PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(min) | 实际耗时(min) |
|---|---|---|---|
| Planning | 计划 | 15 | 30 |
| Estimate | 估计这个任务需要多少时间 | 900 | 1200 |
| Development | 开发 | 810 | 1100 |
| Analysis | 需求分析 (包括学习新技术) | 100 | 100 |
| Design Spec | 生成设计文档 | 80 | 50 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范 (为开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 100 | 120 |
| Coding | 具体编码 | 400 | 600 |
| Code Review | 代码复审 | 50 | 50 |
| Test | 测试 (自我测试,修改,提交修改) | 50 | 150 |
| Reporting | 报告 | 90 | 100 |
| Test Report | 测试报告 | 50 | 60 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结 并提出过程改进计划 | 30 | 30 |
| 合计 | 915 | 1230 |
计算模块接口的设计与实现过程
解题步骤and心路历程
-
先对输入的字符串进行简单的处理,提取出难度等级、姓名、手机号和总的地址串
刚看到题目的时候全懵了,这个字符串要这么切分啊,完全不懂。然后我舍友跟我说可以用python的第三方库——jieba库,然后我试了一下,发现真的可以,这个库也太强了吧。然后有看到题目要求,python只能提交一个python文件,可能会用不了第三方库,然后我就放弃了使用jieba库的想法,老老实实的转向正则表达。以前完全没有用过正则表达式,这次临时去学的,最后发现python的正则表达式还是挺好理解的,很快就能切分出想要的。 -
拿到总的地址串之后在开始逐级细分,按照省、市、县、镇、路、门派号、详细地址的顺序一级一级进行分割。省市县镇是通过和全国的地图数据匹配得到,路、门牌号、详细地址则是通过正则表达式切分得到。
写地址切片真的是一波三折,推到重来了好几次。 第一个想法是用高德地图的api来做,代码量是真的少,只需要一个get请求,就自动帮你完成地址解析并返回一个json对象,但是写完之后发现,高德api的精度完全不行,只能到县级,之后的镇、路、门牌号这些都没办法给出,第一个想法宣告失败。 第二次的想法是全部用正则表达式去一级一级切分,然后看了看题目要求,瞬间就放弃了,第二个想法也宣告失败。 第三次的想法(准确来说,这并不是我自己的想法),同学发给了我一个有全国地图信息的json文件(省市县镇四级地址),并告诉我可以用匹配的办法来写,然后我就开始尝试,一级一级的切分,然后后地图信息进行匹配,最终达到了自己想要的目标。(这个过程也十分艰难,进了好多坑,还有一个逻辑错误,再次推到重来了一次) -
将结果保存为json格式
通过测试程序的那一瞬间,我是真正理解了什么是痛并快乐着。从真正开始写代码到完成,花了4天左右时间。凌晨四点的福大不用等到后面的团队作业,第一次作业就能见识到了,真的累。在这里由衷感谢陈秋琴、张庆焰、许煌标三位同学,没有他们的激励和帮助,我肯定没办法完成我的作业,4天过程中,好多次想要半途而废想要放弃,但是最后并没有,是他们给了我一次次推到重来的信心和勇气。
各个函数具体如下:
| 函数名 | 说明 |
|---|---|
| def main() | 主函数,并进行初步的分割,得到姓名、手机和地址串 |
| def cutsame() | 在地址串中切掉已经匹配好的部分 |
| def mapmatch_5() | 完成5级地址的匹配分割 |
| def mapmatch_7() | 完成7级地址的匹配分割 |
| def select(flag) | 通过前缀判断是进行5级分割还是7级分割 |
流程图:
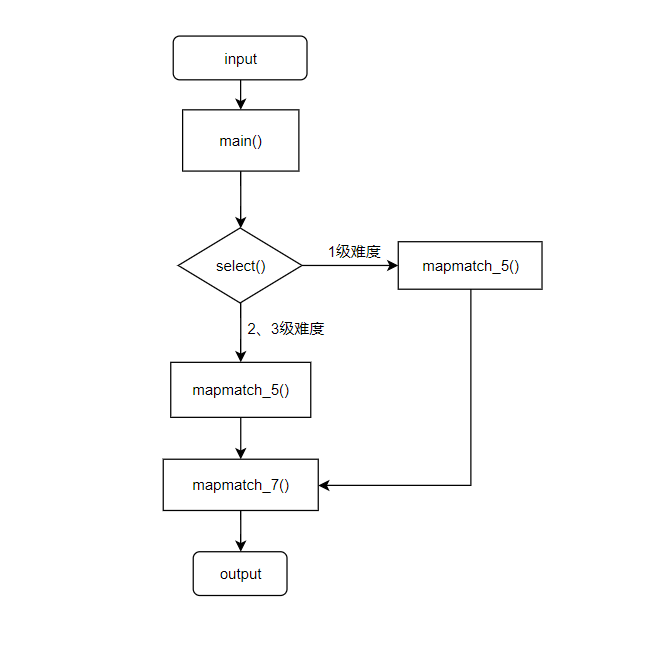
整个流程的实现到不是很难,只是有各种各样需要跳过去的小坑。核心思想是采用逐级分割。前4级(省、市、县、镇)采用匹配得到,最后3级(路、门牌号、详细地址)由正则切分得到。
例子展示如下:
"2!李四,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层."
