首先说明,本文记录的是博主搭建的3节点的完全分布式hadoop集群的过程,环境是centos 7,1个nameNode,2个dataNode,如下:
1、首先,创建好3个Centos7的虚拟机,具体的操作可以参考网上其他教程,这个给个链接《windows环境安装VMware,并且安装CentOS7 虚拟机》
2、完成虚拟机的java环境的搭建,可以参考我的博客《centos7 安装jdk 1.8》
3、关闭或者禁用防火墙, systemctl stop firewalld.service 关闭防火墙;systemctl disable firewalld.service 关闭防火墙
firewall-cmd --state 查看状态

4、修改hosts文件,vim /etc/hosts ,注释原有的内容,加入如下内容,ip地址为你自己的虚拟机的IP地址:
192.168.10.128 master.hadoop 192.168.10.129 slave1.hadoop 192.168.10.130 slave2.hadoop
more /etc/hosts查看是否正确,需要重启后方能生效。重启命令 reboot now
此处可以添加ssh key,创建无密码的公钥
a、在master机器上输入 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 创建一个无密码的公钥,-t是类型的意思,dsa是生成的密钥类型,-P是密码,’’表示无密码,-f后是秘钥生成后保存的位置 b、在master机器上输入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥id_dsa.pub添加进keys,这样就可以实现无密登陆ssh c、在master机器上输入 ssh master 测试免密码登陆 d、在slave1.hadoop主机上执行 mkdir ~/.ssh e、在slave2.hadoop主机上执行 mkdir ~/.ssh f、在master机器上输入 scp ~/.ssh/authorized_keys root@slave1.hadoop:~/.ssh/authorized_keys 将主节点的公钥信息导入slave1.hadoop节点,导入时要输入一下slave1.hadoop机器的登陆密码 g、在master机器上输入 scp ~/.ssh/authorized_keys root@slave2.hadoop:~/.ssh/authorized_keys 将主节点的公钥信息导入slave2.hadoop节点,导入时要输入一下slave2.hadoop机器的登陆密码 h、在三台机器上分别执行 chmod 600 ~/.ssh/authorized_keys 赋予密钥文件权限 i、在master节点上分别输入 ssh slave1.hadoop和 ssh slave2.hadoop测试是否配置ssh成功
5、进入home目录,mkdir hadoop 创建一个hadoop的文件夹。上传下载好的hadoop包到该目录,hadoop2.9下载地址;
http://hadoop.apache.org/->左边点Releases->点mirror site->点http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common->下载hadoop-2.9.0.tar.gz;
tar -zxvf hadoop-2.9.0.tar.gz 解压tar包
6、配置hadoop,此节点可暂时先配置128master,然后通过scp的方式复制到两个从节点
a、vim /home/hadoop/hadoop-2.9.0/etc/hadoop/core-site.xml,在<configuration>节点中增加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://master.hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
b、vim /home/hadoop/hadoop-2.9.0/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.hadoop:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
