原文地址:
http://www.cnblogs.com/wangqiaomei/p/5682669.html
一、queue
二、线程
#基本使用
#线程锁
#自定义线程池
#生产者消费者模型(队列)
三、进程
#基本使用
#进程锁
#进程数据共享
# 默认数据不共享
#queues
#array
#Manager.dict
#进程池
#PS:
#IO密集型-多线程
#计算密集型 - 多进程
四、协程
#原理:利用一个线程,分解一个线程成为多个“微线程”==》程序级别
#greenlet
#gevent
#pip3 install gevent
一、queue
1.1 queue用法
先进先出队列
put放数据,是否阻塞,阻塞时的超时事件
get取数据(默认阻塞),是否阻塞,阻塞时的超时事件
队列的最大长度:queue.Queue(2) 里面的数字
qsize()真实个数
maxsize 最大支持的个数
join,task_done,阻塞进程,当队列中任务执行完毕之后,不再阻塞
import queue
q = queue.Queue(2) # q = queue.Queue()如果没有参数的话,就是可以放无限多的数据。
print(q.empty()) # 返回队列是否为空,空则为True,此处为True
q.put(11)
q.put(22)
print(q.empty()) # 此处为False
print(q.qsize()) # 返回队列中现在有多少元素
# q.put(22)
# q.put(33,block=False) # 如果队列最大能放2个元素,这时候放了第三个,默认是阻塞的,block=False,如果就会报错:queue.Full
# q.put(33,block=True,timeout=2) # 设置为阻塞,如果timeout设置的时间之内,还没有人来取,则就会报错:queue.Full
print(q.get())
print(q.get())
print(q.get(timeout=2)) # 队列里的数据已经取完了,如果再取就会阻塞,这里timeout时间2秒,就是等待2秒,队列里还没有数据就报错:queue.Empty
1.2 queue.join
join:实际上意味着等到队列为空,再执行别的操作,否则就一直阻塞,不是说get取完了,就不阻塞了,而是每次get之后,
要执行:task_done 告诉一声已经取过了,等队列为空,join才不阻塞。
q = queue.Queue(5)
q.put(123)
q.put(456)
q.get()
# q.task_done()
q.get()
# q.task_done() # 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
q.join()
q = queue.Queue(5)
q.put(123)
q.put(456)
q.get()
q.task_done()
q.get()
q.task_done() # 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
q.join()
1.3 其他队列
import queue
queue.Queue,先进先出队列
queue.LifoQueue,后进先出队列
queue.PriorityQueue,优先级队列
queue.deque,双向对队
queue.Queue(2) 先进先出队列
put放数据,是否阻塞,阻塞时的超时事件
get取数据(默认阻塞),是否阻塞,阻塞时的超时事件
qsize()真实个数
maxsize 最大支持的个数
join,task_done,阻塞进程,当队列中任务执行完毕之后,不再阻塞
import queue
# q = queue.Queue(2) 先进先出队列
# q = queue.LifoQueue() 后进先出队列
# q = queue.PriorityQueue() 优先级队列
# q = queue.deque() 双向队列
q = queue.LifoQueue()
q.put(123)
q.put(456)
# 打印;456
print(q.get())
# 优先级最小的拿出来
# 如果优先级一样,则是谁先放,就先取出谁
q = queue.PriorityQueue()
q.put((1,'alex1'))
q.put((1,'alex2'))
q.put((1,'alex3'))
q.put((3,'alex3'))
# (1, 'alex1')
print(q.get())
q = queue.deque()
q.append(123)
q.append(333)
q.appendleft(456)
# deque([456, 123, 333])
print(q)
# 打印:456
print(q[0])
q.pop() # 从右边删除
# deque([456, 123])
print(q)
q.popleft() # 从左边删除
python的队列是在内存里创建的,python的进程退出了,则队列也清空了。
二、生产者消费者模型(队列)
1)生产者消费者模型的作用:
1、解决阻塞
2、就是解耦,修改生产者,不会影响消费者,反之亦然。
2)在生产环境,用生产者消费者模型,就可以解决:
1、处理瞬时并发的请求问题。瞬时的连接数就不会占满。所以服务器就不会挂了。
2、客户端提交一个请求,不用等待处理完毕,可以在页面上做别的事情。
2.1)如果不用队列存数据,服务端通过多线程来处理数据:
用户往队列存数据,服务器从队列里取数据。
没有队列的话,就跟最大连接数有关系,每个服务器就有最大连接数。
客户端要获取服务器放回,服务器要查、修改数据库或修改文件,要2分钟,那客户端就要挂起链接2分钟,2万个连接一半都要挂起,服务器就崩溃了。
如果没有队列,第一个用户发来请求,连上服务器,占用连接,等待2分钟。
第二个人来也要占用2分钟。
web服务器
如果要处理并发,有10万并发,如果:一台机器接收一个连接,需要10万个机器,等待2分钟就处理完了。
2.2)把请求放在队列的好处
用户发来请求,把请求放到队列里,可以让连接马上断开,不会阻塞,就不占用服务器的连接数了。如果看到订单处理了没,就要打开另外一个页面,查看请求是否处理。
服务器查询处理任务的时候,每个才花2分钟,服务器耗时是没有减少的。
但是这样做,客户端就不会持续的占用连接了。那瞬时的连接数就不会占满。所以服务器就不会挂了。
但是后台要处理10万个请求,也需要50台服务器。并不会减少服务器数量。
这样就能处理瞬时并发的请求问题。
