kubernetes: 深入了解Pod对象
Pod是K8s中最小部署单元,我们实际的应用都是在pod中运行的,首先pod是k8S中最小的部署单元,也是一组容器的集合,可以是一个容器或多个容器去组成,可以理解为一个pod相当于一个虚拟机,在虚拟机里,你可以创建多个应用,应用就是容器。在一个pod中的容器共享一个网络命名空间。Pod是短暂的
Pod容器分类
Infrastructure Container
#基础容器,维护整个POD网络命名空间的,在一个pod中的容器共享一个网络命名空间,就是由基础容器来搞的,当你创建一个应用时,他就会启动起来,对于用户来说是透明的,所以你看到他创建的网络容器,但你能在节点上看到这个容器
[root@k8s02 ~]# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ebd34651f2a4 nginx "nginx -g 'daemon of…" 29 minutes ago Up 29 minutes k8s_nginx_nginx-deployment-59c9f8dff-zrbf2_default_563161af-b117-4e0e-ae02-ca72370b072f_0
c5728b6e0a01 registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0 "/pause" 29 minutes ago Up 29 minutes k8s_POD_nginx-deployment-59c9f8dff-zrbf2_default_563161af-b117-4e0e-ae02-ca72370b072f_0
#你会发现有一个使用pause-amd64镜像启动的容器,如果你有印象会想道这个镜像的地址是在kubelet的配置文件中指定的,也就是这里。
[root@k8s02 ~]# cat /opt/kubernetes/cfg/kubelet.conf
--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0"
#这个镜像默认是在Google镜像仓库拉取的,但是国内无法访问,在你每次创建pod的时候,都会启动一个pause-amd64容器,一一对应的,这个操作用户是没有感知的,用户不知道他还启了个这个。
Init Containers
#这种容器启动优先于业务容器开始执行,之前K8S中,一个pod中有多个容器,容器启动也是没有顺序的,都是并行启动,这种容器会早于业务容器启动,做一些初始化工作。
Containers
业务容器,也就是具体部署你应用程序的容器,并行启动,没有顺讯,所以在你定义了容器类型后,启动顺讯就是Infrastructure Container→Init Containers →Containers,目前容器就分这三类。
Pod共享网络
一个pod创建多个容器,在一个pod中定义两个容器,同一个pod包含两个容器,他们会共享一个网络命名空间,端口和网络都是同一个
[root@k8s01 yml]# vim my_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: nginx
image: nginx
- name: tomcat
image: tomcat
[root@k8s01 yml]# kubectl create -f my_pod.yaml
pod/my-pod created
[root@k8s01 yml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pod 2/2 Running 0 19s
#因为一个pod创建了两个容器所以进入容器加-c
[root@k8s01 yml]# kubectl exec -it my-pod -c nginx bash
root@my-pod:/# exit
[root@k8s01 yml]# kubectl exec -it my-pod -c tomcat bash
root@my-pod:/usr/local/tomcat# cd
root@my-pod:~#
Pod共享存储
通过数据卷挂载进行数据持久化,可以在多个节点上面相互的漂移,emptyDir这个数据卷可以实现多个数据之间的共享
[root@k8s01 yml]# vim my_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod2
spec:
containers:
- name: write
image: centos
command: ["bash","-c","for i in {1..100};do echo $i >> /data/hello;sleep 1;done"]
volumeMounts:
- name: data
mountPath: /data
- name: read
image: centos
command: ["bash","-c","tail -f /data/hello"]
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
emptyDir: {}
#解释
emptyDir 会在k8s工作节点创建一个空目录,名字为data,让容器分别挂载data
[root@k8s01 yml]# kubectl apply -f my_pod.yaml
pod/my-pod2 created