c、cp /home/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml.template /home/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml
vim /home/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master.hadoop:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.hadoop:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master.hadoop:9001</value>
</property>
</configuration>
d、vim /home/hadoop/hadoop-2.9.0/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master.hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master.hadoop:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master.hadoop:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master.hadoop:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master.hadoop:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.hadoop</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
</configuration>
7、配置/home/hadoop/hadoop-2.9.0/etc/hadoop目录下hadoop.env.sh、yarn-env.sh的JAVA_HOME
取消JAVA_HOME的注释,设置为 export JAVA_HOME=/home/java/jdk1.8.0_11
8、配置/home/hadoop/hadoop-2.9.0/etc/hadoop目录下的slaves,删除默认的localhost,添加2个slave节点:
slave1.hadoop
slave2.hadoop
9、将master服务器上配置好的Hadoop复制到各个节点对应位置上,通过scp传送:
scp -r /home/hadoop 192.168.10.129:/home/ scp -r /home/hadoop 192.168.10.130:/home/
10、启动hadoop。在master节点启动hadoop服务,各个从节点会自动启动,进入/home/hadoop/hadoop-2.9.0/sbin/目录,hadoop的启动和停止都在master上进行;
a、初始化,输入命令:hdfs namenode -format
b、启动命令:start-all.sh

c、输入jps命令查看相关信息,master上截图如下:
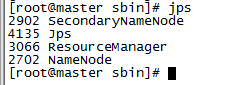
d、slave节点上输入jps查看:
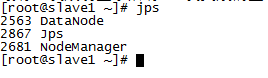
e、停止命令:stop-all.sh
11、访问,输入http://192.168.10.128:50070,看到如下界面:
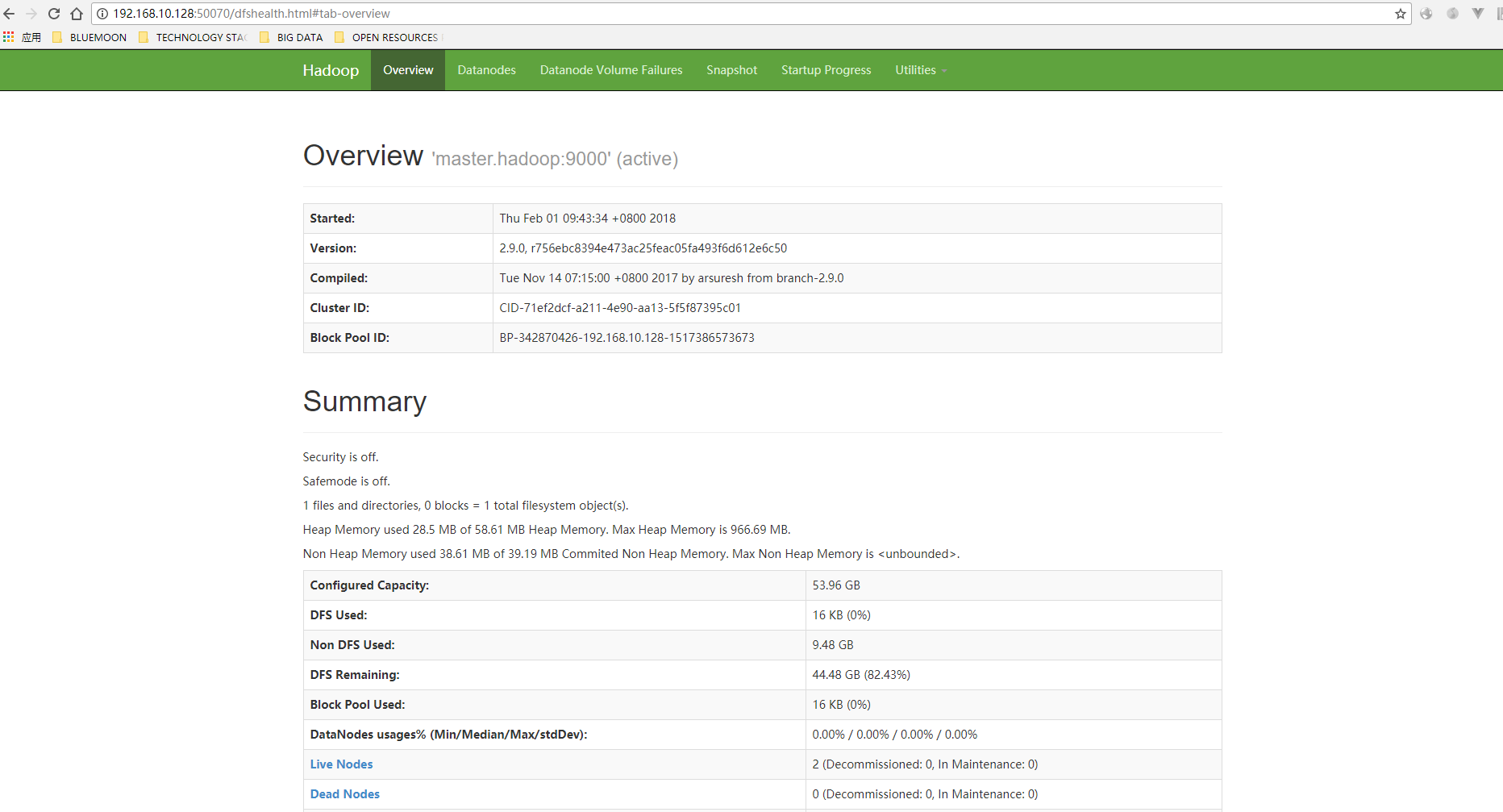
输入http://192.168.10.128:8088,看到如下界面:
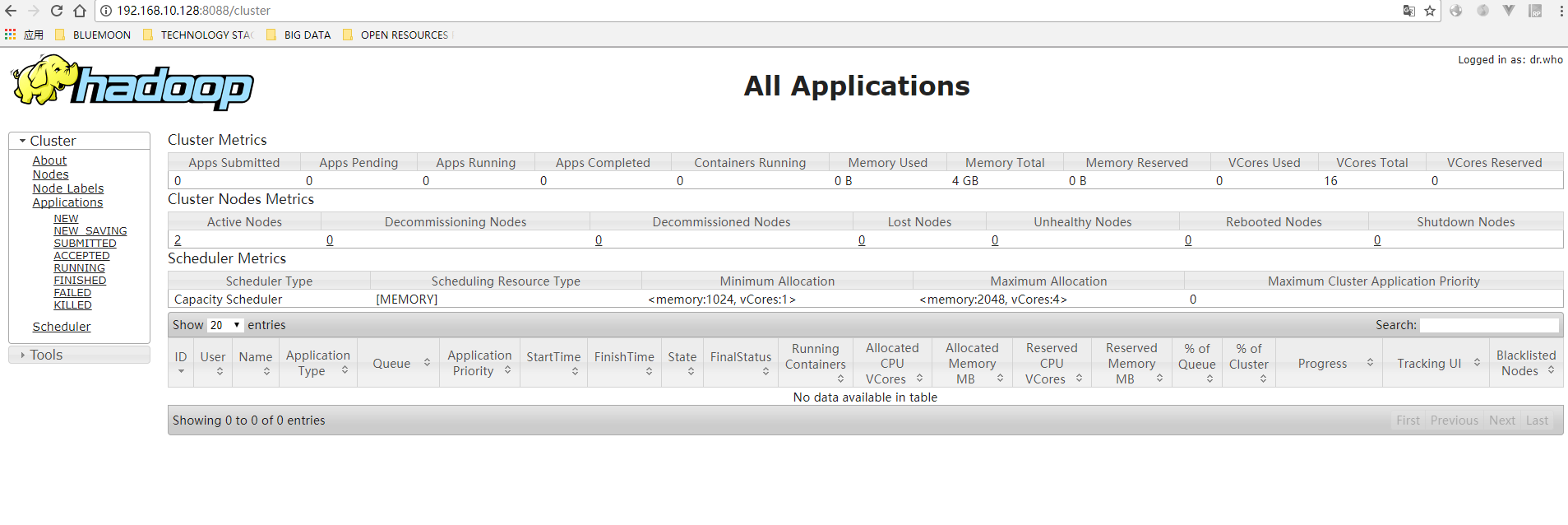 好了。如果以上都成功,那么基本上完成了hadoop集群的搭建;
好了。如果以上都成功,那么基本上完成了hadoop集群的搭建;