服务器只是处理请求,是修改数据库的值,不是告诉客户端。而是客户端再发来请求,查询数据库已经修改的内容。
提交订单之后,把这个订单扔给队列,程序返回“正在处理”,就不等待了,然后断开这个连接,你可以在页面里做别的事情,不用一直等待订单处理完。这样就不影响服务器的最大连接数。在页面帮你发起一个alax请求,url,不停的请求(可能是定时器),我的订单成功没有,我的订单成功没有,如果订单成功了,就自动返回页面:订单成功
如果不用队列的话,一个请求就占用一个服务器,等待的人特别多,等待连接的个数太多了。服务器就挂掉了。
队列就没有最大个数限制,把请求发给队列了,然后http链接就断开了,就不用等待了。
12306买票的时候,下次再来请求的时候,就会告诉你,前面排了几个人。
3)python queue的特点:
python的queue是内存级别的。rabbitmq可以把队列发到别的服务器上处理。
所以python里的queue不能持久化,但是rabbitmq可以持久化。
queue.Queue()这样写,队列就没有最大个数限制。queue.Queue(5)就是说队列里最多能放5个值
4)生产者消费者代码示例:
import time,random
import queue,threading
q = queue.Queue()
def Producer(name):
count =0
while True:
time.sleep(random.randrange(3))
if q.qsize()<3: # 只要盘子里小于3个包子,厨师就开始做包子
q.put(count)
print("Producer %s has produced %s baozi.." %(name,count))
count += 1
def Consumer(name):
count =0
while True:
time.sleep(random.randrange(4))
if not q.empty(): # 只要盘子里有包子,顾客就要吃。
data = q.get()
print(data)
print('�33[32;1mConsumer %s has eat %s baozi...�33[0m' % (name,data))
else: # 盘子里没有包子
print("---no baozi anymore----")
count+=1
p1 = threading.Thread(target=Producer,args=('A',))
c1 = threading.Thread(target=Consumer,args=('B',))
c2 = threading.Thread(target=Consumer,args=('C',))
p1.start()
c1.start()
c2.start()
'''
当你设计复杂程序的时候,就可以用生产者消费者模型,来松耦合你的代码,也可以减少阻塞。
'''
三、线程锁
3.1 Lock,RLock
Lock只能锁一次,RLock可以递归多层,Lock不支持多层锁嵌套,我们一般用RLOCK
import threading
import time
NUM = 10
def func(lock):
global NUM
# 上锁
lock.acquire()
lock.acquire()
NUM -= 1
time.sleep(2)
print(NUM)
# 开锁
lock.release()
lock.release()
# Lock = threading.Lock() # 不支持嵌套锁,一般不用
RLock = threading.RLock() # 一般用RLock,支持嵌套锁。
for i in range(10):
t = threading.Thread(target=func,args=(RLock,))
t.start()
'''
死锁:
就是你也抢资源,我也抢资源,谁也抢不走就是死锁。
如果是python,就是Lock,弄成嵌套锁,不支持,则变成死锁。
解决办法:
用RLock,支持嵌套锁
'''
3.2 信号量 BoundedSemaphore
如果用线程锁,一次只允许一个进入,如果用信号量可以允许同时多少个一起进入。
每次5个线程同时执行,可能就会同时修改一个值。
import threading
import time
NUM = 10
def func(i,lock):
global NUM
# 上锁
lock.acquire() # 总共30个 一次执行5个 25个,依次类推:20,15。。。
NUM -= 1
time.sleep(2)
print('NUM:',str(NUM),'i:',i)
# 开锁
lock.release()
# Lock = threading.Lock() # 不支持嵌套锁,一般不用
# RLock = threading.RLock() # 一般用RLock,支持嵌套锁。
lock = threading.BoundedSemaphore(5) # 参数是每次执行几个线程
for i in range(30):
t = threading.Thread(target=func,args=(i,lock,))
t.start()
'''
打印:
NUM: 5 i: 2
NUM: 4 i: 0
NUM: 4 i: 4
NUM: 2 i: 3
NUM: 1 i: 1
NUM: 0 i: 6
NUM: 0 i: 5
NUM: -2 i: 7
NUM: -2 i: 8
NUM: -4 i: 9
NUM: -5 i: 10
NUM: -6 i: 11
NUM: -7 i: 12
NUM: -8 i: 13
NUM: -9 i: 14
NUM: -10 i: 15
NUM: -10 i: 16
NUM: -10 i: 18
NUM: -10 i: 17
NUM: -10 i: 19
'''
打印
3.3 event红绿灯
要么全部阻塞(红灯),要么全部放开(绿灯)
import threading
def func(i,e):
print(i) # 10个线程并发打印:0-9 ,然后到wait的时候,就开始检测是什么灯
e.wait() # 检测是什么灯,如果是红灯,停;绿灯,行
print(i+100)
event = threading.Event()
for i in range(10):
t = threading.Thread(target=func,args=(i,event))
t.start()
event.clear() # 设置成红灯
inp = input('>>>')
if inp == "1":
event.set() #设置成绿灯
'''
默认是红灯
1
3
5
7
