文章来源:栈大小和内存分布问题
栈大小是有默认值的,如果申请的临时变量太大的话就会超过栈大小,造成栈溢出。
编译期限制栈大小,和系统限制栈深度根本是两回事。系统限制栈深是限制进程主线程的栈深,限制的是整个函数调用链的最大栈深,这个栈深是函数调用链上各个函数栈帧大小之和。编译期限制栈大小是限制单个函数栈帧的大小。
一、修改栈大小
栈的大小可以修改的。在应用程序我们经常需要定义大的数组,数组定义成局部变量非静态变量,那么数组就会在栈上分配,当数组超过默认栈的大小时,会引起非常内存访问。那么如何修改系统默认的栈的大小呢。
一般,在Unix-like平台,栈的大小不是由程序自己来控制的而是由环境变量来控制的,所以就不能通过设置编译器(像gcc)的任何编译标志来设置栈的大小;在windows平台下,栈的大小的信息是包含在可执行文件中的。它可以在Visual C++的编译过程中设置,但是在gcc中是不可行的。
方法为
项目->属性->链接器->系统->堆栈保留大小
注:这里填的是字节数
在一般情况下, 不同平台默认栈大小如下(仅供参考)
SunOS/Solaris 8172K bytes (Shared Version)
Linux 10240K bytes
Windows 1024K bytes (Release Version)
AIX 65536K bytes
如果定义大数组的情况下,那就需要修改默认的栈大小,下面给出几个平台的修改方法:
1.SunOS/Solaris系统:
limit # 显示当前用户的栈大小
unlimit # 将当前用户的栈大小改为不限制大小
setenv STACKSIZE 32768 #设置当前用户的栈大小为 32M bytes
2.Linux系统:
ulimit -a #显示当前用户的栈大小
ulimit -s 32768 #将当前用户的栈大小设置为32M bytes
- Windows (在编译过程中的设置):
1). 选择 "Project->Setting".
2). 选择 "Link".
-
选择 "Category"中的 "Output".
-
在 "Stack allocations"中的"Reserve:"中输栈的大小,例如: 32768
在 Visual Studio 开发环境中设置此链接器选项
打开此项目的“属性页”对话框。有关详细信息,请参见设置 Visual C++ 项目属性。
单击“链接器”文件夹。
单击“系统”属性页。
修改下列任一属性:
堆栈提交大小
堆栈保留大小
问题解答:
方法一:STACKSIZE 定义.def文件
语法:STACKSIZE reserve[,commit]
reserve:栈的大小;commit:可选项,与操作系统有关,在NT上只一次分配物理内存的大小
方法二:设定/STACK
VC6.0修改:
打开工程,依次操作菜单如下:Project->Setting->Link,在Category 中选中Output,然后
在Reserve中设定堆栈的最大值和commit。
注意:reserve默认值为1MB,最小值为4Byte;commit是保留在虚拟内存的页文件里面,它设置的较
大会使栈开辟较大的值,可能增加内存的开销和启动时间
二、堆大小
堆大小是可以自己申请的,只要不超过内存都是可以的。
对于堆来讲,频繁的malloc/free(new/delete)势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低(虽然程序在退出后操作系统会对内存进行回收管理)。对于栈来讲,则不会存在这个问题。
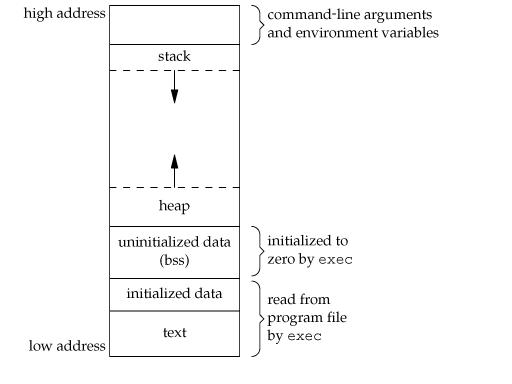
三、C程序内存分配
C程序一般分为
1.程序段:程序段为程序代码在内存中的映射.一个程序可以在内存中多有个副本.
2.初始化过的数据:在程序运行值初已经对变量进行初始化的
3.未初始化过的数据:在程序运行初未对变量进行初始化的数据
4.栈(stack):存储局部,临时变量,在程序块开始时自动分配内存,结束时自动释放内存.存储函数的返回指针.
5.堆(heap):存储动态内存分配,需要程序员手工分配,手工释放.
6.文字常量区—常量字符串就是放在这里的。程序结束后由系统释放
附程序分布图:
[转载]c程序内存分布
这是一个前辈写的,非常详细
//main.cpp
int a=0; //全局初始化区
char *p1; //全局未初始化区
main()
{
int b;栈
char s[]="abc"; //栈
char p2; //栈
char p3="123456"; //123456�在常量区,p3在栈上。
static int c=0; //全局(静态)初始化区
p1 = (char)malloc(10);
p2 = (char)malloc(20); //分配得来得10和20字节的区域就在堆区。
strcpy(p1,"123456"); //123456�放在常量区,编译器可能会将它与p3所向"123456"优化成一个地方。
}
3.1 申请效率的比较:
栈:由系统自动分配,速度较快。但程序员是无法控制的。
堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用Virtual Alloc分配内存,他不是在堆,也不是在栈,而是直接在进
程的地址空间中保留一块内存,虽然用起来最不方便。但是速度快,也最灵活。
3.2 堆和栈中的存储内容
栈:在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的
地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变
量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主
函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容由程序员安排。
3.3 存取效率的比较
char s1[]="aaaaaaaaaaaaaaa";
char *s2="bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。