[root@k8s01 yml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pod2 2/2 Running 0 22s
[root@k8s01 yml]#
#验证结果
[root@k8s01 yml]# kubectl exec -it my-pod2 -c write bash
[root@my-pod2 /]# cd /data/
[root@my-pod2 data]# ls
hello
[root@my-pod2 data]# tail -f hello
28
29
30
31
32
33
34
35
36
37
38
^C
[root@my-pod2 data]# exit
[root@k8s01 yml]# kubectl logs my-pod2 read
1
2
3
4
5
6
7
8
9
10
11
12
13
Pod镜像拉取策略
#这个是通过imagePullpolicy这个字段来设置的,目前有三种策略
| 参数 | 描述 |
|---|---|
| IfNotPresent | 默认值,镜像在宿主机上不存在才会拉取 |
| Always | 每次创建一个Pod都会重新拉取一次镜像 |
| Never | Pod永远不会主动拉取这个镜像 |
Pod 拉取私有仓库镜像
私有仓库是需要登陆的,认证过了之后就能下载了,所以在YAML文件中要添加一个imagePullSecrets的认证凭据,在本机登陆了并不代表通过k8S去部署时也是以登陆状态去拉取镜像的,docker和K8S使用的凭证并不是一套,是独立的
#~/.docker目录下,这个文件会保存登陆信息,现在需要将它编码,使用base64
[root@docker01 harbor]# cat ~/.docker/config.json | base64 -w 0
ewoJImF1dGhzIjogewoJCSIxOTIuMTY4LjEwLjgwIjogewoJCQkiYXV0aCI6ICJZV1J0YVc0Nk1USXpORFUyIgoJCX0KCX0sCgkiSHR0cEhlYWRlcnMiOiB7CgkJIlVzZXItQWdlbnQiOiAiRG9ja2VyLUNsaWVudC8xOS4wMy45IChsaW51eCkiCgl9Cn0=
这个就是配置凭据要用到的,然后需要创建一个Secret来管理这个凭据,主要是配置一下加密的数据
[root@k8s01 ~]# cat Secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: registry-secret
data:
.dockerconfigjson: ewoJImF1dGhzIjogewoJCSIxOTIuMTY4LjEwLjgwIjogewoJCQkiYXV0aCI6ICJZV1J0YVc0Nk1USXpORFUyIgoJCX0KCX0sCgkiSHR0cEhlYWRlcnMiOiB7CgkJIlVzZXItQWdlbnQiOiAiRG9ja2VyLUNsaWVudC8xOS4wMy45IChsaW51eCkiCgl9Cn0=
type: kubernetes.io/dockerconfigjson
#然后创建一下
[root@k8s01 ~]# kubectl apply -f Secret.yaml
secret/registry-secret created
[root@k8s01 ~]# kubectl get secrets
NAME TYPE DATA AGE
registry-secret kubernetes.io/dockerconfigjson 1 20s
[root@k8s01 ~]#
可以看到data是1,如果是0说明数据没有保存进去,所以我们现在拿着个名字就可以配置到文件了。
[root@k8s01 yml]# cat nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
imagePullSecrets:
- name: registry-secret
containers:
- image: 192.168.10.80/opesn/nginx:1.16.1
imagePullPolicy: Always
name: nginx
ports:
- containerPort: 80
创建
[root@k8s01 yml]# kubectl apply -f nginx.yaml
#查看创建过程
[root@k8s01 yml]# kubectl describe pods nginx-deployment-5d85999f48-2rzp4
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 116s default-scheduler Successfully assigned default/nginx-deployment-5d85999f48-2rzp4 to k8s03
Normal Pulling 116s kubelet, k8s03 Pulling image "192.168.10.80/opesn/nginx:1.16.1"
Normal Pulled 116s kubelet, k8s03 Successfully pulled image "192.168.10.80/opesn/nginx:1.16.1"
Normal Created 115s kubelet, k8s03 Created container nginx