9
1 # 输入1,表示绿灯,就继续执行
103
107
101
105
109
'''
3.4 线程锁条件-condition1
Lock,RLock:线程锁使用场景:
Lock,RLock是多个用户同时修改一份数据,可能会出现脏数据,数据就会乱,就加互斥锁,一次只能让一个人修改数据,就能解决。
condition,event,BoundedSemaphore 使用场景:
如果写了个爬虫,在建立数据库连接,线程就等着,什么能数据库能用了,就开通线程,再爬虫。
event是kua一下,全走了。
notify维护一个队列,传几个,就只能出去几次。
import threading
def func(i, con):
print(i)
con.acquire()
con.wait()
print(i + 100)
con.release()
c = threading.Condition()
for i in range(10):
t = threading.Thread(target=func, args=(i, c,))
t.start()
while True:
inp = input(">>>")
if inp == 'q':
break
c.acquire()
c.notify(int(inp))
c.release()
'''
1
3
5
7
9
1 # 只让1个线程运行
100
# 再放出去2个线程
102
3 # 再放出去3个线程103
105
# 再放出去4个线程,此时10个已经执行了
108
106
5 # 再输入5,又进入while循环 提示输入:>>>q # 输入q就退出循环了。
Process finished with exit code 0
'''
3.5 线程锁条件-condition2
con.wait_for里传一个函数名当参数,返回布尔值,是True,就执行下面的代码。反之,就不执行。
无论是否返回True,都是用了一个线程。
import threading
def condition():
ret = False
r = input('>>>')
if r == 'true':
ret = True
else:
ret = False
return ret
def func(i,con):
print(i)
con.acquire()
con.wait_for(condition) # 只能一个一个过
print(i+100)
con.release()
c = threading.Condition()
for i in range(10):
t = threading.Thread(target=func, args=(i,c,))
t.start()
'''
1
3
5
7
9
s # 第0个线程, 虽然没返回True,没有答应101,但是还是使用了一个线程了。w # 第1个线程
e # 第2个线程
true # 第3个线程
true
true
true
true
true
true # 第10个线程
true # 线程执行完毕,一直等待,就一直阻塞
true
w
'''
3.6 线程锁定时器
from threading import Timer
def hello():
print("hello, world")
t = Timer(1, hello) # 等1秒,执行hello
t.start() # after 1 seconds, "hello, world" will be printed
四、自定义线程池
4.1 自定义线程池基础版
import queue
import threading
import time
class TheadPool:
def __init__(self,maxsize = 5):
self.maxsize = maxsize
self._q = queue.Queue(maxsize)
for i in range(maxsize): # 1、初始化的时候,先往队列里放5个线程
self._q.put(threading.Thread)
# 【threading.Thread, threading.Thread, threading.Thread, threading.Thread】
def get_thread(self):
return self._q.get()
def add_thread(self):
self._q.put(threading.Thread)
pool = TheadPool(5)
def task(arg,p):
# 2、线程并发执行,5个线程在瞬间(1秒钟之内)从队列里取出5个(执行get_thread()方法)
# 5个线程在瞬间打印0-4,就是i
print(arg)
time.sleep(1) # 3、停了5秒
p.add_thread() # 4、5个线程执行:队列添加线程(因为是5个线程执行,一个线程添加一个,队列总共是5个线程)
for i in range(20): # 5、然后这样先取走5个,再put5个,然后打印i,就会出现:第一次打印:0-4,然后是:5-9,10-14,15-19
# threading.Thread类
t = pool.get_thread()
obj = t(target=task,args=(i,pool,))
obj.start()
这个程序的问题:
线程没有被重用,线程一下开到最大(浪费)
'''
第一次打印:0-4,然后是:5-9,10-14,15-19
1
3
5
7
9
11
13
15
17
19
'''
4.2 自定义线程池
4.2.1 自定义线程池思路
不要把队列里放线程,而是放任务,开三个线程来从队列里取任务,如果都取完了,就会阻塞
方法1:
设置超时时间
方法2:
往队列尾部,加三个空值,如果取得是空值,则终止线程。
没有空闲线程,并且已经创建的线程小于最大的线程数,这样才会创建线程。
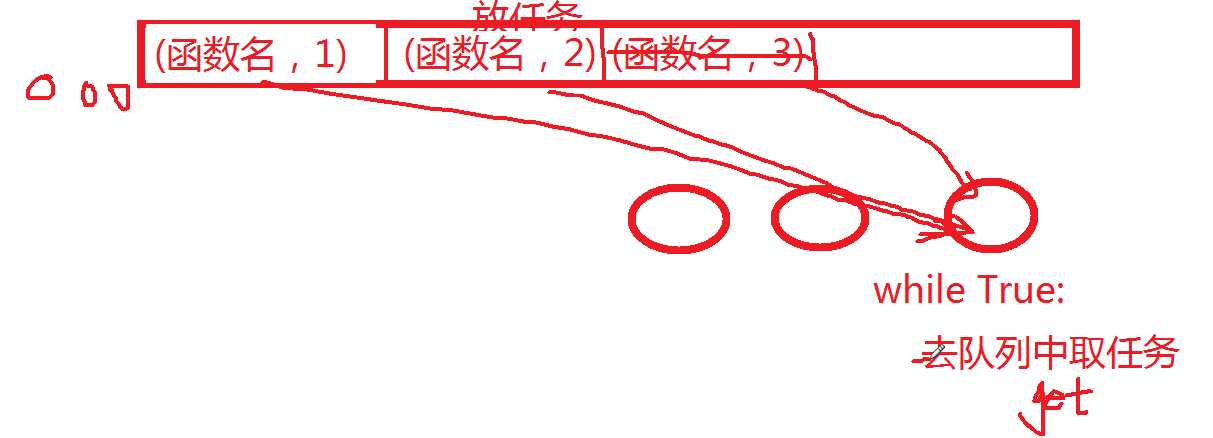
4.2.2 出现的问题
注意;之前的自定义线程池,如果定义queue的最多能放值的个数,pool = ThreadPool(5,5)
terminate就不好使了。
有的时候会一直阻塞,因为队列里已经有5个了,再往里面put一个,就超出queue里最大的个数。

解决办法是:
加上这一行

4.2.3自定义线程池代码
import queue
import threading
import contextlib
import time
StopEvent = object()
RUN = 0 # 定义线程池的三种状态
CLOSE = 1
TERMINATE = 2
iNum=0
