//很简单的一个案例,获取idx,根据idx得到P, 运算得到临时变量pos,把pos写入P
1 int idx = get_global_id(0); 2 if (idx >= P_length) 3 return; 4 float3 pos = vload3(idx, P); 5 pos.y += amplitude * sin( length(pos) / period + phase ); 6 vstore3(pos, idx, P);
可以得到涟漪的效果
// Houdini 16.5 Masterclass - OpenCL vs VEX 中的一个案例,实现对Volume 进行blur


1 kernel void kernelName( 2 int height_stride_x, 3 int height_stride_y, 4 int height_stride_z, 5 int height_stride_offset, 6 int height_res_x, 7 int height_res_y, 8 int height_res_z, 9 global float * height, 10 global float * __scratch 11 #ifdef HAS_mask 12 , global float * mask 13 #endif 14 ) 15 { 16 int gidx = get_global_id(0); 17 int gidy = get_global_id(1); 18 int gidz = get_global_id(2); 19 int idx = height_stride_offset + height_stride_x * gidx 20 + height_stride_y * gidy 21 + height_stride_z * gidz; 22 23 #ifdef HAS_mask 24 if (mask[idx] < 0.5) 25 { 26 __scratch[idx] = height[idx]; 27 return; 28 } 29 #endif 30 float total = 0; 31 for (int dx = -1; dx <= 1; dx++) 32 { 33 for (int dy = -1; dy <= 1; dy++) 34 { 35 for (int dz = -1; dz <= 1; dz++) 36 { 37 int srcidx = height_stride_offset 38 + height_stride_x * clamp(gidx+dx, 0, height_res_x-1) 39 + height_stride_y * clamp(gidy+dy, 0, height_res_y-1) 40 + height_stride_z * clamp(gidz+dz, 0, height_res_z-1); 41 float src_height = height[srcidx]; 42 43 total += src_height; 44 } 45 } 46 } 47 48 __scratch[idx] = total/27; 49 } 50 51 kernel void writeBack( 52 int height_stride_x, 53 int height_stride_y, 54 int height_stride_z, 55 int height_stride_offset, 56 int height_res_x, 57 int height_res_y, 58 int height_res_z, 59 global float * height, 60 global float * __scratch 61 #ifdef HAS_mask 62 , global float * mask 63 #endif 64 ) 65 { 66 int gidx = get_global_id(0); 67 int gidy = get_global_id(1); 68 int gidz = get_global_id(2); 69 int idx = height_stride_offset + height_stride_x * gidx 70 + height_stride_y * gidy 71 + height_stride_z * gidz; 72 height[idx] = __scratch[idx]; 73 }
