菜鸟拙见,望请纠正
一:关系型数据库的设计阶段
1:规划阶段:确定是否需要使用数据库,使用哪种类型的数据库,使用哪个数据库产品。
2:概念阶段:概念阶段的主要工作是收集并分析需求。
识别需求,主要是识别数据实体和业务规则。该阶段将参考或产出多种文档,比如“用例图”,“数据流图”以及其他一些项目文档。该阶段结束要可以回答如下问题。
需要哪些数据?数据该被怎样使用?哪些规则控制着数据的使用?谁会使用何种数据?客户想在核心功能界面或者报表上看到哪些内容?数据现在在哪里?数据是否与其他系统有交互、集成或同步?主题数据有哪些?核心数据价值几何,对可靠性的要求程度?
3:逻辑阶段:逻辑阶段的主要工作是绘制E-R图,或者说是建模。E-R图以描述实体间的关系。还需考虑属性的域(值类型、范围、约束)。
4:实现阶段:实现阶段主要针对选择的RDBMS定义E-R图对应的表,考虑属性类型和范围以及约束。
5:物理阶段:在实际物理设备商部署数据库并测试和调优。
二:设计原则与规范
1:命名规范:
表——“模块名_表名”。表名最好不要用复数,不要过长。
存储过程——使用“proc_”前缀。
视图——使用“view_”前缀。
触发器——使用“trig_”前缀。
2:选择数据类型
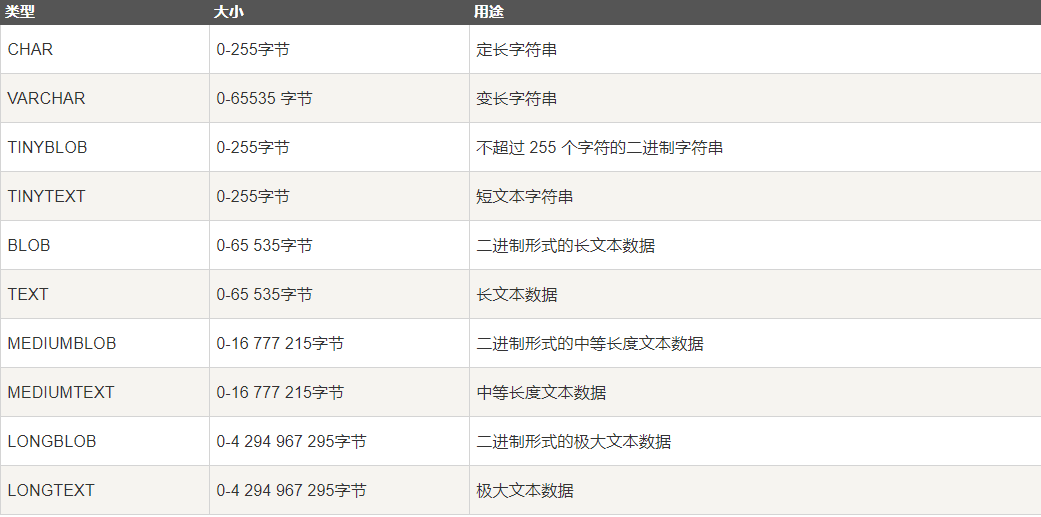
数值类型:
严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
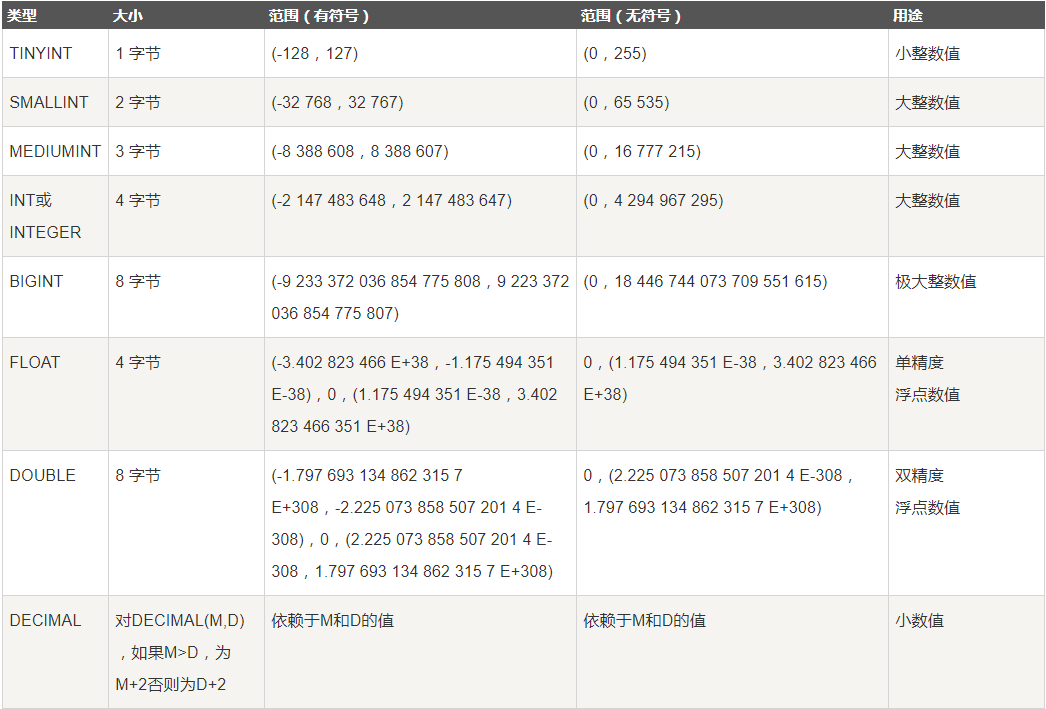
日期和时间类型
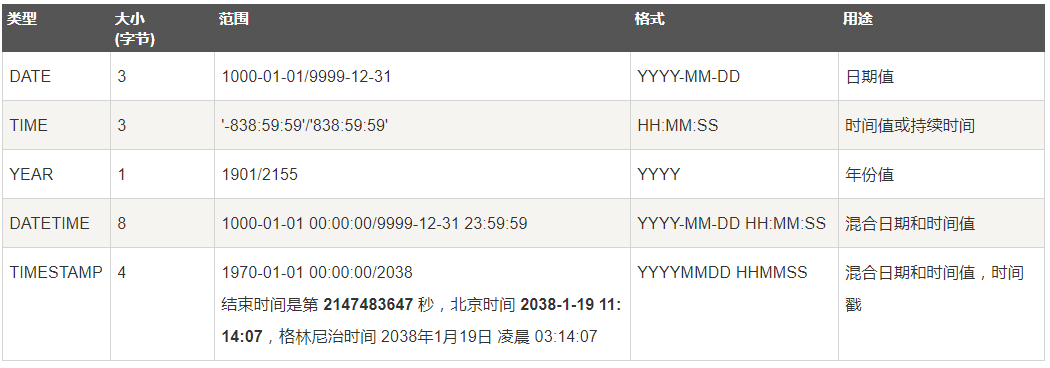
字符串类型
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
3:定义实体关系的原则
当定义一个实体与其他实体之间的关系时,需要考量如下:
牵涉到的实体 :识别出关系所涉及的所有实体。
所有权: 考虑一个实体“拥有”另一个实体的情况。
基数 :考量一个实体的实例和另一个实体实例关联的数量。
关系与表数量
描述1:1关系最少需要1张表。
描述1:n关系最少需要2张表。
描述n:n关系最少需要3张表。
范式将帮助我们来保证数据的有效性和完整性。规范化的目的如下:
消灭重复数据。
避免编写不必要的,用来使重复数据同步的代码。
保持表的瘦身,以及减从一张表中读取数据时需要进行的读操作数量
最大化聚集索引的使用,从而可以进行更优化的数据访问和联结。
减少每张表使用的索引数量,因为维护索引的成本很高。
规范化旨在——挑出复杂的实体,从中抽取出简单的实体。这个过程一直持续下去,直到数据库中每个表都只代表一件事物,并且表中每个描述的都是这件事物为止。
关系模式:
候选键:若一个属性集能唯一标识一个元组,又不含有多余属性,那么这个属性集称为候选键

主键:及设计者设计数据库时选作元组标识的一个候选键
主属性:包含在任一一个候选键的属性称为主属性
函数依赖:某个属性集决定另一个属性集时,称另一属性集依赖于该属性集。
部分函数依赖:
范式:
第一范式:数据库表的每一列都是不可分割的基本数据项,同一列不能有多个值。及每一列不可再分及满足第一范式。
第二范式:在第一范式的基础上,每一个非主属性完全依赖于主关键字。完全依赖及不能存在仅依赖主关键字的一部分属性。