'''
开启最大个数为5个的队列,
'''
class ThreadPool(object):
def __init__(self, max_num, max_task_num = None):
if max_task_num: # 如果传了最大队列数,就设置,否则就是无限大。
self.q = queue.Queue(max_task_num)
else:
self.q = queue.Queue()
self.max_num = max_num # 设置最大线程数
self.cancel = False # 假如已经执行close了,就不再执行任务,生成线程处理了
self.generate_list = [] # 已经生成的线程数列表
self.free_list = [] # 空闲的线程数列表
self._state = RUN
def run(self, func, args, callback=None):
"""
线程池执行一个任务
:param func: 任务函数
:param args: 任务函数所需参数
:param callback: 任务执行失败或成功后执行的回调函数,回调函数有两个参数1、任务函数执行状态;2、任务函数返回值(默认为None,即:不执行回调函数)
:return: 如果线程池已经终止,则返回True否则None
"""
if self.cancel: # 假如已经执行close了,就不再执行任务,生成线程处理了
return
if len(self.free_list) == 0 and len(self.generate_list) < self.max_num: # 假如空闲的线程列表为空,并且已经生成的线程数小于最大线程数
self.generate_thread() # 创建线程
w = (func, args, callback,) # 把当前任务放入队列,也就是run循环了300次,就有300个任务放入队列
self.q.put(w) # 注意:队列数是多少个,就要开启几个线程,因为当要关闭的线程池时,
# 要把空对象加到队列。线程判断获取到是空对象(此时已经把queue里的任务都取完了)就关闭线程。
global iNum
iNum+=1
# print('qsize:',str(self.q.qsize()))
def generate_thread(self):
"""
创建一个线程
"""
t = threading.Thread(target=self.call) # 执行call函数
t.start()
def call(self):
"""
循环去获取任务函数并执行任务函数
"""
current_thread = threading.currentThread # 获取当前线程
self.generate_list.append(current_thread) # 把当前线程加入到已经生成线程列表
event = self.q.get() # 从队列里取一个任务
while event != StopEvent: # 假如 这个任务不是空对象
func, arguments, callback = event # 传进去的任务是个元组,由函数,参数,回调函数组成。
try:
result = func(*arguments) # 执行任务,返回result
success = True # 执行成功,返回状态为True
except Exception as e:
success = False
result = None
else:
if callback is not None: # 假如有回调函数
try:
callback(success, result) # 把状态和返回值传给回调函数执行
except Exception as e:
pass
# 执行worker_state函数,空闲线程列表里是否加入个线程。在yield处执行with下的代码
with self.worker_state(self.free_list, current_thread):
if self._state == TERMINATE: # 假如线程池状态是TERMINATE
print(11111111111111111111111)
event = StopEvent # 就把当前任务赋值为空对象,while循环不满足,这样就走else的内容
else:
event = self.q.get() # 如果不是TERMINATE状态,则把当前任务赋给event对象
else: # 如果while循环不满足,或者while循环完了,没有break,就执行else内容。
self.generate_list.remove(current_thread) # 队列获取到了空对象,就关闭线程(从列表中移除当前的线程)
print(len(self.generate_list))
def close(self): # 先执行close(),再执行join()
"""
执行完所有的任务后,所有线程停止
"""
if self._state == RUN:
self._state = CLOSE
self.cancel = True
full_size = len(self.generate_list) # 查看已经生成的线程数个数
while full_size:
self.q.put(StopEvent) # 往队列尾部加上一个空对象,由于队列是先进先出的,所以空对象是最后获取的,通过空对象就能关闭线程。
full_size -= 1 # 循环的次数为生成的线程的总个数
def terminate(self): # 直接执行terminate()
"""
无论是否还有任务,终止线程
"""
self._state = TERMINATE
print("len:",str(len(self.generate_list)))
while self.generate_list: # 假如线程列表不为空,就往队列里加上空对象
print('q.qsize():',str(self.q.qsize()))
self.q.get()
self.q.put(StopEvent)
# self.q = queue.Queue()
print(self.q.empty()) # 查看队列是否为空,相当于q.size==0
print('------------'+str(self.q.qsize()))
def join(self): # CLOSE和join结合用
"""Waits until all outstanding tasks have been completed."""