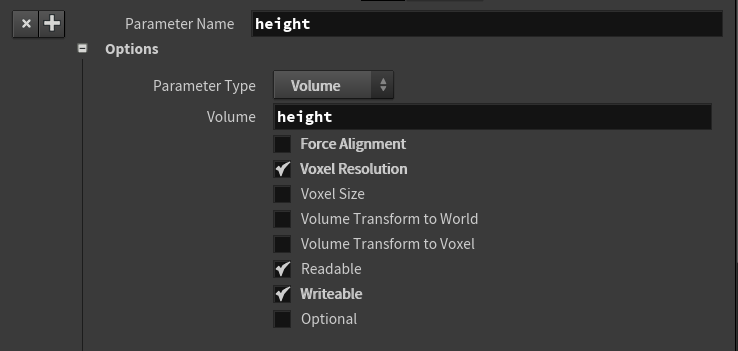
height 参数设置时 ,取消勾选了Force Alignment(Force Alignment 是为了简化代码,当有多个Volume的时候,认为Resolution和Transform相同),这样在kernal代码中,多了height_stride和height_res为前缀的参数。
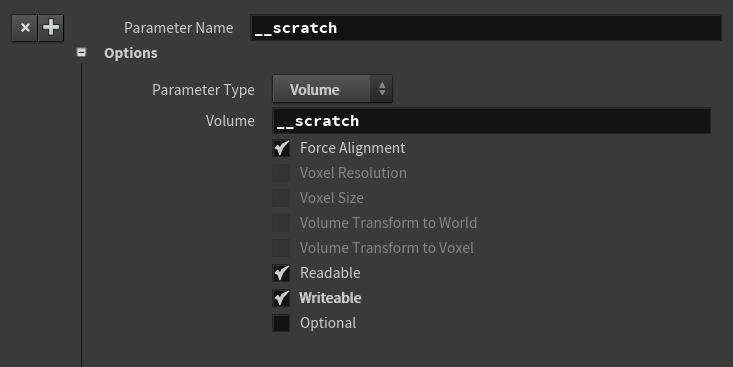
__scratch 是对height场的拷贝,勾选Force Alignment是因为,Resolution、Voxel Size 以及Transform什么都一样, height场的idx , 就是我们要对__scratch场操作的idx 。
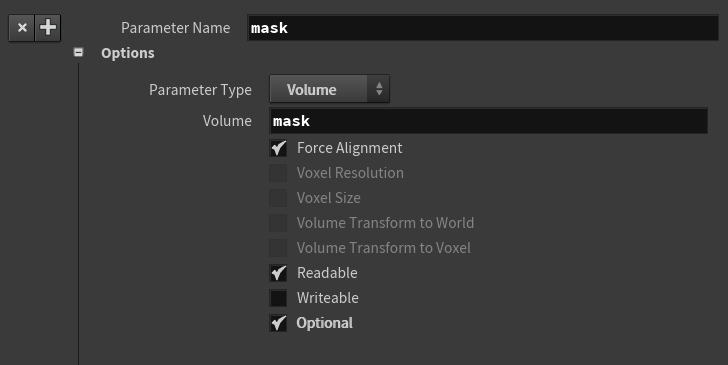
mask 勾选Force Alignment的原因也同上,完全可以根据height场的idx,得到mask场的idx。需要注意的是,mask勾选了Optional参数,这样代码中,在 #ifdef HAS_mask 和 #endif 中间的语句,只有在有mask场的时候才会执行,否则跳过
// OpenCL对数据的格式要求比较严格
比如像这样的语句: float d = abs( x0 ) + abs(y0) + abs(z0) - 1 。 前面的语句中x0,y0,z0都是float型,按理说 声明了float 型d,d得到的结果应该是float型,但是由于等式右边 1 是整形,最终导致d得到的结果是整形。这个在16.5中存在这样的问题,不知道以后会不会修复。
上面的语句正确的写法应该是: float d = abs( x0 ) + abs(y0) + abs(z0) - 1.0
// Houdini 16.5 Masterclass - OpenCL vs VEX 中的一个案例,作用是改变Volume内点的颜色
1 kernel void kernelName( 2 int P_length, 3 global float * P , 4 int Cd_length, 5 global float * Cd , 6 int density_stride_x, 7 int density_stride_y, 8 int density_stride_z, 9 int density_stride_offset, 10 int density_res_x, 11 int density_res_y, 12 int density_res_z, 13 float16 density_xformtovoxel, 14 global float * density 15 ) 16 { 17 int idx = get_global_id(0); 18 if (idx >= Cd_length) 19 return; 20 21 float3 pos = vload3(idx, P); 22 23 float4 voxelpos = pos.x * density_xformtovoxel.lo.lo + 24 pos.y * density_xformtovoxel.lo.hi + 25 pos.z * density_xformtovoxel.hi.lo + 26 density_xformtovoxel.hi.hi; 27 int3 voxelidx; 28 voxelidx.x = clamp((int)(floor(voxelpos.x)), 0, density_res_x-1); 29 voxelidx.y = clamp((int)(floor(voxelpos.y)), 0, density_res_y-1); 30 voxelidx.z = clamp((int)(floor(voxelpos.z)), 0, density_res_z-1); 31 32 float3 c = 1; 33 34 float d = density[density_stride_offset + 35 density_stride_x * voxelidx.x + 36 density_stride_y * voxelidx.y + 37 density_stride_z * voxelidx.z]; 38 if (d > 0.5) 39 c.y = 0; 40 41 vstore3(c, idx, Cd); 42 }

需要注意的地方:
