
1、CPU 的流水线设计的三大冒险
结构冒险(Structural Hazard)、数据冒险(Data Hazard)以及控制冒险(Control Hazard)。
2、结构冒险
结构冒险的本质是硬件层面资源的竞争。CPU 在同一个时钟周期,同时在运行两条计算机指令的不同阶段。但是这两个不同的阶段,可能会用到同样的硬件电路。
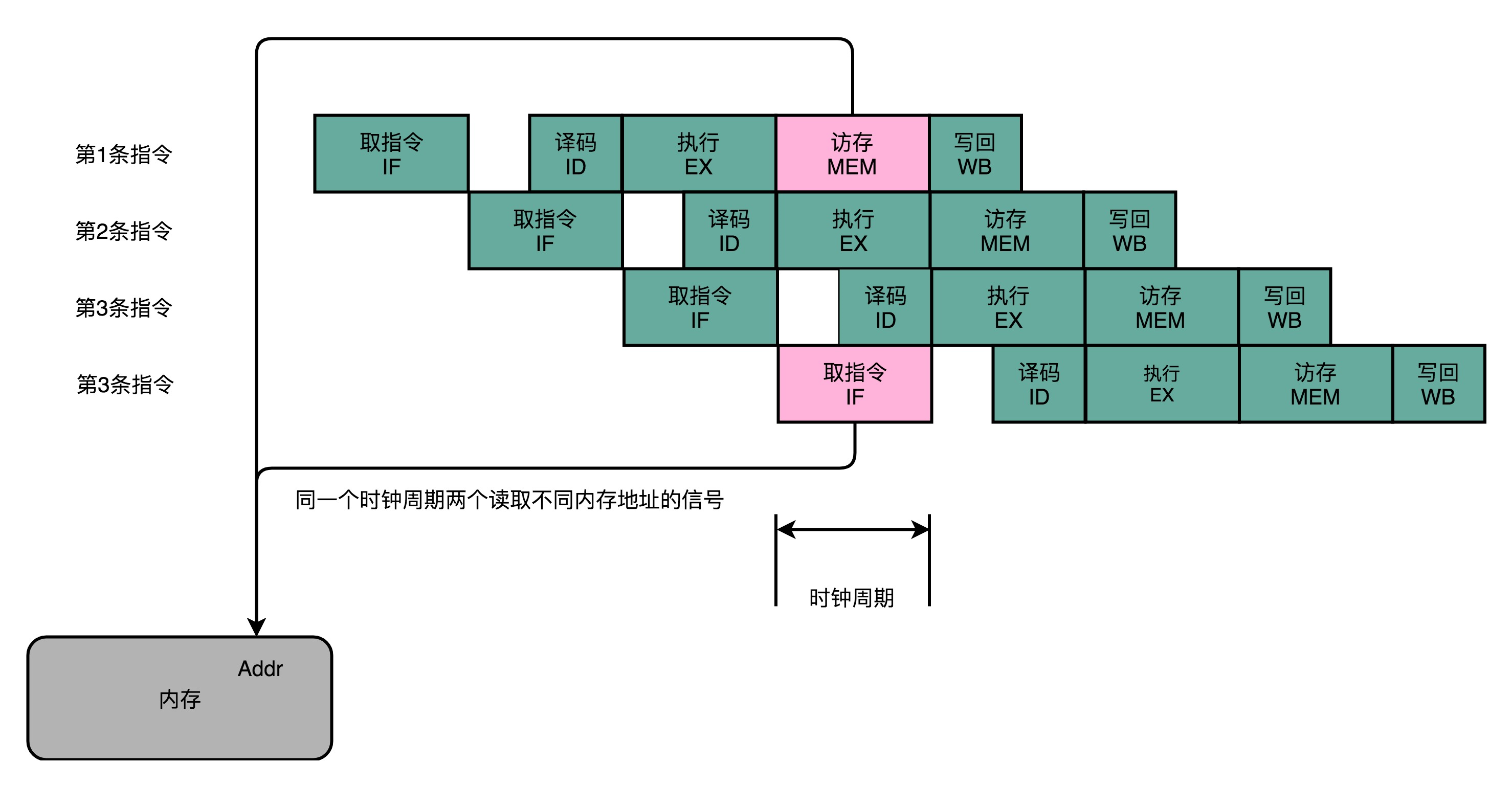
可以看到,在第 1 条指令执行到访存(MEM)阶段的时候,流水线里的第 4 条指令,在执行取指令(Fetch)的操作。访存和取指令,都要进行内存数据的读取。内存只有一个地址译码器的作为地址输入,那就只能在一个时钟周期里面读取一条数据,没办法同时执行第 1 条指令的读取内存数据和第 4 条指令的读取指令代码。解决这种资源冲突的本质方法就是增加资源,在 CPU 的结构冒险里面。对于访问内存数据和取指令的冲突,一个直观的解决方案就是内存分成两部分,让它们各有各的地址译码器。这两部分分别是存放指令的程序内存和存放数据的数据内存。
