作者:Erop Porob
翻译:墨香溪
文章来自Postgres Professional
在本文中,我将开始有关PostgreSQL内部结构的一系列课程(或者说系列集?—总的来说,这个想法很宏大)。
本文中的材料将基于Pavel pluzanov和我正在创建的有关PostgreSQL数据库管理的培训课程(俄语)。并非每个人都喜欢看视频(比如我)或者看幻灯片,即使有注释,也不是很理想。
可惜的是,目前唯一可用的英语课程是2天入门 PostgreSQL 11。
当然,文章与课程内容将不会完全相同。我将只讨论PostgreSQL的基本原理与构成,而忽略数据库管理的内容,但是我将尝试更详细,更深层次的阐述PostgreSQL 的原理。我相信这样的知识对应用程序开发人员和管理员都是有用的。
本文将针对那些已经拥有使用PostgreSQL经验并且至少大致了解PosgresSQL 是什么的人。因为对于初学者来说,本系列会太难了(比较难)。例如,我不会讨论任何有关如何安装PostgreSQL和运行psql的。
所涉及的内容因版本而异,但是我将使用当前的 PostgreSQL 11 的最初版本。
第一个系列的文章将阐述事务隔离和多版本并发控制(MVCC)相关的问题,本系列的计划如下:
1.理解在标准和PostgreSQL 中的事务隔离的实现(本文)。
2.派生文件,文件,页 – 在物理文件级别的变化
3.行的版本,虚拟事务和子事务
4.数据快照和行版本的可见性;事件范围。
5.页内vacuum和HOT更新
6.正常 Vacuum
7.AutoVacuum
8.事务ID 回卷以及 事务冻结。
以下正式开始!
在开始之前,我要感谢Elena Indrupskaya将文章翻译成英文。
注:此系列文章由英文译为中文。
什么是事务隔离,为何如此重要?
可能每个人多多少少都知道事务的存在,知道ACID的缩写,并且听说过隔离级别。但是我们仍然会碰到这样一种观点:事务隔离只与理论有关,在实践中是不必要的。因此,我将花一些篇幅来解释为什么这确实很重要。
我想你应该不会乐于看到应用程序从数据库中获取了不正确的数据,或者应用程序将错误的数据写入了数据库。
但是什么是“正确”的数据?众所周知,可以在数据库级别创建完整性约束,例如NOT NULL或UNIQUE。如果数据始终需要满足完整性约束(之所以如此,是因为DBMS(即数据库管理系统)可以确保),则它们是不可或缺的。
正确和完整是可以等同的吗?不完全是。并非所有约束都可以在数据库级别上指定。有些约束过于复杂,例如,一次操作中含有多个表。即使通常可以在数据库中定义约束,但由于某种原因,它没有定义,但这并不意味着可以违反约束。
因此,正确性要比完整性强,但是我们并不确切的知道这意味着什么。我们只不过承认正确性的“黄金标准”是一个应用程序,如我们希望的那样,是正确编写的,绝不会出错。在任何情况下,如果应用程序没有违反完整性,而是违反了正确性,则DBMS不会记录到这一情况,也不会当场捕获该错误。
在后面,我们将使用术语一致性来指代正确性。
但是,让我们假设应用程序仅按照正确的顺序执行操作。那如果应用程序正确无误,DBMS的作用是什么?