1 Volume Transform to Voxel
勾选这个参数后,在Kernel中会传递一个16位矩阵,本例中即 density_xformtovoxel
2 矩阵的乘法
float4 voxelpos = pos.x * density_xformtovoxel.lo.lo + pos.y * density_xformtovoxel.lo.hi + pos.z * density_xformtovoxel.hi.lo + density_xformtovoxel.hi.hi;
为了得到 voxelpos, 我们用当前点的位置pos 乘以16位矩阵density_formtovoel . pos是一个1x3的矩阵,但在此计算中相当于把他看成 [pos.x,pos.y,pos.z,1] 即1x4的矩阵,乘以4x4的矩阵,这样的矩阵有好几种运算方式,这里采用一种分解的简单方式如下图。density_xformtovoxel.lo 取得前面一半(8位),density_xformtovoxel.hi取后面一半,density_xformtovoxel.lo.lo取前面的一半的一半(即矩阵的第一行),同理density_xformtovoxel.lo.hi 第二行,density_xformtovoxel.hi.lo第三行,density_xformtovoxel.hi.hi 第四行。
density_xformtovoxel.lo.lo
density_xformtovoxel = [ density_xformtovoxel.lo.hi ]
density_xformtovoxel.hi.lo
density_xformtovoxel.hi.hi
[ pos.x, pos.y, pos.z, 1] x density_xformtovoxel 根据矩阵的分块乘法规则可以写成:
pos.x * density_xformtovoxel.lo.lo +
pos.y * density_xformtovoxel.lo.hi +
pos.z * density_xformtovoxel.hi.lo +
density_xformtovoxel.hi.hi;
3 voxelpos
voxelpos 得到的是浮点值, clamp 后
1 voxelidx.x = clamp((int)(floor(voxelpos.x)), 0, density_res_x-1); 2 voxelidx.y = clamp((int)(floor(voxelpos.y)), 0, density_res_y-1); 3 voxelidx.z = clamp((int)(floor(voxelpos.z)), 0, density_res_z-1);
我们就可以可到voxel的位置,本例中,Volume分辨率如下
![]()
voxelidx.x 取值范围 0- 99
voxelidx.y 取值范围 0-94
voxelidx.z 取值范围 0-109
4 density_stride_x, density_stride_y, density_stride_z
为了理解这三个参数,我在写入Cd的值前加入三行代码:
c.x = density_stride_x; c.y = density_stride_y; c.z = density_stride_z;
![]()
Volume的分辨率是 [100,95,110] , 可以看出:
9894 = (95+2 ) * (100 + 2)
102 = (100 +2)
这是因为当Opencl 拿到我们的volume时, 为了防止访问volume的数据时超出边界,会每个方向增加一个voxel作为padding(比如对于X方向,+X轴的最外面和-X轴的最外面各增加一个voxel)。
举例比如:一个 5X5X3矩阵,当opencl 拿到时,会把它变成7X7X5矩阵,(左边是原始的volume, 右边是处理过的)

因此!!!!!!!!!!!!!!
如果我们原始的volume分辨率是 [100,95,110]
density_stride_x : x 方向单位增量 是 1 (这个前后不变,加1即可访问到+X方向的下一个voxel)
density_stride_y : y 方向单位增量是 100 + 2 ( 加 102 才能访问到 +Y方向的下一个voxel)
density_stride_z :z 方向单位增量 (95+2 ) * (100 + 2) (加9894 才能访问到 +Z方向的下一个voxel)