现代的 CPU 并不会直接读取主内存。它会从主内存把指令和数据加载到高速缓存中,这样后续的访问都是访问高速缓存。而指令缓存和数据缓存的拆分,使得 CPU 在进行数据访问和取指令的时候,不会再发生资源冲突的问题了。
3、数据冒险
数据冒险是程序逻辑层面的事,有三种类型:分别是先写后读(Read After Write,RAW)、先读后写(Write After Read,WAR)和写后再写(Write After Write,WAW)。
先写后读:先把数据写在内存里面,然后再把这个内存地址里面的数据写到寄存器里面,先写后读所面临一个数据依赖。如果顺序不鞥不能保证,程序就会报错。这个先写后读的依赖关系,一般被称之为数据依赖。
先读后写:把寄存器里面的数据读出来,再把数据写进寄存器。先读后写的依赖,一般被叫作反依赖。
写后再写:写入内存地址的两个数据需要有先后顺序,这种依赖称为输出依赖。
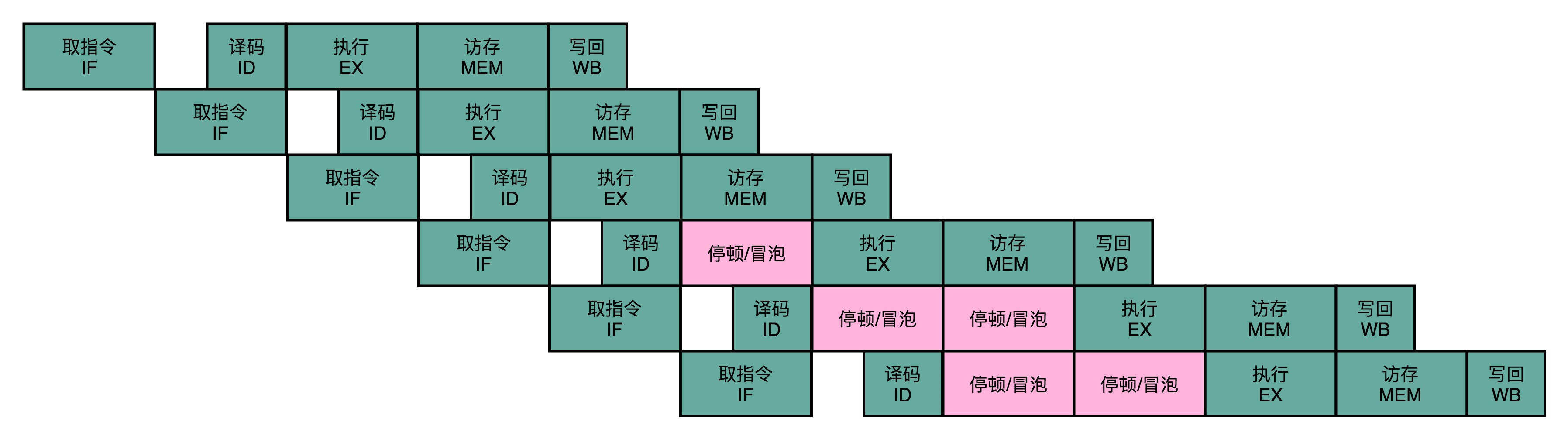
同一个寄存器或者内存地址的操作,都有明确强制的顺序要求。而这个顺序操作的要求,也为使用流水线带来了很大的挑战。因为流水线架构的核心,就是在前一个指令还没有结束的时候,后面的指令就要开始执行。解决这个问题最简单的办法就是流水线停顿,也叫做流水线冒泡。
