HTTP 报文分为请求报文与响应报文
HTTP 请求报文
请求报文分为 4部分,请求行,请求头部,空行,请求体部,如下图所示:

请求行分为 3 部分,为请求方法 URL 与协议版本,中间以空格隔开。
- ① 是请求方法,分为 GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT
- ②为请求对应的URL地址,它和报文头的Host属性组成完整的请求URL,URL也可以通过类似于“/chapter15/user.html? param1=value1¶m2=value2”的方式传递请求参数。
- ③是协议名称及版本号。
- ④是HTTP的报文头,报文头包含若干个属性,格式为“属性名:属性值”,服务端据此获取客户端的信
- ⑤是报文体,它将一个页面表单中的组件值通过 param1=value1¶m2=value2 的键值对形式编码成一个格式化串,它承载多个请求参数的数据。
请求头
Accept : 告诉服务器客户端接受什么类型的响应;
Cookie:客户端的Cookie就是通过这个报文头属性传给服务端
Referer :表示这个请求是从哪个URL过来的,假如你通过google搜索出一个商家的广告页面,你对这个广告页面感兴趣,鼠标一点发送一个请求报文到商家的网站,这个请求报文的Referer报文头属性值就是 http://www.google.com。
Cache-Control :对缓存进行控制,如一个请求希望响应返回的内容在客户端要被缓存一年,或不希望被缓存就可以通过这个报文头达到目的。
Http 响应报文
响应报文包括响应行 响应头部 与 响应体部:
 ①报文协议及版本;
①报文协议及版本;
②状态码及状态描述;
③响应报文头,也是由多个属性组成;
④响应报文体,即我们真正要的“干货”。
状态码:
- 1xx 消息,一般是告诉客户端,请求已经收到了,正在处理,别急...
- 2xx 处理成功,一般表示:请求收悉、我明白你要的、请求已受理、已经处理完成等信息.
- 3xx 重定向到其它地方。它让客户端再发起一个请求以完成整个处理。
- 4xx 处理发生错误,责任在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
- 5xx 处理发生错误,责任在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等。
响应头
Cache-Control:响应输出到客户端后,服务端通过该报文头属告诉客户端如何控制响应内容的缓存。 比如说字段为 Cache-Control: max-age = 3600 ,表示客户端需要对该响应缓存3600秒,不用再去服务器访问该资源。
ETag:一个代表响应服务端资源(如页面)版本的报文头属性,如果某个服务端资源发生变化了,这个ETag就会相应发生变化。它是Cache-Control的有益补充,可以让客户端“更智能”地处理什么时候要从服务端取资源,什么时候可以直接从缓存中返回响应。
Location:我们在JSP中让页面Redirect到一个某个A页面中,其实是让客户端再发一个请求到A页面,这个需要Redirect到的A页面的URL,其实就是通过响应报文头的Location属性告知客户端的
Set-Cookie:服务端可以设置客户端的Cookie,其原理就是通过这个响应报文头属性实现的:
最后总结几个重点问题.
1)POST 与 GET 区别
- GET 是从服务器上获取数据,GET是向服务器传送数据。
- GET 是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段一一对应,在URL中可以看到。POST是通过HTTP POST机制,将表单内各个字段与其内容放置在 HTML HEADER 内一起传送到 ACTION 属性所指的URL地址。用户看不到这个过程。
- GET 传送的数据量较小,不能大于1024 字节。POST传送的数据量较大,一般被默认为不受限制。但理论上,IIS4中最大量为80KB,IIS5中为100KB。
- GET 安全性非常低,POST安全性较高。但是执行效率却比POST方法好。
- HEAD 就像 GET ,只不过服务端接受到HEAD请求后只返回响应头,而不会发送响应内容。当我们只需要查看某个页面的状态的时候,使用HEAD是非常高效的,因为在传输的过程中省去了页面内容。
2)Session 与 Cookie 机制
web程序中用来跟踪整个用户会话的过程,常用的技术是 Cookie 与 Session,主要区别是Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
由于HTTP是一种无状态的协议,服务器单从网络连接上无从知道客户身份。怎么办呢?就给客户端们颁发一个通行证吧,每人一个,无论谁访问都必须携带自己通行证。这样服务器就能从通行证上确认客户身份了。这就是Cookie的工作原理。Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容。 Cookie 可以让服务端程序跟踪每个客户端的访问,但是每次客户端的访问都必须传回这些 Cookie。