assert self._state in (CLOSE,)
delay = 0.0005
if self._state==CLOSE:
while self.q.qsize() > 0:
delay = min(delay * 2, .05)
@contextlib.contextmanager # 上下文管理器
def worker_state(self, state_list, worker_thread): # 传入的是空闲线程列表和当前线程
"""
用于记录线程中正在等待的线程数
"""
state_list.append(worker_thread) # 把当前线程加到空闲线程里,yield前面的代码相当于执行__enter__,
try:
yield # yield是执行with worker_state下的代码,
finally: # yield后面的代码相当于执行__exit__
state_list.remove(worker_thread) # 执行完一个queue的所有任务了,就移除这个线程了。因为一个队列对应着一个线程。
pool = ThreadPool(5,5)
def callback(status, result):
# status, execute action status
# result, execute action return value
pass
def action(i):
print(i)
for i in range(200):
ret = pool.run(action, (i,), callback)
pool.terminate()
# pool.close()
# pool.join()
print(1234234523452345234523452345234523452345234523455)
# time.sleep(1)
print(pool.q.qsize())
print(len(pool.generate_list), len(pool.free_list))
print('iNum:',iNum)
# print(len(pool.generate_list), len(pool.free_list))
五、进程之间的数据共享
5.1 多进程
在windows里加main才能执行,如果在linux不加main可以执行。
在windows下,如果在程序里,不方便加main,只能放弃了。
from multiprocessing import Process
def foo(i):
print('say hi',i)
if __name__ == '__main__':
for i in range(10):
p = Process(target=foo,args=(i,))
p.start()
5.2 daemon加join 主线程是否等子线程
主线程执行完,子线程是否终止掉?
5.2.1 默认是不等的
from multiprocessing import Process
def foo(i):
print('say hi',i)
if __name__ == '__main__':
for i in range(10):
p = Process(target=foo,args=(i,))
# p.daemon = True
p.start()
# p.join()
print(123456)
'''
打印:
say hi 3
say hi 1
say hi 6
say hi 2
say hi 9
say hi 7
say hi 0
say hi 5
say hi 4
say hi 8
'''
打印
5.2.2 daemon+join等子线程
from multiprocessing import Process
def foo(i):
print('say hi',i)
if __name__ == '__main__':
for i in range(10):
p = Process(target=foo,args=(i,))
p.daemon = True
p.start()
p.join()
print(123456)
'''
打印:
say hi 0
say hi 1
say hi 2
say hi 3
say hi 4
say hi 5
say hi 6
say hi 7
say hi 8
say hi 9
'''
打印
5.3 进程默认数据不共享
5.3.1 线程中数据共享
这个例子是单线程,数据是共享的,无论单线程还是多线程都是共享的。
from multiprocessing import Process
import multiprocessing
def foo(i,li):
li.append(i)
print('say hi',i,li)
if __name__ == '__main__':
li = []
for i in range(10):
# p = Process(target=foo,args=(i,li))
foo(i,li)
# p.daemon = True
# p.start()
# p.join()
'''
正常的执行结果打印:最后是数组里有10个数
say hi 0 [0]
say hi 1 [0, 1]
say hi 2 [0, 1, 2]
say hi 3 [0, 1, 2, 3]
say hi 4 [0, 1, 2, 3, 4]
say hi 5 [0, 1, 2, 3, 4, 5]
say hi 6 [0, 1, 2, 3, 4, 5, 6]
say hi 7 [0, 1, 2, 3, 4, 5, 6, 7]
say hi 8 [0, 1, 2, 3, 4, 5, 6, 7, 8]
say hi 9 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
'''
打印
5.3.2 进程默认数据不共享
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'WangQiaomei'
from multiprocessing import Process
import multiprocessing
def foo(i,li):
li.append(i)
print('say hi',i,li)
if __name__ == '__main__':
li = []
for i in range(10):
p = Process(target=foo,args=(i,li))
# foo(i,li)
# p.daemon = True
p.start()
# p.join()
'''
正常的执行结果打印:最后是数组里有10个数,但是多进程最后数组里只有9
say hi 0 [0]
say hi 1 [1]
say hi 2 [2]
say hi 3 [3]
say hi 4 [4]
say hi 5 [5]
say hi 6 [6]
say hi 7 [7]
say hi 8 [8]
say hi 9 [9]
'''
打印
5.4 queues实现:进程之间数据共享
from multiprocessing import Process
from multiprocessing import queues
import multiprocessing
def foo(i,arg):
arg.put(i)
print('say hi',i,arg.qsize())
if __name__ == '__main__':
# li =[]
li = queues.Queue(20,ctx=multiprocessing)
for i in range(10):
p = Process(target=foo,args=(i,li,))