就是执行后面的指令,进行指令译码的时候,会拿到对应指令所需要访问的寄存器和内存地址。能够判断出来,这个指令是否会触发数据冒险。如果会触发数据冒险,插入无效的NOP操作,让整个流水线停顿一个或者多个周期。
4、操作数前推
结构冒险:增加资源。
数据冒险:流水线停顿。
这两种解决方法比较死板,还会造成资源的浪费。
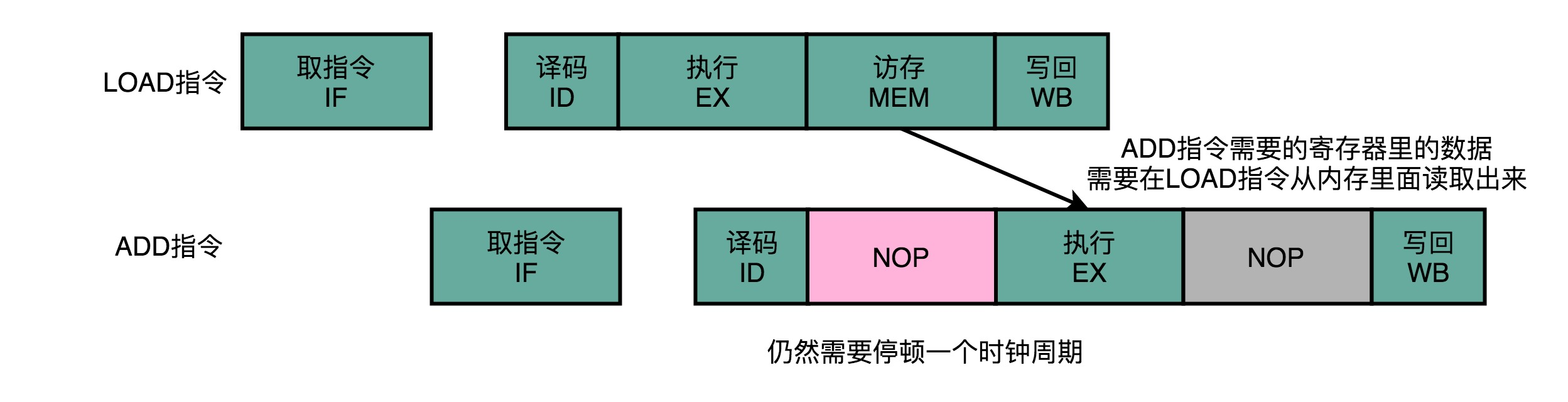
另一个解决方法:操作数前推。可以在第一条指令的执行阶段完成之后,直接将结果数据传输给到下一条指令的 ALU。然后,下一条指令不需要再插入两个 NOP 阶段,就可以继续正常走到执行阶段。也就是在第 1 条指令的执行结果,直接“转发”给了第 2 条指令的 ALU 作为输入。不但可以单独使用,还可以和流水线冒泡一起使用。
5、乱序执行
在流水线里,后面的指令不依赖前面的指令,那就不用等待前面的指令执行,它完全可以先执行。
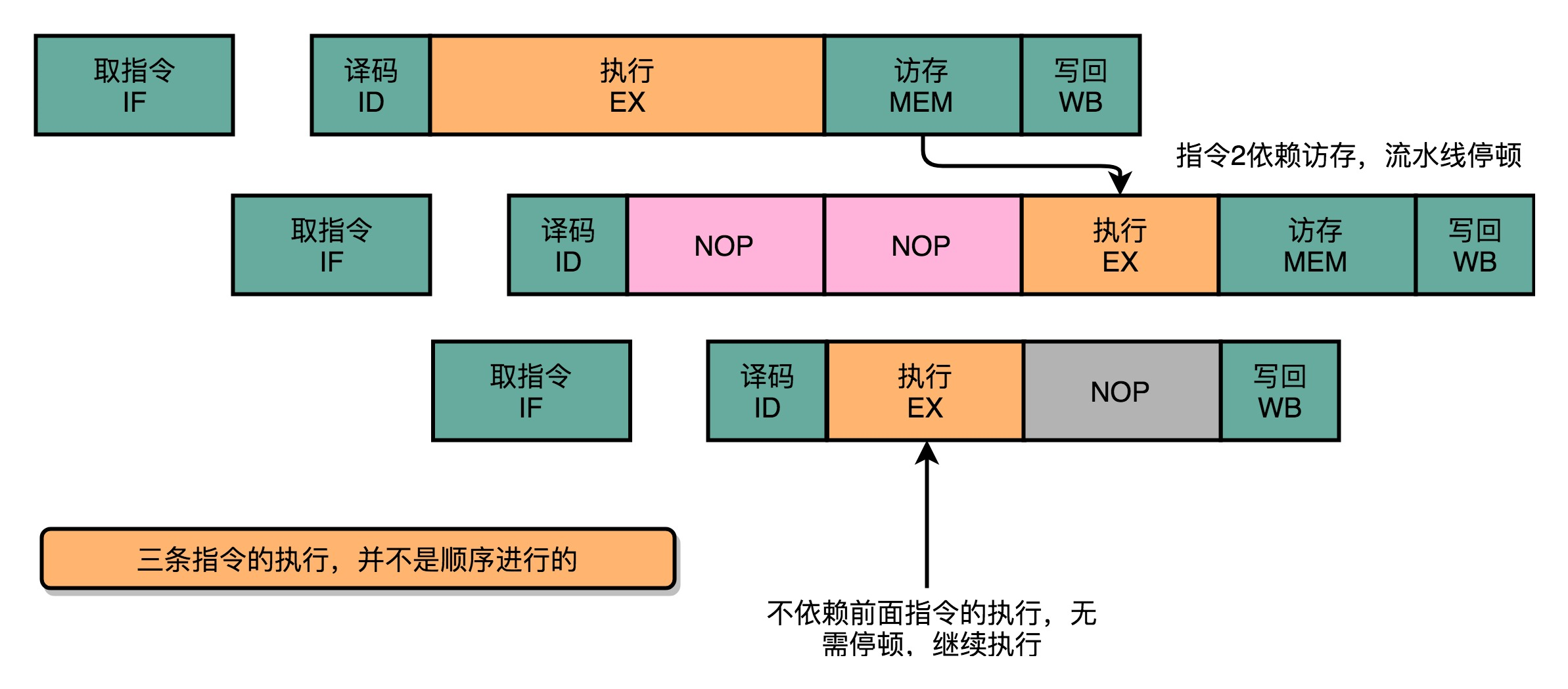
可以看到,因为第三条指令并不依赖于前两条指令的计算结果,所以在第二条指令等待第一条指令的访存和写回阶段的时候,第三条指令就已经执行完成了。
CPU实现乱序执行的方式:
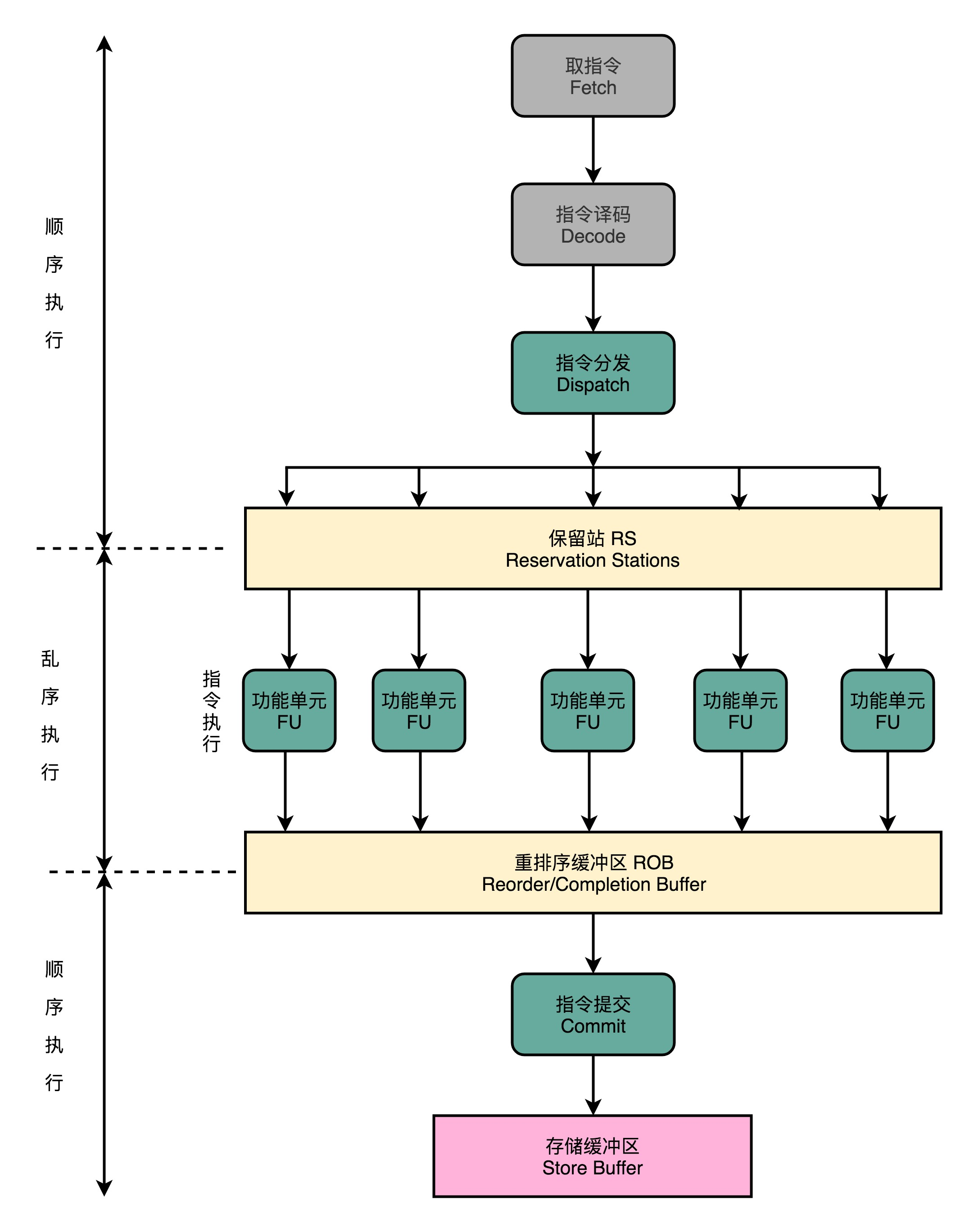
(1)在取指令和指令译码的时候,CPU还是在按顺序工作
(2)指令译码完成之后CPU进行一次指令分发,把指令发到一个叫作保留站(Reservation Stations)的地方。
(3)这些指令不会立刻执行,而要等待它们所依赖的数据,传递给它们之后才会执行。
(4)一旦指令依赖的数据来齐了,指令就可以交到后面的功能单元(Function Unit,FU),其实就是 ALU,去执行了。很多功能单元可以并行运行,但是不同的功能单元能够支持执行的指令并不相同。
(5)指令执行的阶段完成之后,把结果存放到一个叫作重排序缓冲区(Re-Order Buffer,ROB)的地方。
(6)在重排序缓冲区里,CPU 会按照取指令的顺序,对指令的计算结果重新排序。只有排在前面的指令都已经完成了,才会提交指令,完成整个指令的运算结果。
(7)实际的指令的计算结果数据,并不是直接写到内存或者高速缓存里,而是先写入存储缓冲区(Store Buffer) ,最终才会写入到高速缓存和内存里。