如果 Cookie 很多,这无形地增加了客户端与服务端的数据传输量,而 Session 的出现正是为了解决这个问题。同一个客户端每次和服务端交互时,不需要每次都传回所有的 Cookie 值,而是只要传回一个 ID,这个 ID 是客户端第一次访问服务器的时候生成的,而且每个客户端是唯一的。这样每个客户端就有了一个唯一的 ID,客户端只要传回这个 ID 就行了,这个 ID 通常是 NANE 为 JSESIONID 的一个 Cookie。但是 Session 的致命弱点是不容易在多台服务器之间共享,所以这也限制了 Session 的使用。所以要共享这些 Session 必须将它们存储在一个分布式缓存中,可以随时写入和读取,而且性能要很好才能满足要求。当前能满足这个要求的系统有很多,如 MemCache 或者淘宝的开源分布式缓存系统 Tair 都是很好的选择。cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
一次完整的 HTTP 过程
1.客户端输入网址,需要解析为 IP ,首先在本地 DNS 缓存查询,然后查询本地 HOST 文件,都没有则去DNS 服务器查找 IP;
2.三次握手建立TCP/IP 连接,客户端与服务器端通过 Socket 三次握手建立连接;
3. 客户端向服务器端发送 HTTP 请求报文;
4. 服务器端解析 HTTP 报文,给出 HTTP 响应报文,响应报文头部与体部之间有一个空行;
5. 若 HTTP 头部包含 Connection : keep-alive ,则客户端与服务器端保持 TCP 连接,否则服务器端关闭 TCP 连接。
TCP 三次握手 四次挥手
ACK:TCP协议规定,只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1
SYN:即 Synchronization ,在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1. 因此, SYN置1就表示这是一个连接请求或连接接受报文。
FIN :即终结的意思, 用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
假设主机 A 要与主机 B 建立连接:
第一次握手:主机A发送位码为SYN=1,随机产生seq = x 的数据包到服务器,主机B由 SYN=1 知道,A要求建立联机;
第二次握手:主机B收到请求后要确认联机信息,向A发送SYN =1,ACK = 1,ack=x+1,随机产生seq=y的包
第三次握手:主机A收到后检查 ack 是否正确,即第一次发送的seq值+1,以及位码 ACK 是否为1,若正确,主机A会再发送 ACK =1 ,ack=y+1 主机B收到后确认seq值与ack=1则连接建立成功。

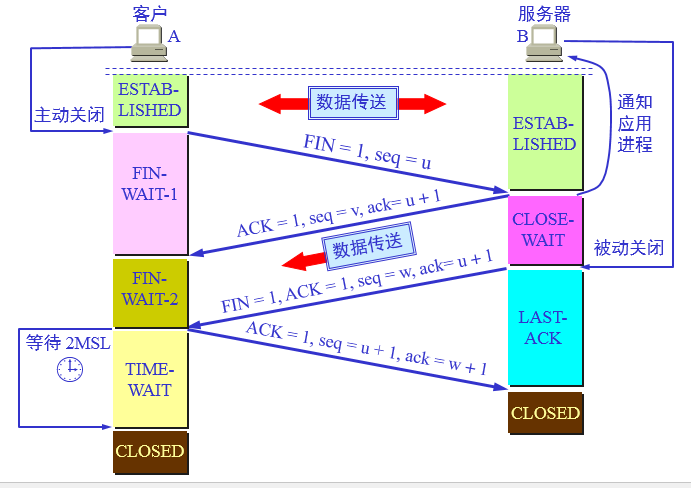
第一次挥手:主机A(可以使客户端,也可以是服务器端),向主机2发送一个FIN 报文段,设置FIN = 1和seq = u ;此时,主机1进入FIN_WAIT_1状态;这表示主机 A 没有数据要发送给主机 B 了;
第二次挥手:主机 B 收到了主机 A 发送的FIN报文段,向主机 A 回一个ACK报文段,ACK = 1, seq = v ,ack = u+1;主机 A 进入FIN_WAIT_2状态;主机 B 告诉主机 A ,你可以关闭,但是我还能向你发送数据;
第三次挥手:主机 B 向主机 A 发送FIN报文段,设置 FIN =1 ,ACK =1 , seq = w, ack = u+1 请求关闭连接,同时主机2进入LAST_ACK状态;
第四次挥手:主机 A 收到主机 B 发送的FIN报文段,向主机 B 发送ACK报文段 ACK =1 , seq = u + 1 , ack = w+1 ,然后主机 A 进入TIME_WAIT状态;主机 B 收到主机A的ACK报文段以后,就关闭连接;此时,主机 A 等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机 A 也可以关闭连接了。
也就说,当客户A 没有东西要发送时就要释放 A 这边的连接,A会发送一个报文(没有数据),其中 FIN 设置为1, 服务器B收到后会给应用程序一个信,这时A那边的连接已经关闭,即A不再发送信息(但仍可接收信息)。 A收到B的确认后进入等待状态,等待B请求释放连接, B数据发送完成后就向A请求连接释放,也是用FIN=1 表示, 并且用 ack = u+1(如图), A收到后回复一个确认信息,并进入 TIME_WAIT 状态, 等待 2MSL 时间。关于这个 2MSL 是为了处理这种情况: B 向 A发送 FIN = 1 的释放连接请求,但这个报文丢失了, A没有接到不会发送确认信息, B 超时会重传,这时A在 WAIT_TIME 还能够接收到这个请求,这时再回复一个确认就行了。(A收到 FIN = 1 的请求后 WAIT_TIME会重新记时)