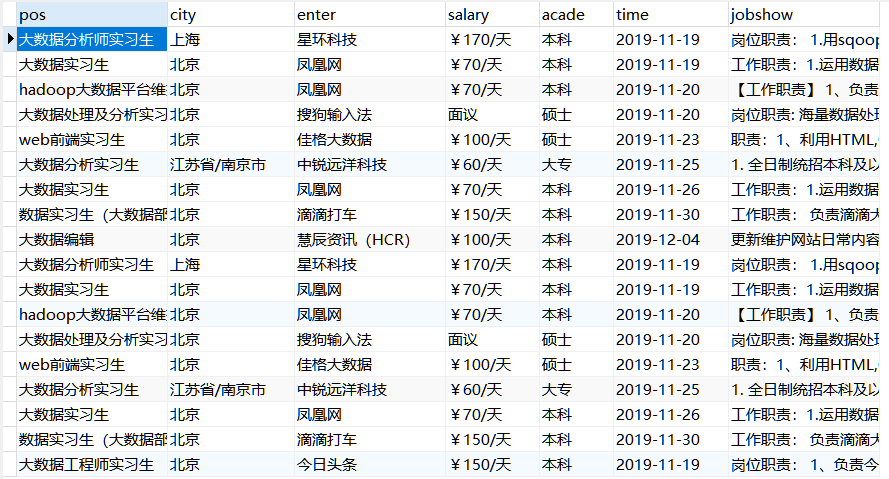
使用Scrapy框架爬取实习网“大数据实习生”信息前3页的内容,爬取的信息包括:'岗位名称', '实习城市', '实习企业', '实习工资', '学历要求', '发布时间', '工作描述',爬取的网址为:https://www.shixi.com/search/index?key=大数据
新建项目
打开cmd,创建一个Scrapy项目,命令如下:
scrapy startproject shixi
cd shixi
scrapy genspider bigdata www.shixi.com
使用pycharm打开

构造请求
在settings.py中,设置MYSQL参数,在后面加上以下代码
MAX_PAGE = 3 # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'shixi.pipelines.MySQLPipeline': 300, } MYSQL_HOST = 'localhost' MYSQL_DATABASE = 'spiders' MYSQL_USER = 'root' MYSQL_PASSWORD = '123456' MYSQL_PORT = 3306 # Obey robots.txt rules ROBOTSTXT_OBEY = False DOWNLOAD_DELAY = 5
提取信息
在items.py中定义Item
import scrapy from scrapy import Field class ShixiItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() table = "bigdataPos" #表名 pos = Field() city = Field() enter = Field() salary = Field() acade = Field() time = Field() jobshow = Field()
在spiders目录下的bigdata.py中修改parse()方法和增加start_request()方法,
需要注意的地方是start_urls定义初始请求,需要改成我们爬取的第一页https://www.shixi.com/search/index?key=大数据
# -*- coding: utf-8 -*- import scrapy from scrapy import Spider, Request from shixi.items import ShixiItem class BigdataSpider(scrapy.Spider): name = 'bigdata' allowed_domains = ['www.shixi.com'] #注意写域名,而不是url,如果后续的请求链接不在这个域名下,则过滤 start_urls = ['https://www.shixi.com/search/index?key=大数据'] #启动时爬取的url列表 def parse(self, response): jobs = response.css(".left_list.clearfix .job-pannel-list") for job in jobs: item = ShixiItem() # item[''] = house.css("").extract_first().strip() item['pos'] = job.css("div.job-pannel-one > dl > dt > a::text").extract_first().strip() item['city'] = job.css( ".job-pannel-two > div.company-info > span:nth-child(1) > a::text").extract_first().strip() item['enter'] = job.css(".job-pannel-one > dl > dd:nth-child(2) > div > a::text").extract_first().strip() item['salary'] = job.css(".job-pannel-two > div.company-info > div::text").extract_first().strip().replace( ' ', '') item['acade'] = job.css(".job-pannel-one > dl > dd.job-des > span::text").extract_first().strip() item['time'] = job.css(".job-pannel-two > div.company-info > span.job-time::text").extract_first().strip() next = job.css(".job-pannel-one > dl > dt > a::attr('href')").extract_first() # item['describe'] = job.css("::text").extract_first().strip() url = response.urljoin(next) yield scrapy.Request(url=url, callback=self.parse2, meta={'item':item}) #meta def parse2(self, response): item = response.meta['item'] # decribe不能做列名,是关键字 item['jobshow'] = response.css("div.work.padding_left_30 > div.work_b::text").extract_first().strip() yield item def start_request(self): base_url = "https://www.shixi.com/search/index?key=大数据&page={}" for page in range(1, self.settings.get("MAX_PAGE") + 1): url = base_url.format(page) yield Request(url, self.parse)
存储信息
在phpstudy启动MYSQL,然后打开navicat,新建一张表bigdataPos,注意表名必须和items.py写的表名一致

接下来在pipelines.py 实现MySQLPipeline
import pymysql class MySQLPipeline(): def __init__(self,host,database,user,password,port): self.host = host self.database = database self.user = user self.password = password self.port = port @classmethod def from_crawler(cls, crawler): return cls( host=crawler.settings.get("MYSQL_HOST"), database=crawler.settings.get("MYSQL_DATABASE"), user=crawler.settings.get("MYSQL_USER"), password=crawler.settings.get("MYSQL_PASSWORD"), port=crawler.settings.get("MYSQL_PORT") ) def open_spider(self, spider): self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8', port=self.port) self.cursor = self.db.cursor() def close_spider(self, spider): self.db.close() def process_item(self, item, spider): data = dict(item) keys = ", ".join(data.keys()) values = ", ".join(["%s"] * len(data)) sql = "insert into %s (%s) values (%s)" % (item.table, keys, values) self.cursor.execute(sql, tuple(data.values())) self.db.commit() return item
运行程序
在cmd中shixi目录下运行
scrapy crawl bigdata
可以得到
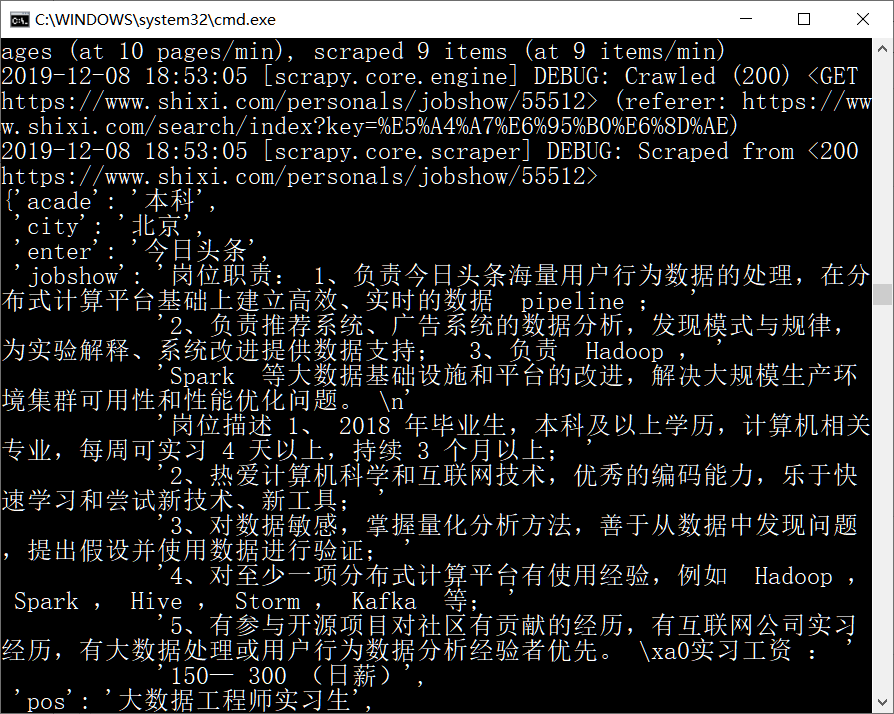
数据库中也成功写入