# p.daemon = True
p.start()
# p.join()
'''
打印:
say hi 1 1
say hi 5 3
say hi 0 5
say hi 3 6
say hi 7 7
say hi 6 7
say hi 2 7
say hi 9 9
say hi 4 9
say hi 8 10
'''
打印
5.5数组和列表的区别:
数组和列表的特点比较:
1、数组类型一定:
数组只要定义好了,类型必须是一致的
python里列表里,可以放字符串也可以放数字。
2、数组个数一定:
创建数组的时候,就要指定数组多大,比如数组是10,再添加11个,就会报错
列表是动态的,个数不一定。
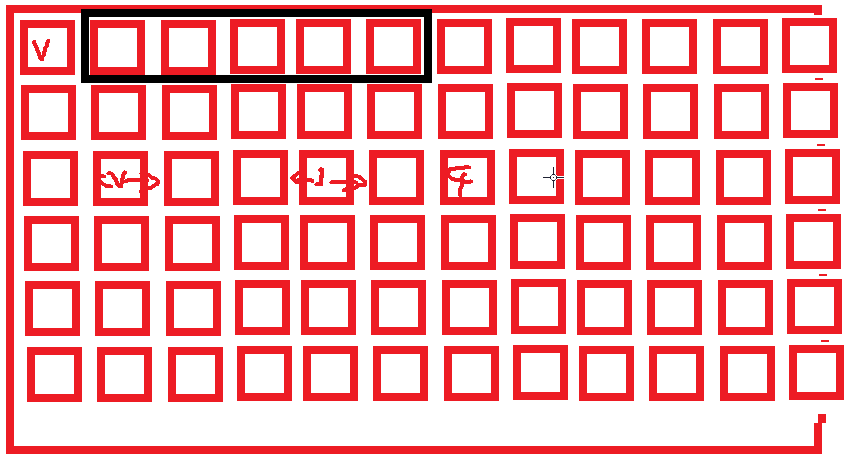
数组和列表的相邻元素的内存位置比较:
python的列表是基于c来实现。
python的列表相邻的两个元素在内存里,不一定挨着。是用链表实现的。
因为个数不限制,开始是10个长度,所以可能第11个被占用了。
每个元素,记录上一个和下一个的位置在哪里。可以找到位置。
字符串和int类型的占用内存的位置大小肯定不一样。所以数组,不只是长度一样,类型也要一样。
对于数组的话,相邻的元素是挨着的。
数组是int类型,并且长度是确定的。所以是相邻的。
数组的内存地址是连续的,列表不是,就是链表,链表是每个元素记录上一个位置和下一个位置在哪里。
如图,内存中:数组是黑框位置,列表是分散的分布:
5.6 数组实现:进程之间数据共享
from multiprocessing import Process
from multiprocessing import queues
import multiprocessing
from multiprocessing import Array
def foo(i,arg):
# arg.put(i)
# print('say hi',i,arg.qszie())
arg[i] = i + 100
for item in arg:
print(item)
print("====================")
if __name__ == '__main__':
# li =[]
# li = queues.Queue(20,ctx=multiprocessing)
li = Array('i',5)
for i in range(5):
p = Process(target=foo,args=(i,li,))
# p.daemon = True
p.start()
# p.join()
'''
打印:
0
0
101
0
101
103
101
103
101
103
'''
打印
注意:Array的参数,写了i,就只能放数字:

5.7 dict实现:进程之间数据共享
用Manager()对象创建一个特殊的字典。
For循环创建了多个进程,每个进程都可以利用dict。
dict.values()就是获取它所有的值,
如果字典获取的值是递增的,说明数据是共享的。
5.7.1 AttributeError:'ForkAwareLocal' object has no attribute 'connection'
如果把join注释就会报错:
报错:
conn = self._tls.connection
AttributeError: 'ForkAwareLocal' object has no attribute 'connection'
from multiprocessing import Process
import multiprocessing
from multiprocessing import Manager
def foo(i,arg):
arg[i] = i + 100
print(arg.values())
if __name__ == '__main__':
obj = Manager()
li = obj.dict()
for i in range(10):
p = Process(target=foo,args=(i,li,))
p.start()
# p.join() # 方式1
# 方式2
# import time
# time.sleep(10)
原因是:
li = obj.dict()是在主进程创建的
for循环里创建的是子进程,子进程是修改主进程:arg[i] = i + 100(arg就是li)
主进程和子进程都在执行,主进程里有个字典,子进程要修改这个字典。
进程和进程之间要通信的话,需要创建连接的。相当于两边都写上一个socket,进程之间通过连接进行操作。
主进程执行到底部,说明执行完了,会把它里面的连接断开了。
主进程把连接断开了,子进程就连接不上主进程。
如果在底部写停10秒,主进程就停止下来,并没有执行完。主进程没有执行完,连接还没有断开,那子进程就可以连接它了。
5.7.2 解决方法1:停10秒(不建议)
from multiprocessing import Process
import multiprocessing
from multiprocessing import Manager
def foo(i,arg):
arg[i] = i + 100
print(arg.values())
if __name__ == '__main__':
obj = Manager()
li = obj.dict()
for i in range(10):
p = Process(target=foo,args=(i,li,))
p.start()
# p.join() # 方式1
# 方式2
import time
time.sleep(10)
打印:
[102]
[102, 105]
[102, 103, 105]
[102, 103, 105, 107]
[109, 102, 103, 105, 107]
[101, 102, 103, 105, 107, 109]
[101, 102, 103, 105, 106, 107, 109]
[101, 102, 103, 105, 106, 107, 108, 109]
[100, 101, 102, 103, 105, 106, 107, 108, 109]
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
打印
5.7.3测试:
如果把sleep(10)改成sleep(0.1),那么只会打印前面几行,然后又报之前的错误
打印:
[102]
[102, 105]
[102, 103, 105]
[102, 103, 105, 107]
接着报错:
conn = self._tls.connection
AttributeError: 'ForkAwareLocal' object has no attribute 'connection'
5.7.4 解决办法2:用join
p.join()
所以使用多进程的常规方法是,先调用start启动进程,再调用join要求主进程等待当前子进程的结束。
join是用来阻塞当前线程的,每次循环:p.start()之后,p就提示主线程,需要等待p结束才向下执行,那主线程就乖乖的等着啦。
from multiprocessing import Process
import multiprocessing
from multiprocessing import Manager
def foo(i,arg):
arg[i] = i + 100
print(arg.values())
if __name__ == '__main__':
obj = Manager()
li = obj.dict()
for i in range(10):
p = Process(target=foo,args=(i,li,))