首先,事实证明,正确的操作顺序会暂时破坏数据一致性,这听起来很奇怪,也很合理。一个简单明了的例子是将资金从一个帐户转移到另一个帐户。一致性规则可能像这样:转账永远不会更改帐户上的总金额(此规则在SQL中很难指定为完整性约束,因此它存在于应用程序级别,并且对DBMS不可见)。转帐包括两个操作:第一个操作减少一个帐户上的资金,第二个操作-增加另一个帐户上的资金。第一个操作破坏数据一致性,而第二个操作恢复数据一致性。
一个好的实践是在完整性约束级别上实现上述规则。
如果执行第一个操作后第二个操作不执行该怎么办? 比如:在第二次操作过程中,可能会发生电力故障,服务器崩溃,除于0的情况-- 无论如何,很明显,一致性将被破坏,并且这是不允许的。通常,可以在应用程序级别解决此类问题,但需要付出大量努力;但幸运的是,我们大可不必这样做:这可以由DBMS完成。为此,DBMS必须知道这两个操作是不可分割的整体。也就是,事务。
事实证明很有趣: 因为DBMS知道操作是在一个事务里面,所以它通过确保事务的原子性来帮助保持一致性,而这样做却不用了解特定的一致性规则。
但是还有第二点,更微妙的一点。一旦几个同时发生的事务(分别绝对正确)出现在系统中,它们可能无法一起正常工作。这是因为操作顺序混合了:您不能假定一个事务的所有操作都先执行,然后又执行另一个事务的所有操作。
关于并发:实际上,事务可以在具有多核处理器,磁盘阵列等的系统上并发执行。但是,在分时共享模式下,按顺序执行命令的服务器也一样适用这个逻辑:在某个时钟周期内执行一个事务,在下个时钟周期,执行另外一个事务。有时,这种情况就被术语称作“并发执行”。
正确的事务无法正常工作的情况称为并发执行异常。
举一个简单的例子:如果一个应用程序想要从数据库中获取正确的数据,它至少不能看到其他未提交事务的变化。否则,您不仅可以获取不一致的数据,还可以查看数据库中从未存在过的内容(如果另外一个未提交的事务取消了事务)。这种异常称为脏读。
还有其他更复杂的异常,我们将在稍后讲到。
当然,避免并发执行是不可能的:否则,我们还谈什么性能? 但是您不能使用不正确的数据。
DBMS再次用来解决这类问题。让你可以使事务像顺序执行一样,好像一个接一个地执行。换句话说-彼此隔离。实际上,DBMS可以混合执行各种操作,但要确保并发执行的结果与某些可能的顺序执行的结果相同。这样可以消除任何可能的异常情况。因此,我们得出了以下定义:
事务是由应用程序执行的一组操作,这些操作将数据库从一个正确的状态转移到另一个正确的状态(一致性),倘若事务已完成(原子性)并且不受其他事务的干扰(隔离)。
此定义将首字母缩写ACID的前三个字母组合在一起。他们紧紧的结合在一起,以至于另外一个字母都变得没有意义。实际上,和字母D(耐久性)也难以分离。确实,当系统崩溃时,它仍具有未提交事务的更改,您需要使用这些更改来恢复数据一致性。
一切都会好起来的,但是实现完全隔离是一项技术难题,会降低系统吞吐量。因此,实际上,经常(不是总是,但几乎总是)使用弱隔离,这可以防止某些但不是全部异常。这意味着确保数据正确性的一部分工作落在应用程序上。因此,了解系统中使用的隔离级别,提供哪些保证,不提供什么以及在这种情况下如何编写正确的代码非常重要。
SQL标准中的隔离级别和异常
SQL标准很早就描述了四个隔离级别。通过列出在此级别同时执行事务时允许或不允许的异常来定义这些级别。因此,要谈论这些级别,有必要了解异常。
我强调,在这一部分中,我们谈论的是标准,也就是说,关于一种理论,实践基于该理论。但与此同时,实践却大相径庭。因此,以下示例都是基于推测,推测银行会对银行账户进行相同的操作。这是很好的例子。当然,尽管这和现实中银行的实际操作无关。
丢失更新
让我们从丢失更新开始。当两个事务读取表的同一行,然后一个事务更新该行,然后第二个事务也更新同一行而不考虑第一个事务所做的更改时,就会发生此异常。
