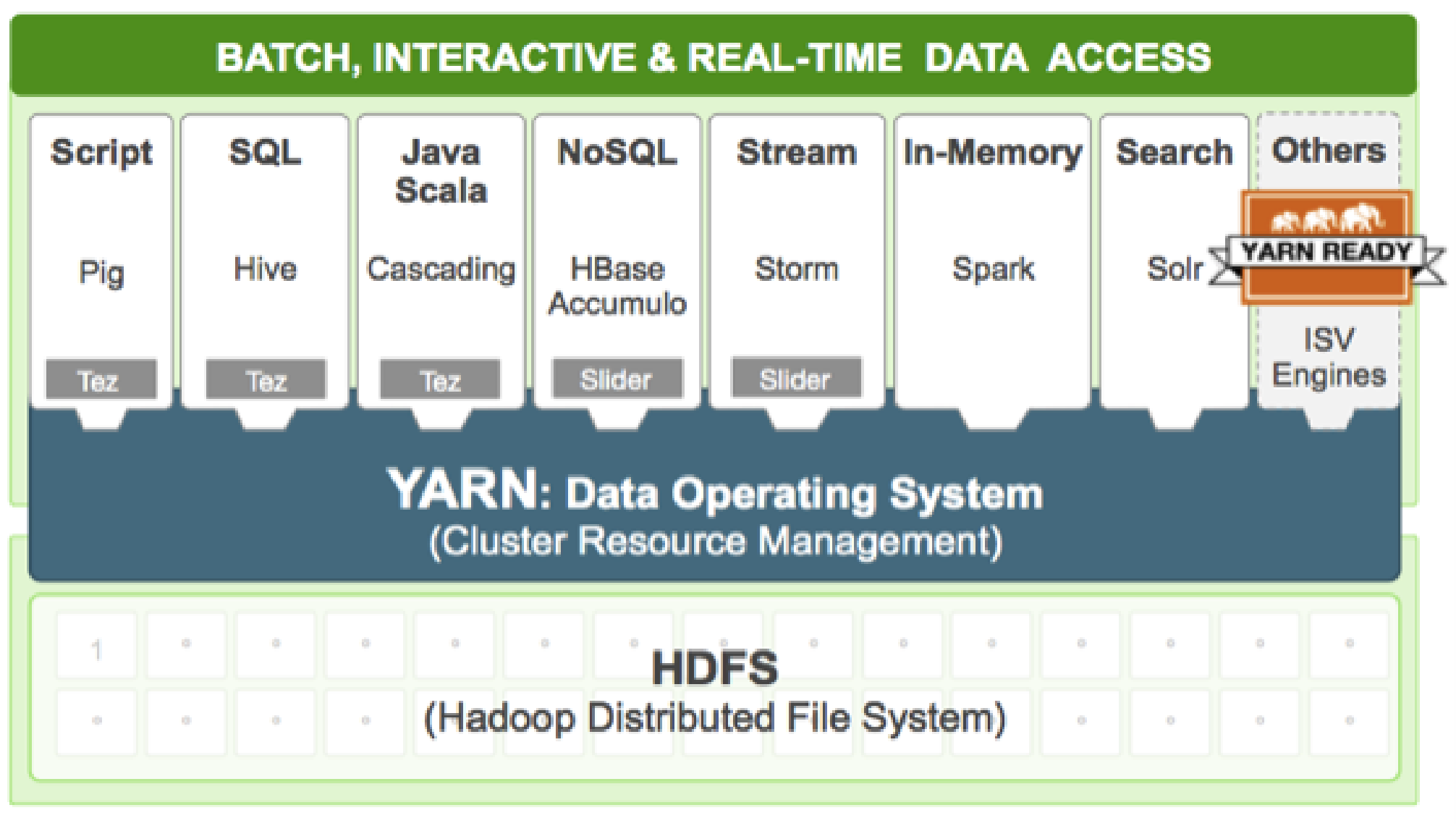
1.集群简介
●HADOOP集群具体来说包含两个集群:
HDFS集群
YARN集群
两者逻辑上分离,但物理上常在一起。
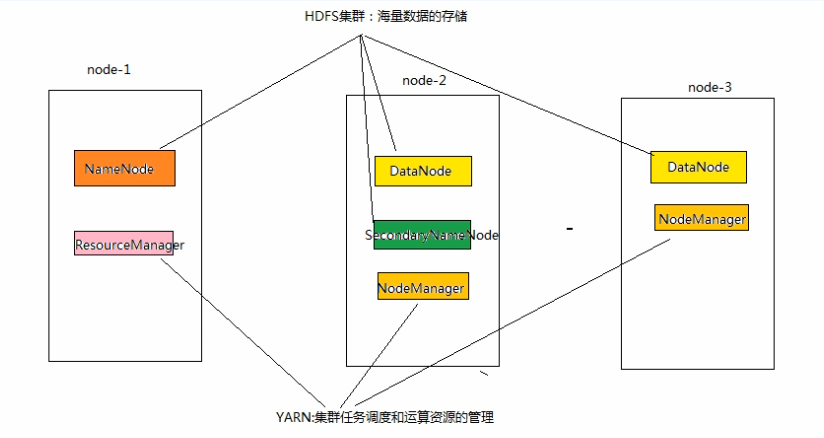
●HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
●YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
Mapreduce 是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
2.Hadoop 的部署方式
Hadoop部署方式分三种, Standalone mode(独立模式).Pseudo-Distributedmode(伪分布式模式)、Clustermode(群集模式),其中前两种都是在单机部署。
●独立模式
又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
●伪分布模式
也是在1个机器上运行HDFS的NameNode和DataNode、YARN 的 ResourceManger和NodeManager,但分别启动单独的java 进程,主要用于调试。
●集群模式
主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
三、HDFS 分布式文件系统
●HDFS写入文件的流程
1.客户端首先通过DistributedFileSystem对象的create方法创建一个FSDataOutputStream(输出流)对象;
2.客户端通过DistributedFileSystem对象向NameNode发起一次RPC调用,在HDFS的Namespace中创建一个文件条目;
3.通过FSDataOutputStream对象,向DataNode写入数据,数据首先被写入FSDataOutputStream对象内部的Buffer中,然后数据被分割成一个个Packet数据包;
4.以Packet最小单位,基于Socket连接发送到按特定算法选择的HDFS集群中一组DataNode中的一个节点上,在这组DataNode组成的Pipeline(数据量管道)上依次传输Packet;