p.start()
p.join() # 方式1:
# 方式2
# import time
# time.sleep(10)
打印:
[102]
[102, 105]
[102, 103, 105]
[102, 103, 105, 107]
[109, 102, 103, 105, 107]
[101, 102, 103, 105, 107, 109]
[101, 102, 103, 105, 106, 107, 109]
[101, 102, 103, 105, 106, 107, 108, 109]
[100, 101, 102, 103, 105, 106, 107, 108, 109]
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
打印
5.7.5 总结:进程之间共享的方式:
queues,数组和字典的方式
dict对类型没有限制,跟使用字典是一模一样的。用数组则限制了数据类型。
进程和进程之间要通信,是要连接的。
主进程执行到底部了,就执行完了,就把连接断开了。子进程就连不上主进程了。
六、进程
6.1 进程锁
没有锁,多个进程就会一起修改数据:
from multiprocessing import Process
from multiprocessing import queues
from multiprocessing import Array
from multiprocessing import RLock, Lock, Event, Condition, Semaphore
import multiprocessing
import time
def foo(i,lis):
lis[0] = lis[0] - 1 # 因为停1秒,在1秒之内,10个进程都已经修改了数据。
time.sleep(1) # 停1秒前全都修改完
print('say hi',lis[0]) # 打印的全是0
if __name__ == "__main__":
# li = []
li = Array('i', 1)
li[0] = 10
for i in range(10):
p = Process(target=foo,args=(i,li))
p.start()
进程没有锁
'''
打印:
say hi 0
say hi 0
say hi 0
say hi 0
say hi 0
say hi 0
say hi 0
say hi 0
say hi 0
say hi 0
'''
打印
加把锁就把进程锁住了,同一时间只有一个进程可以运行,其他都等着。
RLock, Lock, Event, Condition, Semaphore # 这些方法跟线程的使用方法是一样的
from multiprocessing import Process
from multiprocessing import queues
from multiprocessing import Array
from multiprocessing import RLock, Lock, Event, Condition, Semaphore # 这些方法跟线程的使用方法是一样的
import multiprocessing
import time
def foo(i,lis,lc):
lc.acquire() # 加锁
lis[0] = lis[0] - 1
time.sleep(1)
print('say hi',lis[0])
lc.release() # 释放锁
if __name__ == "__main__":
# li = []
li = Array('i', 1)
li[0] = 10
lock = RLock()
for i in range(10):
p = Process(target=foo,args=(i,li,lock))
p.start()
'''
打印:
say hi 9
say hi 8
say hi 7
say hi 6
say hi 5
say hi 4
say hi 3
say hi 2
say hi 1
say hi 0
'''
打印
6.2 进程池
6.2.1 进程池串行-apply
apply从进程池里取进程,然后一个一个执行,第一个进程执行完,第二个进程才执行,进程之间是串行的操作。这样就不是并发操作,没有太大意义。
from multiprocessing import Pool
def f1(arg):
print(arg)
if __name__ == "__main__":
pool = Pool(5)
for i in range(10):
pool.apply(func=f1,args=(i,)) # apply执行函数,传入参数
print('end')
'''
打印:
1
3
5
7
9
end
'''
打印
6.2.1 进程池异步-apply_rsync
from multiprocessing import Pool
def f1(arg):
print(arg)
if __name__ == "__main__":
pool = Pool(5)
for i in range(10):
# pool.apply(func=f1,args=(i,)) # apply执行函数,传入参数
pool.apply_async(func=f1,args=(i,))
print('end')
这10个任务kua一下全执行了,主进程执行到end了。
主进程执行完了,子进程就被终止掉了。
主进程执行完了,就不再等子线程了,如果要等就要设置参数。
多线程线程默认也是,主进程不等子进程,多线程是:daemon=True加join来让他等。
6.3 主线程等子线程
6.3.1 close等子线程全部执行完
join是终止进程,必须要前面执行close或者terminate方法。
执行close,等所有任务(10个)全部执行完,再终止
执行terminate,表示立即终止,不管你当前的任务是否执行完,都立即终止。
from multiprocessing import Pool
import time
def f1(arg):
time.sleep(1) # 加这句是为了看出5个5个执行的效果。
print(arg)
if __name__ == "__main__":
pool = Pool(5)
for i in range(10):
# pool.apply(func=f1,args=(i,)) # apply执行函数,传入参数
pool.apply_async(func=f1,args=(i,))
pool.close()
pool.join() # join表示:主进程执行到这里的时候,夯住了,等子进程结束的时候,再往下执行。
print('end')
光执行join,会触发下面的断言错误:
assert self._state in (CLOSE, TERMINATE)
join源代码有这句,只有符合这个条件的,才不会报错。
这个条件就是:执行join之前,必须执行close或者terminate方法。
close+join:是等子线程全部执行完了,才继续往下执行。
这是5个5个执行。因为是5个线程同时执行,总共要完成10个任务。
打印:
1
3
5
7
9
end
打印
6.3.2 terminate立即终止
from multiprocessing import Pool
import time
def f1(arg):
time.sleep(1)
print(arg)
if __name__ == "__main__":
pool = Pool(5)
for i in range(10):