例如,两次事务将使同一帐户上的金额增加100元(原文中使用卢布,翻译中使用人民币)第一个事务读取当前值 1000 ,然后第二个事务读取相同的值。第一笔事务增加金额(更新为 1100)并写入该值。第二个事务的行为方式相同:更新为1100并写入此值。结果,客户损失了100元。SQL标准不允许在任何隔离级别丢失更新。
脏读和读取未提交
脏读我们已经熟悉了。当一个事务读取另一个事务尚未提交的更改时,就会发生此异常。例如,第一笔事务将客户的帐户下的所有资金转移到另一个帐户,但不提交更改。另一笔事务读取了帐户余额,得到0。尽管第一笔事务中止并还原了其更改,还是了拒绝客户提取现金的请求,就算数据库中从来没有0的值。
SQL标准允许在“读取未提交”级别进行脏读。
不可重复读和已提交读取
不可重复读异常发生在当事务读取同个行两次的中间,第二个事务修改(或删除)了该行并提交更改。因此,第一个事务将获得不同的结果。
例如,一致性规则禁止客户帐户上出现负数。第一笔事务将使帐户中的金额减少100元。它检查当前值,得到1000元,并确定可以减小。同时,第二笔事务将帐户上的金额减少为零并提交更改。如果现在第一笔事务重新核对了金额,它将得到0(但是它已经决定减少该金额,帐户“出现异常”)。
SQL标准允许不可重复的读取处于“读取未提交(Read Uncimmitted)”和“读取已提交(Read Committed)”级别。但是Read Committed不允许脏读。
幻读和可重复读取
幻读发生在一个事务根据相同的条件读取多行数据的中间,第二个事务增加了符合第一个事务where条件的行并提交。那么第一个事务将获得不同的结果集。
例如,一致性规则禁止客户拥有3个以上的帐户。第一笔事务将开设一个新帐户,检查当前帐户数(例如2),并确定可以开设。同时,第二笔事务还将为客户开设一个新帐户并提交更改。现在,如果第一笔事务重新检查了该数字,它将得到3(但它已经在开设另一个帐户,这将导致客户拥有4个账户)。
SQL标准允许幻读处于“未提交读取(read Uncommitted)”,“已提交读取 (read Committed)”和“可重复读取(Repeatable)”级别。但是,在“可重复读取(Repeatable Read)”级别上不允许不可重复读取。
没有异常和可序列化
该标准定义了另一个级别-Serializable-不允许任何异常。这与禁止丢失更新以及脏的,不可重复读或幻读不同。
事实是,已知的异常比标准中列出的要多得多,并且未知数量也未知。
可序列化级别必须绝对防止所有异常。这意味着在此级别上,应用程序开发人员无需考虑并发执行。如果事务分别按照正确的顺序执行,则同时执行这些事务时,数据也将保持一致。
汇总表
现在我们可以提供一个大家熟知的表。但是为了清楚起见,此处添加了标准中缺少的最后一列。

“-“ 表示在该级别下不会发生 Yes 表示在级别上会发生
为什么是这些异常?
为什么标准仅列出许多可能的异常中的几个,为什么是这些异常?
似乎没有人知道这一点。但是这里的做法显然比理论要先进,因此在那时(SQL:92标准)可能还没有想到其他异常。
另外,假定隔离必须建立在锁上。广泛使用的两阶段锁定协议(2PL)背后的思想是,在执行过程中,事务将锁定正在使用的行,并在完成时释放锁定。简单来说,一个事务获取的锁越多,它与其他事务的隔离性就越好。但是,系统的性能也会受到更大的影响,因为事务不是一起同时进行,而是开始排队等待相同的行。
我的感觉是,这只是所需的锁数,这解释了标准的隔离级别之间的差异。
如果事务锁定了要更新的行而不是读取的行,我们将使得“读取未提交”级别:不允许丢失更新,但可以读取未提交的数据。
如果事务锁定了要修改的行,使其无法读取和更新,则将使得“读取已提交”级别:无法读取未提交的数据,但是当您再次访问该行时,您可以获得一个不同的值(不可重复读取)。