Normal Started 115s kubelet, k8s03 Started container nginx
Pod资源限制
为了防止一个pod占用资源过高影响到宿主机,在K8S中,资源限制主要分为两个方面,一个是limits,一个是requests。
limits是对资源的总限制,而requests是在pod创建时分配的最低资源,在创建pod的时候,K8S会根据requests值去做调度分配,也就是说如果你现在有N个node,现在需要创建一个pod,但是node1的资源已经满足不了创建pod的requests值,这个pod就不会被调度到node1,只有满足requests这个值的服务器才会被调度过去
[root@k8s01 yml]# cat wordpress.yaml
apiVersion: v1
kind: Pod
metadata:
name: wordpress
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "passwd"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: wp
image: wordpress
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
上面Pod有两个容器。每个容器的requests值为0.25 cpu 和 64MiB内存,因为是两个容器,所以请求最低的资源为0.5 cpu和 128MiB 内存,也就是pod在创建时需要分配的最低资源,这个值会比limits值低。
每个容器的limits值为0.5 cpu和 128MiB 内存,所以这个pod的总限制为1 cpu和256内存,其实上面写的那些他都是通过docker run的一些命令去实现的,request.cpu等同于用--cpu-shares参数去限制,limits.cpu等同于--cpu-quota参数去限制,内存这块相当于是使用--memory值去限制
#创建资源文件
[root@k8s01 yml]# kubectl create -f wordpress.yaml
pod/wordpress created
[root@k8s01 yml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
wordpress 2/2 Running 0 8s
[root@k8s01 yml]# kubectl describe pods wordpress
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/wordpress to k8s03
Normal Pulling 7s kubelet, k8s03 Pulling image "mysql"
Normal Pulled 4s kubelet, k8s03 Successfully pulled image "mysql"
Normal Created 4s kubelet, k8s03 Created container db
Normal Started 4s kubelet, k8s03 Started container db
Normal Pulling 4s kubelet, k8s03 Pulling image "wordpress"
Normal Pulled 1s kubelet, k8s03 Successfully pulled image "wordpress"
Normal Created 1s kubelet, k8s03 Created container wp
Normal Started 0s kubelet, k8s03 Started container wp
可以看到他是被调度到k8s03节点了,然后去看一下k8s03上所有pod的资源利用率。
[root@k8s01 yml]# kubectl describe nodes k8s03
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default wordpress 500m (50%) 1 (100%) 128Mi (6%) 256Mi (13%) 62s
kube-system coredns-6d8cfdd59d-qlp8l 100m (10%) 0 (0%) 70Mi (3%) 170Mi (9%) 43m
kube-system kube-flannel-ds-amd64-t7xsj 100m (10%) 100m (10%) 50Mi (2%) 50Mi (2%) 37h
kubernetes-dashboard dashboard-metrics-scraper-566cddb686-cb2g7 0 (0%) 0 (0%) 0 (0%) 0 (0%) 43m
kubernetes-dashboard kubernetes-dashboard-7b5bf5d559-zqp2h 0 (0%) 0 (0%) 0 (0%) 0 (0%) 43m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 700m (70%) 1100m (110%)
memory 248Mi (13%) 476Mi (25%)
ephemeral-storage 0 (0%) 0 (0%)
可以看到CPU Requests为500,也就是0.5 CPU,CPU Limits为1,也就是1 cpu,Memory Requests为128M,Memory Limits为256M,后面的百分号是代表目前使用了多少,没问题,和指定的一样,删掉就行了