第三范式:在第二范式的基础上,每个非主属性都不传递依赖于候选键时,则为第三范式。
传递依赖:若X→Y,Y→A,并且Y→X,A不是Y的子集,则称A传递依赖于X。及主属性不能通过一个以上的路径走到非主属性。


BC范式:

如果关系模式R的所有不平凡的,完全的函数依赖的决定因素(左边的属性集)都是候选码,则R€BCNF,即左边的都是候选键(注意不是主属性)
如果一个关系模式达到了第三范式,并且它只有一个候选键,或则他的候选键都是单属性,那么就达到了BCNF
三:SQL基础语速记(MySQL)
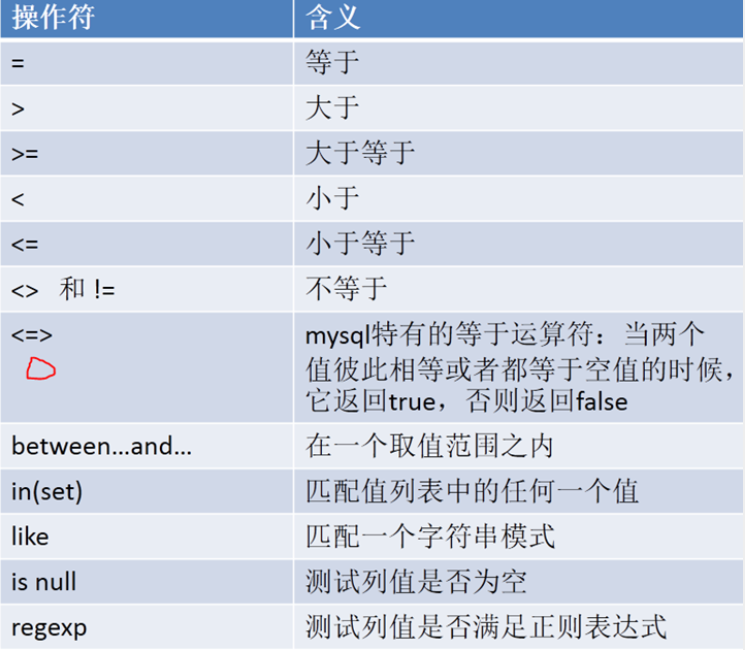
1:操作符
2:常用字符串函数
3:常用数值函数
4:常用日期时间函数
5:分组聚合函数
四:SQL语句速记(MYSQL)
1:增(insert)
基本格式:
insert [into] <表名> (列名1,列名2,列名3,......) values (值1,值2,值3,......);
1):插入一行时,要求必须对该行所有的列赋值。但是赋值方式可以是显式赋值(及将列列出,values 赋予 null )和隐式赋值(及不写出该列,也不写该列的值)
例如:显式赋值 :insert into <表名> (列名1,列名2,列名3) values (值1,null,值3);
隐式赋值:insert into <表名> (列名1,列名3......) values (值1,值3,......);
2):从其他表中复制数据:
例如:insert into <表1> select (值1,值2,值3);
2:删(delect)
基本格式:
delete from <表名> where <条件表达式>;
删除符合条件表达式的行记录
1)注意:不能在delete和from中间指定列名,因为记录要删,总是按照行来删除的,不存在删除一行记录的某几列的值的情况。
2)带查询的删除
例如:
DELETE FROM <表1>
WHERE joined >
(SELECT avg(joined) FROM <表2> WHERE town = 'Stratford');
注意:在WHERE子句的子查询中,不允许访问要删除行的表
3:删除4个最高的罚款
DELETE FROM penalties
ORDER BY amount DESC,playerno ASC
LIMIT 4;
3:改(update)
基本格式
update <表名> set <列名> = <值或值的表达式> where <条件表达式>
例1:把所有罚款增加5%
UPDATE penalties SET amount = amount*1.05;
例2:把住在S 的球员的获胜局数设为0
UPDATE matches
SET won = 0
WHERE playerno IN
(SELECT playerno FROM players WHERE town='S');
例3:多表查询
UPDATE matches m,teams t
SET m.won = 0,t.playerno = 112
WHERE t.teamno = m.teamno
AND t.division = 'first';
4:查(select)
基础关键字
from:来自某张表或则几张表
join:添加某张表
on :表连接查询,每关联一个表就需要加上对应的on条件