在乱序执行的情况下,只有 CPU 内部指令的执行层面,只要我们能在指令的译码阶段正确地分析出指令之间的数据依赖关系,这个“乱序”就只会在互相没有影响的指令之间发生。指令的计算结果写入到寄存器和内存之前,依然会进行一次排序,以确保所有指令在外部看来仍然是有序完成的。
6、控制冒险
实现背景:增加资源、流水线停顿、操作数前推、乱序执行,这些解决各种“冒险”的技术方案,所有的流水线停顿操作都要从指令执行阶段开始。取指令和指令译码不会需要遇到任何停顿,这是基于一个假设。这个假设就是,所有的指令代码都是顺序加载执行的。不过这个假设,在执行的代码中,一旦遇到 if…else 这样的条件分支,或者 for/while 循环,就会不成立。

条件跳转指令的本质:在 jmp 指令发生的时候,CPU 可能会跳转去执行其他指令。jmp 后的那一条指令是否应该顺序加载执行,在流水线里面进行取指令的时候,没法知道。要等 jmp 指令执行完成,去更新了 PC 寄存器之后,才能知道,是否执行下一条指令,还是跳转到另外一个内存地址,去取别的指令。跳转指令的比较结果,仍然要在指令执行的时候才能知道。在流水线里,第一条指令进行指令译码的时钟周期里,其实就要去取下一条指令了。这个时候,其实还没有开始指令执行阶段,自然也就不知道比较的结果。
分支预测:
就是让 CPU 来猜一猜,条件跳转后执行的指令,应该是哪一条。
(1)假装分支不发生,仍然按照顺序,把指令往下执行。分支预测失败,就把后面已经取出指令已经执行的部分,给丢弃掉。这个丢弃的操作,在流水线里面,叫作 Zap 或者 Flush。
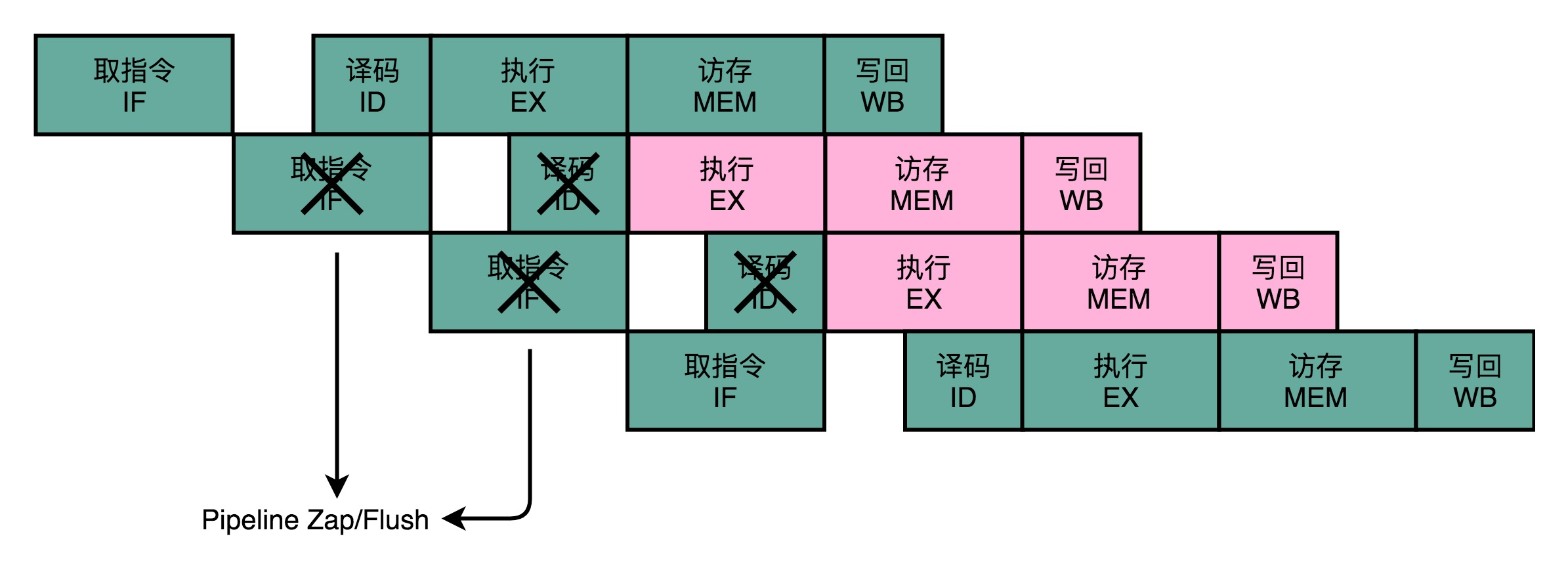
(2)动态分支预测
一级分支预测:用一个比特,去记录当前分支的比较情况,直接用当前分支的比较情况,来预测下一次分支时候的比较情况。
状态机:2 个比特来记录对应的状态。这样这整个策略,就可以叫作 2 比特饱和计数,或者叫双模态预测器(Bimodal Predictor),就是根据前面两条挨着的分支判断下面一条分支。
7、嵌套循环影响性能的实例
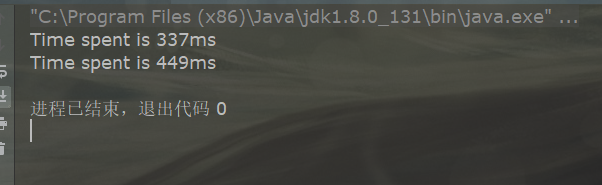
public class BranchPrediction { public static void main(String args[]) { long start = System.currentTimeMillis(); for (int i = 0; i < 100; i++) { for (int