Pod重启策略
决定了pod在故障后所做的动作,这个策略是由restartPolicy参数来设置的,,和--restart的选项几乎一样,一共有三个参数,现默认是Always,也就是说你容器停了,不管是什么原因停的,他就会帮你再启动一个新的,不是重启,pod是没有重启这个概念的,之前的容器挂了就是挂了,不管,他会直接去启一个新的。
| 参数 | 描述 |
|---|---|
| Always | 容器终止退出后总是重启容器,默认策略 |
| OnFailure | 当容器异常退出(退出状态码非0)时才重启容器 |
| Never | 当容器终止退出,从不重启容器 |
指定重启策略
[root@k8s01 yml]# vim nginx_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: web
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
restartPolicy: Never
现在是Never,也就是说你容器停了,再也不会启动了。
Pod健康检查
健康检查,用来检测你容器里应用是否存活,保障应用程序在生产环境存活的重要手段,目前为止Probe有两种类型
| 类型 | 描述 |
|---|---|
| livenessProbe | 如果检查失败,杀死容器,根据pod的restartPolicy来操作 |
| readinessProbe | 如果检查失败,Kubernetes会把Pod从service endpoints中剔除掉 |
livenessProbe 类型
livenessProbe类型的逻辑是这样,restartPolicy策略上文提到过了,也就是重启策略,如果一个容器健康检查失败,就杀了这个容器,根据重启策略去操作,如果是Always就会重新启动一个新的容器,以恢复他的正常工作,以此类推
readinessProbe 类型
service是为pod提供统一入口,endpoints是一个控制器,用来管理所有pod容器的IP的,下面看一下
[root@k8s01 yml]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 3d20h
nginx-service NodePort 10.0.0.39 <none> 80:32301/TCP 14s
[root@k8s01 yml]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.10.91:6443,192.168.10.94:6443 3d20h
nginx-service 10.244.0.24:80,10.244.1.53:80,10.244.2.19:80 28s
[root@k8s01 yml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-576cc76cc7-frs8l 1/1 Running 0 36m
nginx-deployment-576cc76cc7-kps4d 1/1 Running 0 36m
nginx-deployment-576cc76cc7-tswqm 1/1 Running 0 36m
上面提到了ENDPOINTS也是一个控制器,他的作用就是动态感知你所有pod的是由哪些IP组成的,这个IP也就是容器的IP,上图可以看到nginx的pod是由三个容器组成的,也有相对应的三个容器IP,并且这个pod被关联到了名为nginx-service的service,可以理解为ENDPOINTS控制器相当于一个地址池,但这个地址池是动态的。
service只是提供了一个负载均衡入口,他并不能知道service所关联的pod是哪些容器IP组成的,所以动态感知这些信息是由ENDPOINTS控制器去做的,这样service才知道要把请求转发到哪里。
所以readinessProbe类型的健康检查失败之后,他的逻辑就是将健康检查失败容器的IP在下面的列表中剔除掉。
健康检查方法
目前健康检查有三种方法
| 方法 | 描述 |
|---|---|
| httpGet | 发送http请求,返回200-400状态码视为成功 |
| exec | 执行shell命令返回状态码为0视为成功 |
| tcpSocket | 发起TCP Socket 建立成功视为成功 |
看实际情况选择使用哪种方法吧,说白了httpGet就是获取http响应头的状态码,exec就是在容器内执行一条命令去判断返回码,tcpSocket就是判断能否和目标端口建立连接
httpGet
常用参数如下
| 参数 | 描述 |
|---|---|
| path | http服务器上请求访问的路径 |
| port | 要访问容器上的哪个端口 |
| scheme | 连接端口的协议(HTTP/HTTPS),默认HTTP(要大写) |
| initialDelaySeconds | 容器启动多长时间开始健康检查 |
| periodSeconds | 监控频率,默认10s,最小1s |
| timeoutSeconds | 超时秒数,默认1s,最小值为1s |
| successThreshold | 检查失败之后最小成功连续次数,默认1,活跃度必须为1 |
| failureThreshold | 检查失败次数,超了这个次数直接根据重启策略进行操作 |