group by:分组
mysql> select salary,count(*) from salary_tab
-> where salary>=2000
-> group by salary;
+---------+----------+
| salary | count(*) |
+---------+----------+
| 2000.00 | 1 |
| 3000.00 | 1 |
+---------+----------+
having :聚合条件过滤
order by :排序 ,desc降序,asc升序,默认升序:如:
select * from temp order by id desc;
distinct:去掉重复数据 如: select distinct num from t2;
as :列别名
concat:字符串连接,如查询地址
concat函数,字符串连接
concat_ws函数,指定分隔符的字符串连接
mysql> select id,concat_ws(':',First,Last) "Full Name" from t1;
between v1 and v2:v1和v2之间
in :多个条件查询,类似于or 如:
select * from temp where id in (1, 2, 3);
like:模糊查询,如:
select * from temp where name like ‘%k%’;
limit:从结果集中选取最前面或最后面的几行,通常与order by配合
limit <获取的行数> [OFFSET <跳过的行数>]
limit [<跳过的行数>,] <获取的行数>
mysql> select playerno,name from players order by playerno asc limit 3,5; mysql> select playerno,name from players order by playerno asc limit 5 offset 3; 解析:跳过前面的3行,从第4行开始取,取5行
count:统计行的数量
select count(*) from salary_tab
max和min函数
select min(salary) from salary_tab;
sum和avg函数
select avg(salary) from salary_tab;
多表链接查询
1:内连接 inner join
只返回两张表中所有满足连接条件的行,即使用比较运算符根据每个表中共有的列的值匹配两个表中的行。(inner关键字是可省略的)
①传统的连接写法:
在FROM子句中列出所有要连接的表的名字(进行表别名),以逗号分隔;
连接条件写在WHERE子句中;
注意:一旦给表定义了别名,那么原始的表名就不能在出现在该语句的其它子句中
mysql> select s.sname,c.cname,t.tname,x.xuefen
-> from stu s,tea t,course c,xuanke x
-> where s.sid=x.sid and t.tid=x.tid and c.cid=x.cid;
+--------+--------+-----------+--------+
| sname | cname | tname | xuefen |
