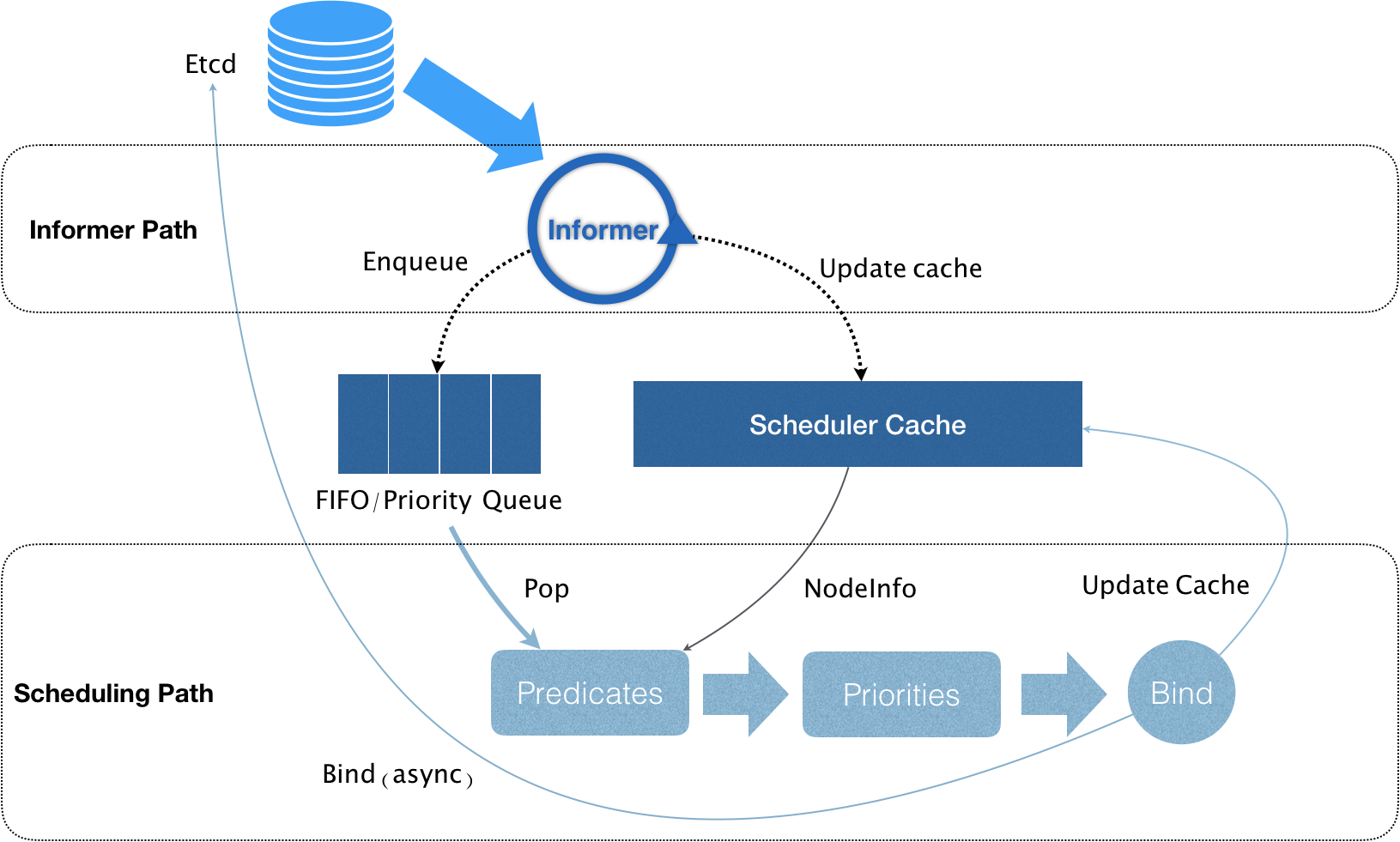
如果想要了解调度器中各预选、优选算法的具体实现,可看hutao的源码解析:https://github.com/daniel-hutao/k8s-source-code-analysis
自定义调度器
修改pod的spec.schedulerName为自定义调度器名称如my-scheduler,那么default-scheduler就会忽略这个pod,此时自己实现的调度器就可以不断的从api-server中获取spec.schedulerName为my-scheduler的pod,并根据具体逻辑选择合适的节点,最终将pod的spec.nodeName设置为选择的节点,并更新etcd
默认调度器中的调度算法分为预选和优选
预选策略
1.基础的检查项(GeneralPredicates)
PodFitsResources node剩余可分配资源(Allocatable-sum(request))是否足够pod调度
PodFitsHost node的名称是否跟pod的spec.nodeName字段一致
PodFitsHostPorts pod指定的spec.nodePort端口在待考察node上是否已被占用
PodMatchNodeSelector pod的nodeSelector或者nodeAffinity指定的节点是否与待考察节点匹配
2.Volume相关:
NoDiskConflict 待调度pod声明使用的Volume是否与待考察node上的已有pod声明挂载的Volume有冲突(AWS EBS类型的Volume,是不允许被两个Pod同时使用的)
MaxPDVolumeCountPredicate node上某种类型的持久化Volume是不是已经超过了一定数目
VolumeZonePredicate pod声明使用的Volume的Zone(高可用域)标签是否与待考察节点的Zone标签相匹配
VolumeBindingPredicate Pod对应的pvc所绑定的pv的nodeAffinity字段,是否跟某个节点的标签相匹配(LPV的延迟绑定机制)
3.Node相关:
CheckNodeCondition:校验节点是否准备好被调度,校验node.condition的condition type :Ready为true和NetworkUnavailable为false以及Node.Spec.Unschedulable为false
PodToleratesNodeTaints pod是否能够容忍待考察节点的污点
NodeMemoryPressurePredicate 待考察节点的内存是不是已经不够充足
4. Pod相关:
PodAffinityPredicate 检查待调度Pod与Node上的已有Pod之间的亲密(affinity)和反亲密(anti-affinity)关系(pod中配置的spec.affinity.podAntiAffinity.requiredDuringSchedulingIgnoredDuringExecution属性)
说明
1.当开始调度一个Pod时,Kubernetes调度器会同时启动16个Goroutine,来并发地为集群里的所有Node计算Predicates,最后返回可以运行这个Pod的宿主机列表
2.为每个Node执行Predicates时,调度器会按照固定的顺序来进行检查。这个顺序,是按照Predicates本身的含义来确定的。比如,宿主机相关的Predicates会被放在相对靠前的位置进行检查。要不然的话,在一台资源已经严重不足的宿主机上,上来就开始计算PodAffinityPredicate,是没有实际意义的。
优选策略
LeastRequestedPriority 选择cpu剩余量和memory剩余量的和最多的宿主机,即把 Pod 分到资源空闲率最高的节点上,而非空闲资源最大的节点(相反的是MostRequestedPriority)
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
BalancedResourceAllocation 各种资源分配最均衡的那个节点(避免一个节点上CPU被大量分配、而 Memory 大量剩余)
选择资源Fraction差距最小的节点
Fraction = Pod请求的资源 / 节点上的可用资源
variance = 每两种资源 Fraction 之间的距离
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10
ServiceSpreadingPriority 同一个service管控下的pod尽量分散在不同的节点
参考文档
https://kubernetes.io/docs/concepts/scheduling/scheduler-perf-tuning/
http://dockone.io/article/2885
https://www.cnblogs.com/buyicoding/p/12186315.html
腾讯关于动态调度的讨论:https://www.infoq.cn/article/wyjT7HApETsiEAMoiL7Z