[root@k8s01 yml]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /
port: 81
scheme: HTTP
initialDelaySeconds: 3
timeoutSeconds: 1
periodSeconds: 5
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /
port: 81
scheme: HTTP
initialDelaySeconds: 3
timeoutSeconds: 1
periodSeconds: 5
successThreshold: 1
failureThreshold: 3
这个Deployment两种检查方法都加上了,常用的参数就这些,端口是故意写错的
[root@k8s01 yml]# kubectl create -f deployment.yaml
deployment.apps/nginx-deployment created
[root@k8s01 yml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 0/1 Completed 0 44m
nginx-deployment-67c9769f5c-6c85s 0/1 Running 5 3m50s
nginx-deployment-67c9769f5c-6m5gb 0/1 CrashLoopBackOff 5 3m50s
nginx-deployment-67c9769f5c-lcv66 0/1 Running 5 3m50s
可以看到无法启动了,其实端口不对,检查失败,无限重启
[root@k8s01 yml]# kubectl describe pods nginx-deployment-67c9769f5c-lcv66
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/nginx-deployment-67c9769f5c-lcv66 to k8s05
Normal Pulled 28s (x2 over 61s) kubelet, k8s05 Successfully pulled image "nginx:latest"
Normal Created 28s (x2 over 61s) kubelet, k8s05 Created container nginx
Normal Started 28s (x2 over 61s) kubelet, k8s05 Started container nginx
Warning Unhealthy 17s (x5 over 57s) kubelet, k8s05 Readiness probe failed: Get http://10.244.2.21:81/: dial tcp 10.244.2.21:81: connect: connection refused
Normal Pulling 14s (x3 over 85s) kubelet, k8s05 Pulling image "nginx:latest"
Warning Unhealthy 14s (x6 over 54s) kubelet, k8s05 Liveness probe failed: Get http://10.244.2.21:81/: dial tcp 10.244.2.21:81: connect: connection refused
Normal Killing 14s (x2 over 44s) kubelet, k8s05 Container nginx failed liveness probe, will be restarted
可以看到在健康检查时连接被拒绝,接下来容器被杀死后重新创建,说明健康检查没有问题,现在已经进入无限重启的状态了,从Started到被Killing用了18,秒简单算一下,用上文的健康检查配置,pod内应用需要在多少秒内启动才不会被杀。
第一个参数initialDelaySeconds设置的3,也就是容器启动三秒后开始检查,如果响应时间超过一秒认为失败(timeoutSeconds),然后开始重试三次(failureThreshold),每隔五秒进行一次尝试(periodSeconds),如果这三次内有一次成功则认为成功(successThreshold),如果这三次都失败就会根据重启策略进行下一步操作,所以满打满算就是3(容器启动后时间)+3(超时时间)+15(每隔五秒重试三次时间)总共二十一秒,但是实际时间会比这个短一点,如你上文所看到的,所以根据你实际情况对参数进行修改吧,其实只添加initialDelaySeconds&periodSeconds就可以了,剩下的用默认的就够了,下面试试exec方法的。
exec
这种方法就是在容器中执行命令,命令返回结果为0表示健康
[root@k8s01 yml]# cat nginx_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: web
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
livenessProbe:
exec:
command:
- cat
- /etc/nginx/nginx.conf
initialDelaySeconds: 3
periodSeconds: 5
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
