因子分解机系列--FM
1.FM背景
FM (Factorization Machine) 主要是为了解决数据稀疏的情况下,特征怎样组合的问题。目前主要应用于CTR预估以及推荐系统中的概率计算。下图是一个广告分类的问题,根据用户和广告位相关的特征,预测用户是否点击了广告。图片来源,详见参考1。
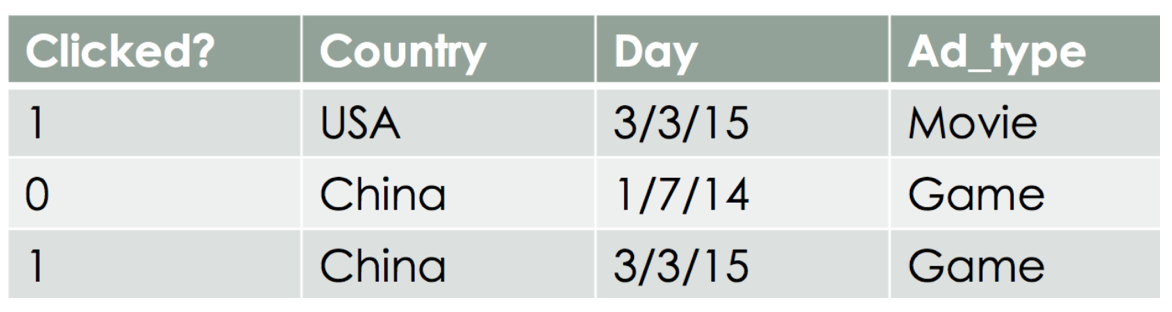
如上图,clicked?为要预测label,由Country,Day,Ad_type三列共同决定。由于此三列都为category类别特征,很多模型不能直接用其来预测,所以需要先转化为one-hot特征,即:

对于one-hot编码后的特征,可以看到目前是7维,但对每一条样本,平均只有3维特征有非0值,换言之样本数据是很稀疏的,特别是在电商领域,例如一个商品品类有几百种,那么one-hot后就是几百个特征就只有一列值为1。
正如上图中数据,在某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”。这种关联特征也很符合我们的主观逻辑,比如'女'和'化妆品'、'男'和'篮球'。因此,引入两个特征的组合作为新特征是非常有意义的。
2.FM模型
多项式模型是包含特征组合的最直观的模型。在多项式模型中,特征 xi 和 xj 的组合采用 xixj 表示,即 xi 和 xj 都非零时,组合特征 xixj 才有意义。模型如下:
其中,n 代表样本的特征数量,xi 是第 i 个特征的值,w0、wi、wij 是模型参数。这里我认为还有i的取值为1到n-1,j的取值是i+1到n,因为特征自己与自己结合没有意义。(虽然很多资料都是1到n,如果有错请指出)
相较与一般的线性模型,FM模型多了后半部分,也就是特征组合的部分。
从公式(1)可以看出,组合特征的参数一共有 n*(n−1)/2 个,因为特征要两两组合,而任意两个参数都是独立的。对于每个wij都需要xi和xj都非0的样本来训练,而样本数据又很稀疏,可想而知wij应该不会训练的太准确。
3.FM求解
问题来了,如何求解二次项次数呢?很自然的想到了矩阵分解。在model-based的协同过滤中,一个rating矩阵可以分解为user矩阵和item矩阵,每个user和item都可以采用一个隐向量表。比如下图,我们把每个user表示成一个二维向量,同时把每个item表示成一个二维向量,(这里也就是k=2) 两个向量的点积就是矩阵中user对item的打分。

所有二次项的系数构成一个二维矩阵W,这个矩阵就可以分解为 W=VV^T,V的第i行便是第i维特征的隐向量。换句话说,每个参数Wij = <Vi,Vj>。那现在要求Wij只要能求出辅助向量vi和vj即可。V定义如下:
那么Wij可以表示为:
那么相应的W不就可以表示为:
而我们要求的二次项系数,即是VV^T矩阵对角线的右下或左下部分。当然这里只考虑的是二阶多项式模型。此时FM模型应为:
<Vi,Vj>其实就是向量的点乘。
根据(3)式,我们来计算下复杂度。这里设V为k维。(我是这样计算的,如果有差别也应该是常数的差别)。
不过这里可以对(3)式进行化简,时间复杂度就可以减少为线性的了。具体如下,这里记住Wij是W矩阵去除主对角线的一半就很好理解了。
利用SGD来训练参数,
对于当Theta=Vif时,第一个求和公式中
是与i无关的,在每次迭代过程中,只需计算一次所有 f 的,就可以求得所有 vi,f 的梯度。显然计算所有f的的复杂度是O(kn),此时再计算每个参数梯度的复杂度是O(1),得到梯度后,更新每个参数的复杂度也是O(1);模型参数一共有nk + n + 1个。因此,FM参数训练的复杂度也是O(kn)。综上可知,FM可以在线性时间训练和预测,是一种非常高效的模型。
4.相关代码
Github: https://github.com/Alarical/Recommend/tree/master/FM
参考github上大佬的FM-tensorflow实现(加了些注释,捂脸)。代码主要部分就是在函数中vectorize_dic,该函数是来构造一个矩阵,每行中有2个元素为1,方便后续做交叉特征,其他部分都是很平常的tf语句,结合注释很容易理解。
5.参考资料
http://www.cs.cmu.edu/~wcohen/10-605/2015-guest-lecture/FM.pdf
https://github.com/babakx/fm_tensorflow/blob/master/fm_tensorflow.ipynb
https://www.jianshu.com/p/152ae633fb00
https://tech.meituan.com/2016/03/03/deep-understanding-of-ffm-principles-and-practices.html
https://www.cnblogs.com/ljygoodgoodstudydaydayup/p/6340129.html