步骤:
(1)input()
初步分割为:
难度等级:2
姓名:李四
手机:13756899511
总地址串:福建省福州市鼓楼区鼓西街道湖滨路110号湖滨大厦一层
(2)之后再由难度等级2判断出要进行7级分割
省:福建省 地址串:福州市鼓楼区鼓西街道湖滨路110号湖滨大厦一层(匹配)
↓
市:福州市 地址串:鼓楼区鼓西街道湖滨路110号湖滨大厦一层(匹配)
↓
县:鼓楼区 地址串:鼓西街道湖滨路110号湖滨大厦一层(匹配)
↓
镇:鼓西街道 地址串:湖滨路110号湖滨大厦一层(匹配)
↓
路:湖滨路 地址串:110号湖滨大厦一层(正则)
↓
门牌号:110号 地址串:湖滨大厦一层(正则)
↓
详细地址:湖滨大厦一层(正则)
(3)最后转化为json对象
print(json)
计算模块接口部分的性能改进
性能分析如下图所示:
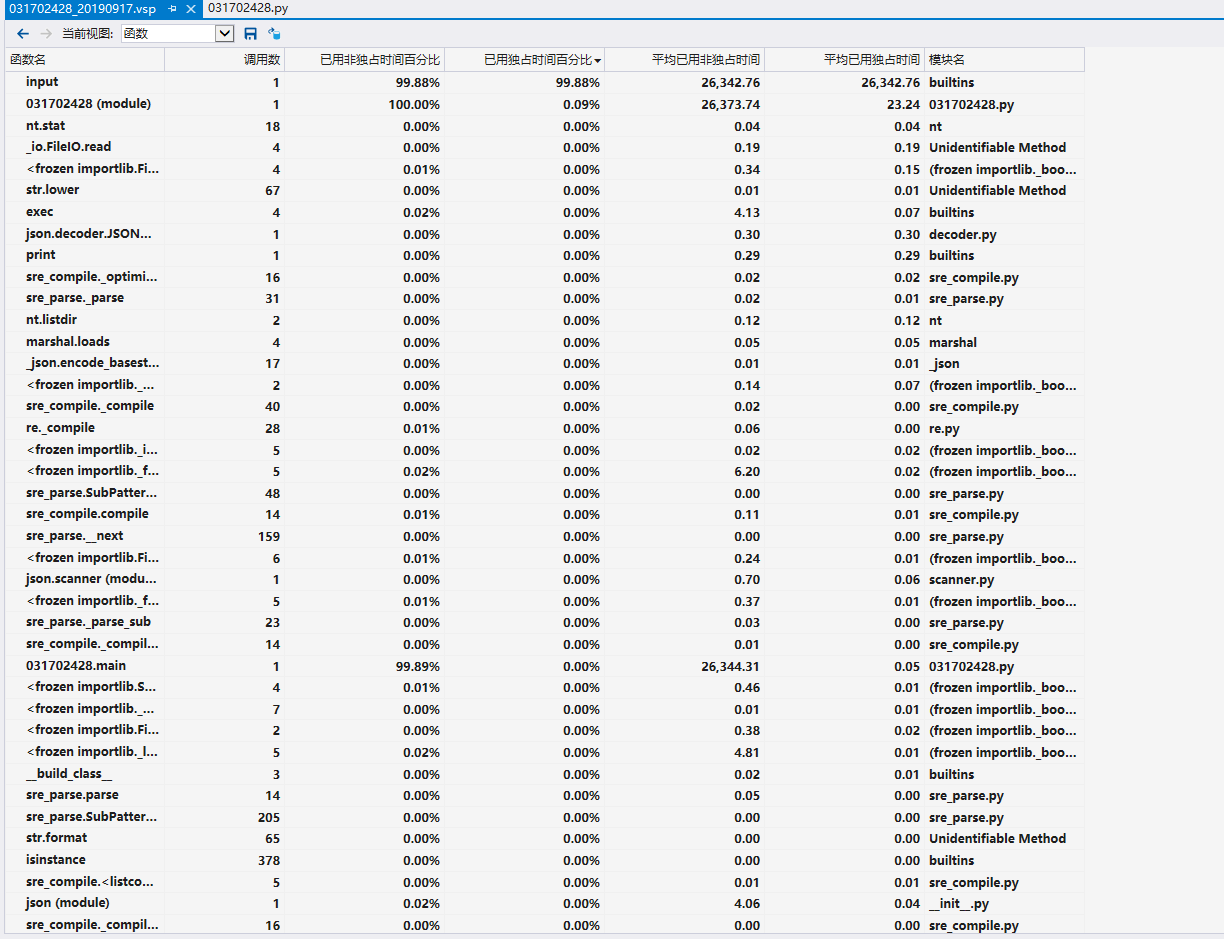
性能分析真的把我给整懵了,可能是由于我把整个中国地图的json都复制到了我的源代码里面(要求只能有一个py文件),我的代码行数达到了19W行,导致真的有利用到的代码量很少,占比很少,然后得出了这个分析结果。(我什么也看不懂,也不知道该怎么改进)
占比最高的函数是 input()
覆盖率如下图所示:

计算模块部分单元测试展示
2!李四,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.