我定义的健康检查方式为cat /etc/nginx/nginx.conf这个文件,如果这条命令能执行成功就算健康的,一会正常启动之后吧nginx.conf文件删了就cat不到了
[root@k8s01 yml]# kubectl create -f nginx_pod.yaml
[root@k8s01 yml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 22s
[root@k8s01 yml]#
正常启动了,然后去容器里把/etc/nginx/nginx.conf文件删了。
[root@k8s01 ~]# kubectl describe pods nginx
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/nginx to k8s02
Normal Pulling 59s (x2 over 2m24s) kubelet, k8s02 Pulling image "nginx:latest"
Warning Unhealthy 59s (x3 over 69s) kubelet, k8s02 Liveness probe failed: cat: /etc/nginx/nginx.conf: No such file or directory
Normal Killing 59s kubelet, k8s02 Container nginx failed liveness probe, will be restarted
Normal Pulled 44s (x2 over 2m9s) kubelet, k8s02 Successfully pulled image "nginx:latest"
Normal Created 44s (x2 over 2m9s) kubelet, k8s02 Created container nginx
Normal Started 43s (x2 over 2m9s) kubelet, k8s02 Started container nginx
还是检查失败容器重启了,这个也可以执行脚本,所以这个适合检查比较复杂的应用程序
tcpSocket
[root@k8s01 yml]# cat nginx_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: web
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 3
periodSeconds: 5
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
[root@k8s01 yml]#
[root@k8s01 yml]# kubectl create -f nginx_pod.yaml
[root@k8s01 yml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 22s
[root@k8s01 yml]#
健康检查检查的是80端口,现在把默认的端口换了,重载nginx
root@nginx:/# sed -i 's#80#81#g' /etc/nginx/conf.d/default.conf
root@nginx:/# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
root@nginx:/# nginx -s reload
2020/05/29 08:26:51 [notice] 17#17: signal process started
root@nginx:/# command terminated with exit code 137
[root@k8s01 yml]#
被杀了,看一下现在的状态。
[root@k8s01 yml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 1 2m32s
[root@k8s01 yml]#
[root@k8s01 yml]# kubectl describe pods nginx
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/nginx to k8s02
Normal Pulling 55s (x2 over 2m52s) kubelet, k8s02 Pulling image "nginx:latest"
Warning Unhealthy 55s (x3 over 65s) kubelet, k8s02 Liveness probe failed: dial tcp 10.244.0.33:80: connect: connection refused
Normal Killing 55s kubelet, k8s02 Container nginx failed liveness probe, will be restarted
Normal Pulled 54s (x2 over 2m40s) kubelet, k8s02 Successfully pulled image "nginx:latest"
Normal Created 54s (x2 over 2m40s) kubelet, k8s02 Created container nginx
Normal Started 54s (x2 over 2m40s) kubelet, k8s02 Started container nginx
