Oracle数据库学习教程
其他数据库对象
视图
从表中抽出的逻辑上相关的数据集合。
所以:1. 视图基于表。2. 视图是逻辑概念。3. 视图本身没有数据。
视图的目的,就是简化查询,不要通过视图做insert,update,delete操作
视图创建和删除和表类似:只需把table-->view
一般是将表的查询结果分配给视图.
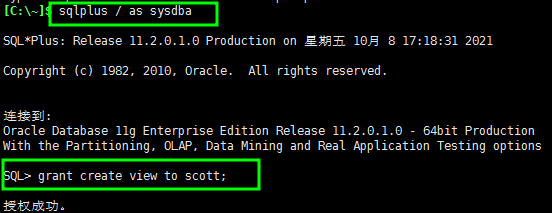
需要先授权scott创建视图的权限
create/replace view view_name AS select * from emp;
视图的优点:
- 简化复杂查询:原来分组、多表、子查询等可以用一条select * from xxxview代替。视图可以看做是表的复杂的SQL一种封装。
- 限制数据访问:只看视图的结构和数据是无法清楚视图是怎样得来的。可以限制数据的访问。例如:银行项目,所谓的各个“表”都是“视图”,并有可能只是“只读视图”
注意:1. 视图不能提高性能 2. 不建议通过视图对表进行修改。
序列
序列是oracle用来生产一组等间隔的数值。序列是递增,而且连续的。oracle主键没有自增类型,所以一般使用序列产生的值作为某张表的主键,实现主键自增。序列的编号不是在插入记录的时候自动生成的,必须调用序列的方法来生成(一般调用nextval方法)。我们也可以编写表的insert触发器来进自动生成。
1.创建序列:
创建序列需要CREATE SEQUENCE系统权限。序列的创建语法如下:
CREATE SEQUENCE 序列名
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE/ MINVALUE n| NOMAXVALUE}]
[{CYCLE|NOCYCLE}]
[{CACHE n| NOCACHE}];
其中:
- INCREMENT BY用于定义序列的步长,如果省略,则默认为1,如果出现负值,则代表Oracle序列的值是按照此步长递减的。
- START WITH 定义序列的初始值(即产生的第一个值),默认为1。
- MAXVALUE 定义序列生成器能产生的最大值。选项NOMAXVALUE是默认选项,代表没有最大值定义,这时对于递增Oracle序列,系统能够产生的最大值是10的27次方;对于递减序列,最大值是-1。
- MINVALUE定义序列生成器能产生的最小值。选项NOMAXVALUE是默认选项,代表没有最小值定义,这时对于递减序列,系统能够产生的最小值是?10的26次方;对于递增序列,最小值是1。
- CYCLE和NOCYCLE 表示当序列生成器的值达到限制值后是否循环。CYCLE代表循环,NOCYCLE代表不循环。如果循环,则当递增序列达到最大值时,循环到最小值;对于递减序列达到最小值时,循环到最大值。如果不循环,达到限制值后,继续产生新值就会发生错误。
- CACHE(缓冲)定义存放序列的内存块的大小,默认为20。NOCACHE表示不对序列进行内存缓冲。对序列进行内存缓冲,可以改善序列的性能。
大量语句发生请求,申请序列时,为了避免序列在运用层实现序列而引起的性能瓶颈。Oracle序列允许将序列提前生成 cache x个先存入内存,在发生大量申请序列语句时,可直接到运行最快的内存中去得到序列。但cache个数也不能设置太大,因为在数据库重启时,会清空内存信息,预存在内存中的序列会丢失,当数据库再次启动后,序列从上次内存中最大的序列号+1 开始存入cache x个。这种情况也能会在数据库关闭时也会导致序号不连续。 - NEXTVAL 返回序列中下一个有效的值,任何用户都可以引用。
- CURRVAL 中存放序列的当前值,NEXTVAL 应在 CURRVAL 之前指定 ,二者应同时有效。
例子:create sequence t1_seq increment by 1 start with 1;
使用:t1_seq.nextval返回当前序列,产生下一个序列号,t1_seq.currval仅仅返回序列的当前值.
2.查询序列
- 通过数据字典USER_OBJECTS可以查看用户拥有的序列。
- 通过数据字典USER_SEQUENCES可以查看序列的设置。
3.删除序列用drop sequence t1_seq;
索引
相当于目录,用于提高数据检索速度;建立索引后,执行select语句的时候会先检查索引.
CREATE [UNIQUE] | [BITMAP] INDEX index_name --unique表示唯一索引
ON table_name([column1 [ASC|DESC],column2 --bitmap,创建位图索引
[ASC|DESC],…] | [express])
[TABLESPACE tablespace_name]
[PCTFREE n1] --指定索引在数据块中空闲空间
[STORAGE (INITIAL n2)]
[NOLOGGING] --表示创建和重建索引时允许对表做DML操作,默认情况下不应该使用
[NOLINE]
[NOSORT]; --表示创建索引时不进行排序,默认不适用,如果数据已经是按照该索引顺序排列的可以使用