{"姓名": "李四", "手机": "13756899511", "地址": ["福建省", "福州市", "鼓楼区", "鼓西街道", "湖滨路", "110号", "湖滨大厦一层"]}
1!张三,福建福州闽13599622362侯县上街镇福州大学10#111.
{"姓名": "张三", "手机": "13599622362", "地址": ["福建省", "福州市", "闽侯县", "上街镇", "福州大学10#111"]}
2!王五,福建省福州市鼓楼18960221533区五一北路123号福州鼓楼医院.
{"姓名": "王五", "手机": "18960221533", "地址": ["福建省", "福州市", "鼓楼区", "", "五一北路", "123号", "福州鼓楼医院"]}
3!小美,北京市东15822153326城区交道口东大街1号北京市东城区人民法院.
{"姓名": "小美", "手机": "15822153326", "地址": ["北京", "北京市", "东城区", "交道口街道", "东大街", "1号", "北京市东城区人民法院"]}
1!小陈,广东省东莞市凤岗13965231525镇凤平路13号.
{"姓名": "小陈", "手机": "13965231525", "地址": ["广东省", "东莞市", "", "凤岗镇", "凤平路13号"]}
1!韶划奸,上海市普陀15717060981区长风新村街道光复西路1995号中山北路6-17号海鑫公寓.
{"姓名": "韶划奸", "手机": "15717060981", "地址": ["上海", "上海市", "普陀区", "长风新村街道", "光复西路1995号中山北路6-17号海鑫公寓"]}
1!钭洋,福建龙岩新罗区岩山镇岩山供销社黄固村农资农家店13135601243.
{"姓名": "钭洋", "手机": "13135601243", "地址": ["福建省", "龙岩市", "新罗区", "岩山镇", "岩山供销社黄固村农资农家店"]}
2!楚涡握,湖北随州市随县吴山镇唐王街联宏村委18883549874会.
{"姓名": "楚涡握", "手机": "18883549874", "地址": ["湖北省", "随州市", "随县", "吴山镇", "唐王街", "", "联宏村委会"]}
计算模块部分异常处理说明
#县
#县级有可能会有确实,需要特殊处理
#在遍历县级地址时,若发现未找到,则flag会为0
#并使data["县"] = ""(空串)
match = address_str[:2]
#print(address_str)
flag = 0 #flag是异常处理的关键所在
for item in itemm["children"]:
if(re.search(match,item["name"])):
itemm = item #如果县级缺失,就不会有这个
flag = 1
break
if(flag == 1):
data["县"] = itemm["name"]
else:
data["县"] = ""
address_str = cutsame(itemm["name"],address_str)
#镇
#当flag==0使,则表示在上一级未找到县级地址
#因此要匹配到镇级地址,就必须遍历整个市区内的所有镇
#用一个双层for循环实现
match = address_str[:2]
itemmm = {"name":""}
#print(address_str)
if(flag == 1):
for item in itemm["children"]:
if(re.search(match,item["name"])):
itemmm = item
break
else:
for item in itemm["children"]:
for item2 in item["children"]: #双循环遍历
if(re.search(match,item2["name"])):
itemmm = item2
break
data["镇"] = itemmm["name"]
address_str = cutsame(itemmm["name"],address_str)
#正则切片的时候也会有缺失
#但是用一个if判断就可以完美解决
#因为如果未找到目标,会返回一个none对象,可以作为if判断的条件
def mapmatch_7():
address_str = data["详细地址_5"]
#街道
c = re.compile(r'.+(路|街|巷|桥|道){1}')
match_1 = c.search(address_str)
#print(match.group(0))
if(match_1):
data["街道"] = match_1.group(0)
else: #如果为none,则赋值为空串 核心
data["街道"] = ""
address_str = cutsame(data["街道"],address_str)
#print(data["街道"])
#print(address_str)
#门牌号
cc = re.compile(r'.+(号){1}')
match_2 = cc.search(address_str)
#print(match.group(0))
if(match_2):
data["门牌号"] = match_2.group(0)
else: #如果为none,则赋值为空串 核心
data["门牌号"] = ""
address_str = cutsame(data["门牌号"],address_str)
#print(data["门牌号"])
#print(address_str)
data["详细地址_7"] = address_str
#遇到最大的坑应该就是这两个了,其他还有一些零零散散的小问题,比较容易解决
心得体会
心得体会已经写在了解题思路里边了。