5.这组DataNode组成的Pipeline反方向上,发送ack,最终由Pipeline中第一个DataNode节点将Pipeline ack发送给客户端;
6.完成向文件写入数据,客户端在FSDataOutputStream对象上调用close方法,关闭流;
7.调用DistributedFileSystem对象的complete方法,通知NameNode文件写入成功。
●HDFS读取文件的流程
1、与NameNode通信查询元数据,找到文件块所在的DataNode服务器
2、挑选一台DataNode(网络拓扑上的就近原则,如果都一样,则随机挑选一台DataNode)服务器,请求建立socket流
3、DataNode开始发送数据(从磁盘里面读取数据放入流,以packet(一个packet为64kb)为单位来做校验)
4、客户端以packet为单位接收,先在本地缓存,然后写入目标文件
●HDFS的优点:
1.适合大数据处理
2.处理非结构化的数据
3.流式访问数据,一旦写入不能修改,只能追加
4.运行于廉价的商用机器集群上
5.不适合处理低延迟的数据访问
●HDFS的缺点:
1.无法高效的储存大量小文件
2.不支持并发写入和任意的修改
●HDFS数据存储概念:
HDFS采用Master/Slave主从架构来存储数据,这种架构主要由四个部分组成:
HDFS Client 客户端
NameNode 管理者,下达命令,负责管理整个文件的元数据
DataNode 把数据切割成默认大小(128M),分布式存储
Secondary NameNode 辅助元数据
●HDFS工作机制
hdfs集群分为两大角色: namenode datanode
namenode负责管理整个文件的元数据(命名空间信息,块信息)
datanode负责管理用户的文件数据块相当于salve
文件会按照默认的大小(block= 128m)切成若干块后分布式存储在若干个datanode节点上
四、MapReduce 分布式运算编程框架
MapReduce是一个分布式运算程序的编程框架,是用户开发"基于Hadoop的数据分析应用"的核心框架
MapReduce:映射规约
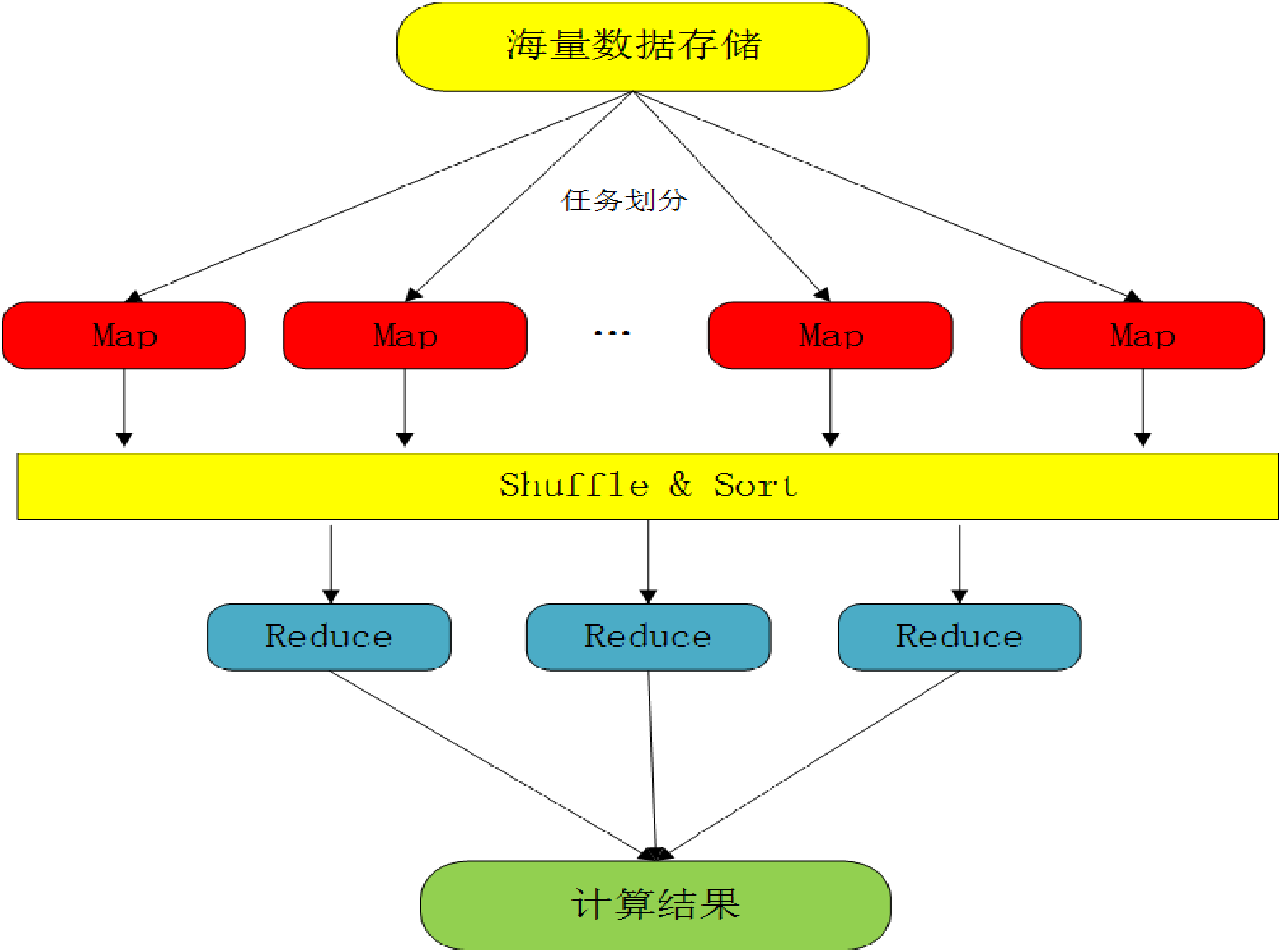
●MapReduce的结构:
MRAppMaster
MapTask
ReduceTask
●MapReduce计算框架

●MapReduce运行流程


●MapTask并行度决定机制
●一个job的map阶段并行度由客户端在提交job时决定