阔以看到健康检查失败了,容器被杀重启了,这个tcpSocket比较适合去检查非http服务,像是什么zookeeper&redis之类的东西
健康检查的使用目的就是为了防止容器内的服务异常,如果出现异常会重建容器,保证pod的可用性,在加了健康检查之后,在服务滚动更新创建或是扩展的时候,如果容器健康检查失败,这个容器是不会对外提供服务的,直到健康检查成功之后才会接收请求,生产环境必加。
Pod调度约束
目的是可以将制定的Pod调度的制定的节点上,默认的调度是根据节点的资源利用率去调度,在我们用命令行创建一个Pod的时候,他大概会经历这些步骤。
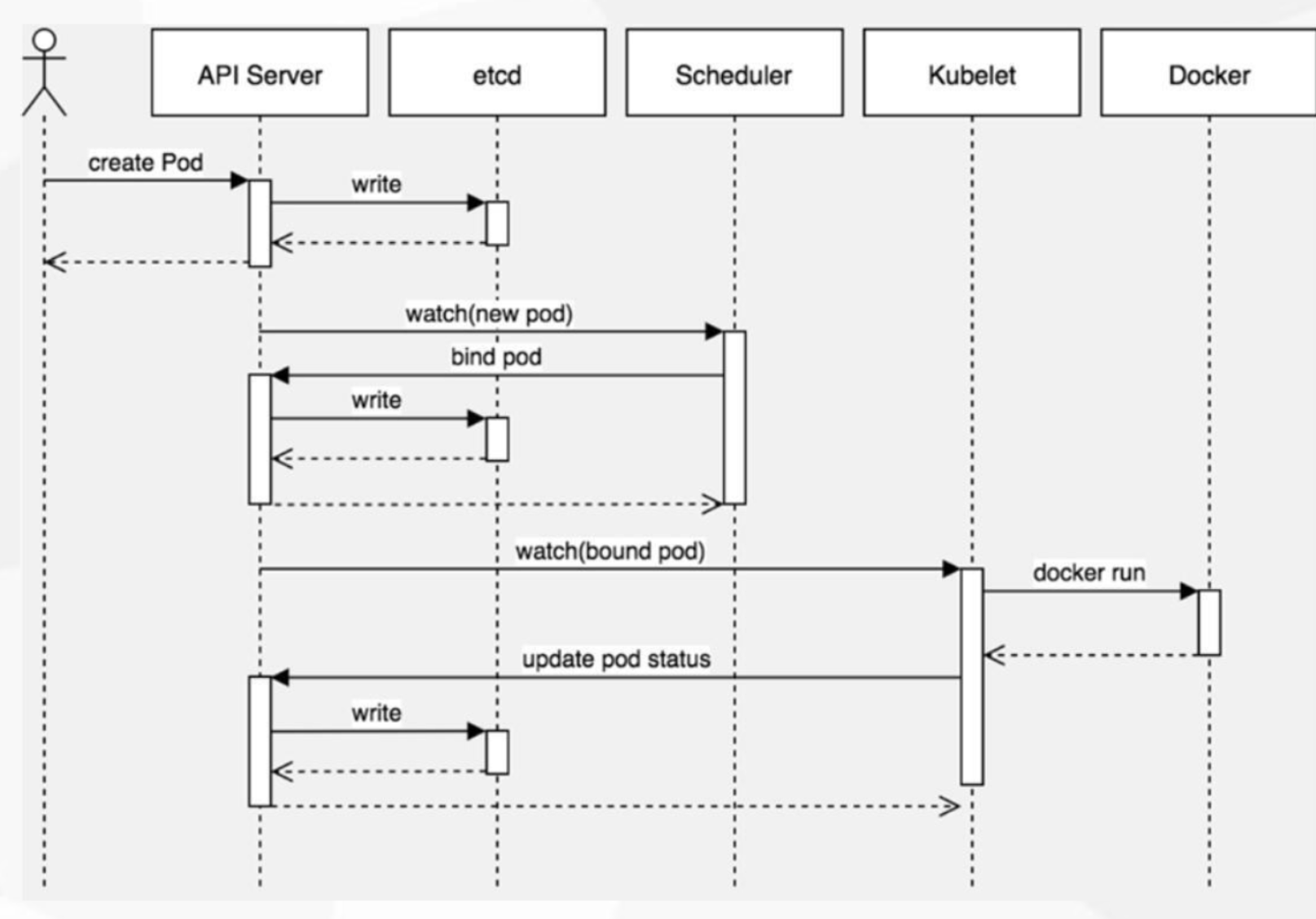
基于write的机制来做组件之间的协作,当用户创建一个pod时,apiserver接收到创建pod的请求,apiserver会将写请求写入到etcd中,你要创建什么样的pod,pod具有什么属性,都会被写进去。
然后Scheduler调度器通过watch获取到etcd中创建的新pod,调度器根据调度算法,选出新创建的pod应该被调度到那个节点上,然后更新到etcd中,kubectl也会通过watch在etcd中获取到绑定自己的pod,这个的理解就是譬如我当前是node-1上的kubelet,我就会拉取etcd中绑定到node-1的pod,获取到之后通过docker run 将容器启动起来,启动起来之后再更新到etcd中,就是报告当前pod的状态,是ContainerCreating状态还是Running状态,我们通过kubectl get pod去查看的时候,会再次向apiserver发送一个请求,他会获取到etcd中当前pod的状态,然后展现给用户的,调度的流程就是这样。
调度约束
| 字段 | 释义 |
|---|---|
| nodeName | 用于将Pod调度到指定的Node名称上 |
| nodeSelector | 用于将Pod调度到匹配Label的Node上 |
nodeName
指定到k8s02节点上运行
[root@k8s01 yml]# cat nginx_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: web
spec:
nodeName: k8s02
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
[root@k8s01 yml]# kubectl create -f nginx_pod.yaml
pod/nginx created
[root@k8s01 yml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 41s 10.244.0.34 k8s02 <none> <none>
[root@k8s01 yml]#
大概就是这样,现在就是在k8s02上面了
nodeSelector
既然是使用标签,就需要先给Node节点打一下标签,下面给节点打一个标签
[root@k8s01 yml]# kubectl label nodes k8s02 regin=node-1
node/k8s02 labeled
[root@k8s01 yml]# kubectl label nodes k8s03 regin=node-2
node/k8s03 labeled
[root@k8s01 yml]# kubectl label nodes k8s05 regin=node-3
node/k8s05 labeled
[root@k8s01 yml]#
可以看到有一些默认的标签,这是K8S默认为node打的标签
[root@k8s01 yml]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s02 Ready <none> 3d19h v1.16.10 regin=node-1
k8s03 Ready <none> 3d18h v1.16.10 regin=node-2
k8s05 Ready <none> 2d23h v1.16.10 regin=node-3
[root@k8s01 yml]#
#删除标签的方法
kubectl label nodes k8s02 regin-
指定pod只能运行在标签为node-3`节点上
[root@k8s01 yml]# cat nginx_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: web
spec:
nodeSelector:
regin: node-3
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
[root@k8s01 yml]# kubectl create -f nginx_pod.yaml
pod/nginx created
[root@k8s01 yml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 26s 10.244.2.22 k8s05 <none> <none>
[root@k8s01 yml]#
Pod故障排查

出现如上问题可以使用以下三个命令去排查。
使用kubectl describe查看pod的事件,使用kubectl logs查看容器内日志,使用kubect exec进入到容器中查看应用处于什么样的状态,所以需要了解一个调度的流程