j = 0; j <1000; j ++) { for (int k = 0; k < 10000; k++) { } } } long end = System.currentTimeMillis(); System.out.println("Time spent is " + (end - start)+ "ms"); start = System.currentTimeMillis(); for (int i = 0; i < 10000; i++) { for (int j = 0; j <1000; j ++) { for (int k = 0; k < 100; k++) { } } } end = System.currentTimeMillis(); System.out.println("Time spent is " + (end - start) + "ms"); } }
分析:
这个差异就来自分支预测。循环其实也是利用 cmp 和 jle 这样先比较后跳转的指令来实现的。每一次循环都有一个 cmp 和 jle 指令。每一个 jle 就意味着,要比较条件码寄存器的状态,决定是顺序执行代码,还是要跳转到另外一个地址。也就是说,在每一次循环发生的时候,都会有一次“分支”。
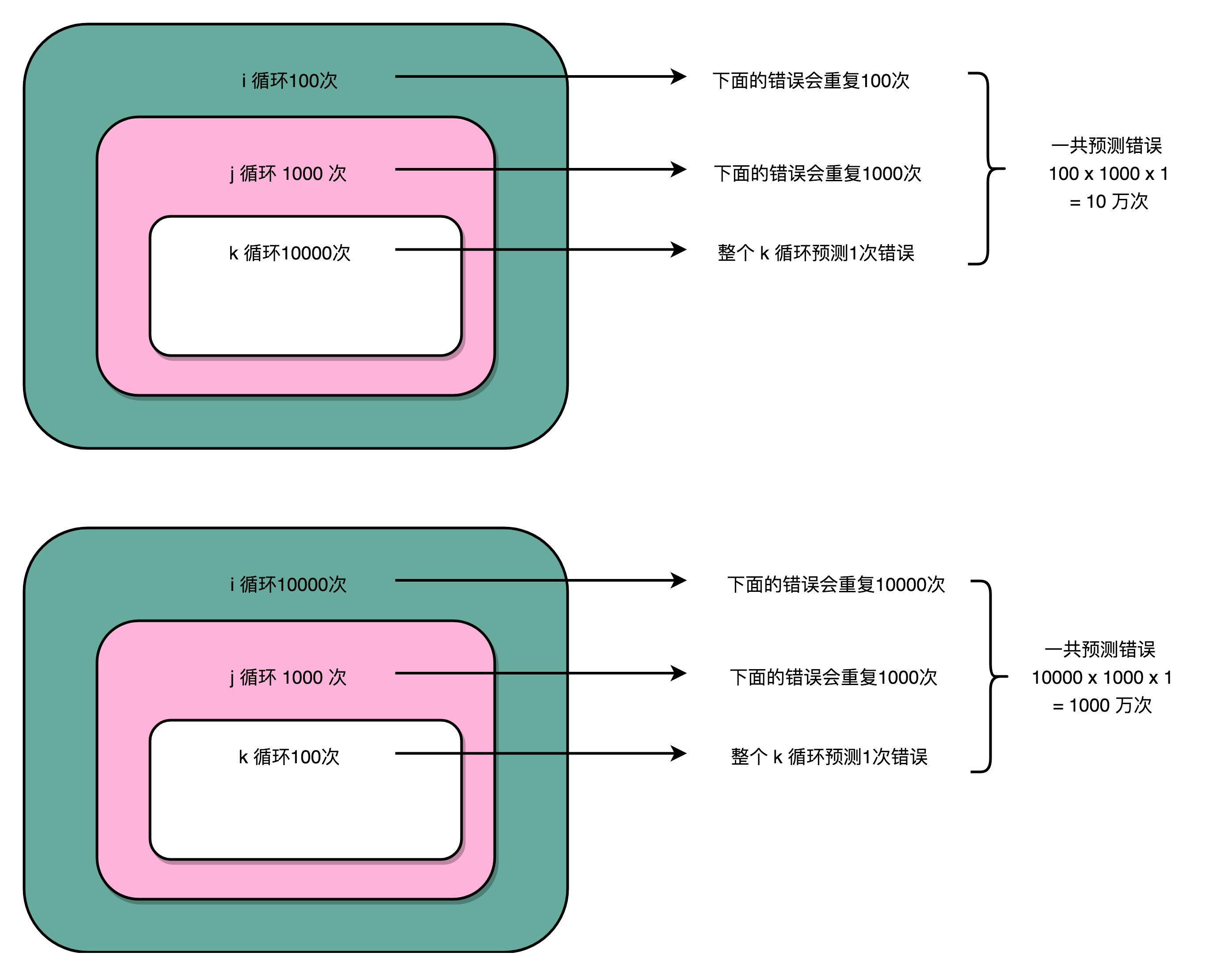
分支预测策略最简单的一个方式,自然是“假定分支不发生”。对应到上面的循环代码,就是循环始终会进行下去。在这样的情况下,上面的第一段循环,也就是内层 k 循环 10000 次的代码。每隔 10000 次,才会发生一次预测上的错误。而这样的错误,在第二层 j 的循环发生的次数,是 1000 次。
最外层的 i 的循环是 100 次。每个外层循环一次里面,都会发生 1000 次最内层 k 的循环的预测错误,所以一共会发生 100 × 1000 = 10 万次预测错误。
上面的第二段循环,也就是内存 k 的循环 100 次的代码,则是每 100 次循环,就会发生一次预测错误。这样的错误,在第二层 j 的循环发生的次数,还是 1000 次。最外层 i 的循环是 10000 次,所以一共会发生 1000 × 10000 = 1000 万次预测错误。
第一段代码发生“分支预测”错误的情况比较少,更多的计算机指令,在流水线里顺序运行下去了,而不需要把运行到一半的指令丢弃掉,再去重新加载新的指令执行。