+--------+--------+-----------+--------+
| 张三 | linux | 冯老师 | 4 |
| 李四 | linux | 冯老师 | 2 |
| 张三 | mysql | 相老师 | 2 |
| 李四 | mysql | 相老师 | 2 |
| 张三 | hadoop | 相老师 | 6 |
| 李四 | hadoop | 相老师 | 2 |
+--------+--------+-----------+--------+
6 rows in set (0.08 sec)
②使用on子句(常用):
mysql> select s.sname,t.tname,c.cname,x.xuefen
-> from stu s
-> join xuanke x
-> on s.sid=x.sid
-> join tea t
-> on x.tid=t.tid
-> join course c
-> on c.cid=x.cid;
结果如上……
表之间的关系以JOIN指定,ON的条件与WHERE条件相同。
③使用using子句
mysql> select s.sname,t.tname,c.cname,x.xuefen
-> from stu s
-> join xuanke x
-> using(sid)
-> join tea t
-> using(tid)
-> join course c
-> using(cid);
结果如上……
表之间的关系以join指定,using(连接列)进行连接匹配,类似于on。(相对用的会比较少)
2:外链接 outer join
使用外连接不但返回符合连接和查询条件的数据行,还返回不符合条件的一些行。
在MySQL数据库中外连接分两类(不支持全外连接):
左外连接、右外连接。(outer关键字可省略)。
共同点:都返回符合连接条件和查询条件(即:内连接)的数据行
不同点:
①左外连接还返回左表中不符合连接条件,但符合查询条件的数据行。(所谓左表,就是写在left join关键字左边的表)
②右外连接还返回右表中不符合连接条件,但符合查询条件的数据行。(所谓右表,就是写在right join关键字右边的表)
mysql> select s.sname,x.xuefen
-> from stu s
-> left join xuanke x
-> on s.sid=x.sid;
+--------+--------+
| sname | xuefen |
+--------+--------+
| 张三 | 2 |
| 张三 | 4 |
| 张三 | 6 |
| 李四 | 2 |
| 李四 | 2 |
| 李四 | 2 |
| 王五 | NULL |
+--------+--------+
7 rows in set (0.00 sec)
解析:stu表是左表,xuanke表是右表:left join是左连接,stu表中”王五”没有选课,在xueke表中没有数据行,不符合连接条件,返回符合查询条件的数据行,所以xuefen为null。
mysql> select s.sname,x.xuefen
-> from xuanke x
-> right join stu s
-> on x.sid=s.sid;
结果如上(用的是右连接的方式)
给连接查询附加条件:
1、写在WHERE子句中
2、使用AND和连接条件写在一起
但是:
对于内连接,两种写法结果相同;
对于外连接,两种写法结果不同。
mysql> select s.sname,x.xuefen
-> from stu s
-> left join xuanke x
-> on x.sid=s.sid
-> where sname='张三';
+--------+--------+
| sname | xuefen |
+--------+--------+
| 张三 | 2 |
| 张三 | 4 |
| 张三 | 6 |
+--------+--------+
3 rows in set (0.01 sec)
mysql> select s.sname,x.xuefen
-> from (select * from stu where sname='张三') s
-> left join xuanke x
-> on x.sid=s.sid;
+--------+--------+
| sname | xuefen |
+--------+--------+
| 张三 | 2 |
| 张三 | 4 |
| 张三 | 6 |
+--------+--------+
3 rows in set (0.00 sec)
①先连接后过滤
select ……from ……
left join ……
on 连接条件
where 过滤条件;
②先过滤后连接
select ……from (select ……from ……where 过滤条件)
left join ……
on 连接条件;
3:交叉链接——笛卡尔积
因为没有连接条件,所进行的表与表间的所有行的连接。
特点:
①连接查询没有写任何连接条件
②结果集中的总行数就是两张表中总行数的乘积(笛卡尔积)
注意:在实际中,应该要避免产生笛卡尔积的连接,特别是对于大表
mysql> select * from stu,tea,course,xuanke; …… …… 108 rows in set (0.00 sec)
若是想专门产生笛卡尔积,可以使用交叉连接
mysql> select *
-> from stu
-> crosss join tea;
+------+--------+---------+------+-----------+---------+
| sid | sname | sphonum | tid | tname | tphonum |
+------+--------+---------+------+-----------+---------+
| 1 | 张三 | 110 | 1113 | 相老师 | 1111 |
| 1 | 张三 | 110 | 1114 | 冯老师 | 1112 |
| 2 | 李四 | 120 | 1113 | 相老师 | 1111 |
| 2 | 李四 | 120 | 1114 | 冯老师 | 1112 |
| 3 | 王五 | 130 | 1113 | 相老师 | 1111 |
| 3 | 王五 | 130 | 1114 | 冯老师 | 1112 |
+------+--------+---------+------+-----------+---------+
6 rows in set (0.00 sec)
OVER····