# pool.apply(func=f1,args=(i,)) # apply执行函数,传入参数
pool.apply_async(func=f1,args=(i,))
time.sleep(1.5)
pool.terminate() # 立即终止
pool.join()
print('end')
光执行join,会触发下面的断言错误:
assert self._state in (CLOSE, TERMINATE)
join源代码有这句,只有符合这个条件的,才不会报错。
这个条件就是:执行join之前,必须执行close或者terminate方法。
terminate+join:是表示立即终止,不管你当前的任务是否执行完,都立即终止。
'''
打印:
1
3
end
'''
打印
七、协程
7.1 协程及gevent原理
IO密集型:用多线程+gevent(更好),多线程
计算密集型:用多进程
协程原理:利用一个线程,分解一个线程成为多个“微线程”==>程序级别
如果写爬虫,就访问别的网站,拿别人源码。http请求叫IO请求,用多线程。
假设要访问3个url,创建3个线程,都在等待着,第一个有数据返回就继续执行,以此类推。
在等待过程中,就什么事也没干。
协程的方式。
计算机帮你创建进程、线程。线程是人为创建出来的。用一个线程,一会儿执行这个操作,一会儿执行那个操作。
协程是只用一个线程。程序员利用io多路复用的方式,让协程:
先访问一个url,不等待返回,就再访问第二个url,访问第三个url,然后也在等待。
greenlet本质是实现协程的。
注意:协程本身不高效,协程的本质只是程序员调用的,那为啥gevent这么高效率呢,是因为用了协程(greenlet)+IO多路复用的方式。
是IO多路复用的用法才能高效。所以用的时候就用gevent就好了。
用多线程:假设每爬一个网址需要2秒,3个url,就是3个请求,等待2秒,就可以继续往下走。
如果用gevent,用单线程,单线程应该从上到下执行,用for循环读取3个url,往地址发送url请求,就是IO请求,线程是不等待的。
for循环再拿第二个url,再发第三个url。在这过程中,谁先回来,就处理谁。
资源占用上,多线程占用了3个线程,2秒钟,多线程啥也没干,在等待。gevent在2秒钟,只要发送请求了,接着就想干什么干什么。
7.2 greenlet协程
greenlet切换协程:
from greenlet import greenlet
def test1():
print(12)
gr2.switch()
print(34)
gr2.switch()
def test2():
print(56)
gr1.switch()
print(78)
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()
'''
打印:
56
78
'''
打印
7.3 gevent
greenlet切换协程:
import gevent
def foo():
print('Running in foo') # 第1步
gevent.sleep(0)
print('Explicit context switch to foo again') # 第3步
def bar():
print('Explicit context to bar') # 第2步
gevent.sleep(0)
print('Implicit context switch back to bar') # 第4步
gevent.joinall([
gevent.spawn(foo),
gevent.spawn(bar),
])
'''
打印:
Running in foo
Explicit context to bar
Explicit context switch to foo again
Implicit context switch back to bar
'''
打印
7.3 gevent 切换执行
greenlet切换执行协程的本质是执行如下代码:
import gevent
def foo():
print('Running in foo') # 第1步
gevent.sleep(0)
print('Explicit context switch to foo again') # 第3步
def bar():
print('Explicit context to bar') # 第2步
gevent.sleep(0)
print('Implicit context switch back to bar') # 第4步
gevent.joinall([
gevent.spawn(foo),
gevent.spawn(bar),
])
'''
打印:
Running in foo
Explicit context to bar
Explicit context switch to foo again
Implicit context switch back to bar
'''
打印
但是平常我们用gevent,不用这么麻烦,而是使用下面的代码就好了。
7.4 gevent使用方法
遇到IO操作自动切换:
from gevent import monkey; monkey.patch_all()
import gevent
import requests
# 这个函数是发http请求的
def f(url):
print('GET: %s' % url)
resp = requests.get(url)
data = resp.text # 获取内容
print('%d bytes received from %s.' % (len(data), url))
gevent.joinall([
gevent.spawn(f, 'https://www.python.org/'), # 创建了一个协程
gevent.spawn(f, 'https://www.yahoo.com/'), # 创建了一个协程
gevent.spawn(f, 'https://github.com/'), # 创建了一个协程
])
创建了三个协程。总共就一个线程,通过for循环发送三个url请求。然后等待结果,谁先回来,就处理谁。
通过requests.get(url)发送url请求,谁先回来,就拿到数据(data),拿到数据就可以处理数据了。
这都是在一个线程里执行的。
瞬间打印:
GET: https://www.python.org/
GET: https://www.yahoo.com/
GET: https://github.com/
然后等待哪个url先返回,就先打印
bytes received from https://www.python.org/.
bytes received from https://github.com/.
bytes received from https://www.yahoo.com/.
'''
打印
gevent的使用场景举例:
1、scrapy框架内部用的gevent。发请求性能比线程高很多。
2、做api(url)监控,把代码发布到哪个url,得自动检测下返回值是不是200,或是指定的状态码。
发布完成之后,就要发送http请求过去检测一下返回的状态码。如果有20个url请求,就用gevent一下全给发了,就没必要创建多个线程,一个线程就足以了,然后配合多进程+gevent,又可以利用多颗cpu的优势了。
monkey.patch_all()是什么?
发送http请求,是request本质上调用socket来发。原来执行http请求,就会通知我一下,执行完了,默认socket是没有这个功能的。这相当于把原来的socket修改了,修改成特殊功能的socket,发送请求如果完事了,会告诉你完事了。
其实内部就是把io请求做了个封装而已。