●而客户端对map阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每-个split分配 一个mapTask并行实例处理
●Map Reduce编写规范
用户编写的程序分成三个部分: Mapper, Reducer, Driver(提交运行MR程序的客户端)
Reducer的业务逻辑写在reduce()方法中;
ReduceTask进程对每一组相同k的<k, v>组调用一次reduce()方法
Drvier提交
●FileInputFormat切片机制:
切片定义在InputFormat类中getSplit()方法
●FileIputFormat中默认的切片机制:
简单地按照文件的内容长度进行切片
切片大小,默认等于block大小
切片时不用考虑数据集整体,而是逐个针对每一个文件单独切片
Shuffle的正常意思是洗牌或弄乱。
Shulffle描述着数据从map task输出到reduce task输入的这段过程。
Shuffle就是map和reduce之间的过程。
五、YARN 运算资源调度系统
1.YARN组件及架构介绍—组件
●ResourceManager
RM是一个全局的资源管理器,集群只有一个
两个组件:
调度器Scheduler
应用程序管理器Applications Manager,ASM
●ApplicationMaster
管理YARN内运行的应用程序
功能:
数据切分
为应用程序申请资源并进行进一步分配给内部任务。
任务监控与容错
●Nodemanager
负责节点的资源和使用
单个节点上的资源管理和任务
●Container
封装了某个节点上的多维度资源,如内存,CPU、磁盘、网络,返回的资源用Container表示
2.YARN工作流程-流程
●步骤1
用户将应用程序提交到ResourceManage上。
●步骤2
ResourceManager为应用程序ApplicationMaster申请资源,并与某NodeManager通信,以启动ApplicationMaster。
●步骤3
ApplicationMaster与ResourceManager通信为内部要执行的任务申请资源,一旦得到资源后,将于NodeManager通信,以启动对应的任务。
●步骤4
所有任务运行完成后,ApplicationMaster向ResourceManager注销,整个应用程序运行结束。