题意:
给出 N (1 ~ 1000),K (0 ~ 1000000000)代表有 N 个科目的成绩,每个科目成绩都有 a,b 两种成绩,后给出 N 个 a 和 N 个 b 的成绩。现要使 y = 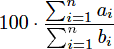 达到最大,当去除 K 个科目的成绩之后,y 最大能取到多大。
达到最大,当去除 K 个科目的成绩之后,y 最大能取到多大。
思路:
二分搜索。y = ,所以
100 * sigema(a) - y * sigema(b)
= 100 * (a1 + a2 + …… an) - y * (b1 + b2 + …… bn)
= (100 * a1 - y * b1)+ (100 * a2 - y * b2 ) + …… +(100 * an - y * bn)
= 0 ;
故枚举 y 后,先求出每个科目对应的 (100 * ai - y * bi) 值,后由大到小排序,取前面的 n - k 个。
若求和后的值 > 0,说明 y 小了,应该往右边搜,l = mid;
若求和后的值 < 0,说明 y 大了,应该往左边搜,r = mid;
若求和后的值 == 0,说明 y 的值刚刚好,但是可能还有更大的值出现,应该寻找最后一个满足条件的,所以应该往右边搜,l = mid。所以区间应该为左闭右开。
为什么要从大到小排序?
若从小到大排序的话,求和的结果 < 0 将会占大多数,那么二分搜索就不会不断往左边搜,使这个平均值越来越小,而题目要求的是求最大值。那么应该要让求和结果 > 0 占大多数,那么应该由大到小排序才对。
#include<iostream>
#include<algorithm>
using namespace std;
//const int maxn=1010;
const double eps=1e-10;
int n,k;
double sum;
struct node
{
double w,v;
double avg;
}nodee[1100];
bool cmp(node a,node b)
{
return a.avg<b.avg;
}
int main()
{
while(scanf("%d%d",&n,&k)!=EOF)
{
if(n==0&&k==0)break;
for(int i=0;i<n;i++)
{
scanf("%lf",&nodee[i].v);
}
for(int i=0;i<n;i++)
{
scanf("%lf",&nodee[i].w);
}
double ll=0.0;
double rr=100.0;
while(rr-ll>eps){
double mid=(ll+rr)/2;
for(int i=0;i<n;i++)
{
nodee[i].avg=100*nodee[i].v-mid*nodee[i].w;
}
sort(nodee,nodee+n,cmp);
sum=0;
for(int i=k;i<n;i++)
{
sum+=nodee[i].avg;
}
if(sum>0)ll=mid;
else rr=mid;
}
printf("%.0f
",ll);
}
return 0;
}