如果事务锁定了要读取和修改的行以及读取和更新的行,使得“可重复读取”级别:重新读取该行将返回相同的值。
但是Serializable有一个问题:您不能锁定不存在的行。因此,幻读仍然是可能的:另一个事务可以添加(但不能删除)满足先前执行的查询条件的行,并且该行将包含在重新执行的select 语句中。
因此,要实现可序列化级别,普通锁不能满足要求- 需要锁定条件(谓词)而不是行。因此,此类锁称为谓词。它们是在1976年提出的,但是它们的实际适用性受到相当简单的条件的限制 – 很明显的例子,比如,如何将两个不同的谓词结合在一起。据我所知,目前为止,这种锁从未在任何系统中实现。
PostgreSQL中的隔离级别
随着时间的流逝,基于锁定的事务管理协议已被快照隔离协议(SI)取代。其想法是,每个事务在某个时间点都使用数据的一致快照,并且只有那些更改会进入创建快照之前提交的快照。
这种隔离会自动防止脏读。当然,您可以在PostgreSQL中指定Read Uncommitted级别,但是它的工作方式与Read Committed完全相同。因此,接下来,我们将不再谈论“读取未提交”级别。
PostgreSQL实现了该协议的数据多版本的变体。多版本并发的想法是,同一行的多个版本可以在DBMS中共存。这使您可以使用现有版本构建数据快照,并使用最少的锁。实际上,只有随后对同一行的更改被锁定。所有其他操作是同时执行的:写事务永远不会锁定只读事务,而只读事务永远不会锁定任何东西。
通过使用数据快照,PostgreSQL中的隔离比标准要求的严格:“可重复读取”级别不仅不允许不可重复的读取,也不允许幻读(尽管它不提供完全隔离)。并且这在不损失效率的情况下实现。

在下一篇文章中,我们将讨论MVCC 的背后实现机制,现在,我们将以用户的眼光详细地研究这三个级别中的每个级别(如您所知,最有趣的隐藏在“其他异常”之后) ”。为此,我们创建一个帐户表。爱丽丝和鲍勃各有1000元,但鲍勃有两个帐户:
=> CREATE TABLE accounts(
id integer PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
number text UNIQUE,
client text,
amount numeric );
=> INSERT INTO accounts VALUES
(1, '1001', 'alice', 1000.00),
(2, '2001', 'bob', 100.00),
(3, '2002', 'bob', 900.00);
读已提交
没有脏读
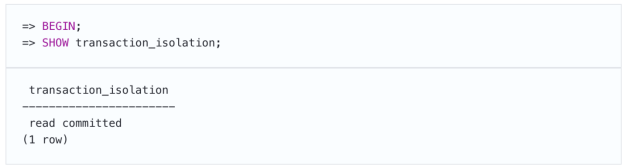
很容易确保不会读取脏数据。我们开始事务。默认情况下,它将使用Read Committed隔离级别:
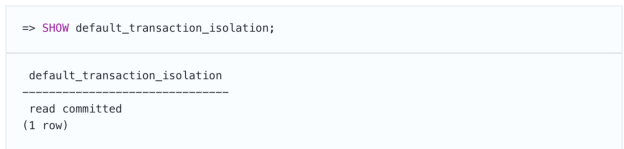
更准确地说,默认级别由参数设置,如有必要,可以更改:
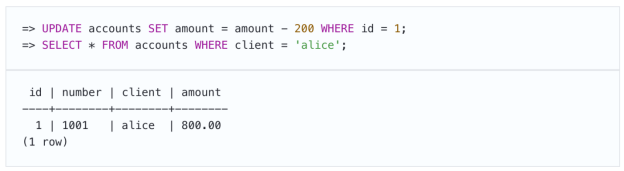
因此,在一个事务中,我们从帐户中提取资金,但不提交更改。事务会看到自己的变化:
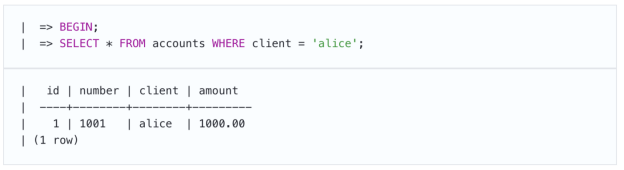
在第二个会话中,我们将开始另一个具有相同“读取已提交”级别的事务。为了区分事务,第二个事务的命令将缩进并用条形标记。
为了重复上述命令(这很有用),您需要打开两个终端并在每个终端中运行psql。在第一个终端中,您可以输入一个事务的命令,而在第二个终端中,您可以输入另一个事务的命令。
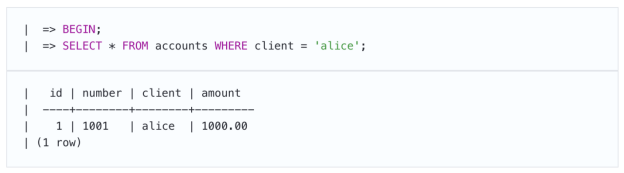
正如预期的那样,其他事务不会看到未提交的更改,因为不允许脏读。
不可重复读

现在,让第一个事务提交更改,第二个事务重新执行相同的查询。
第一个事务提交
第二个事务重新进行查询
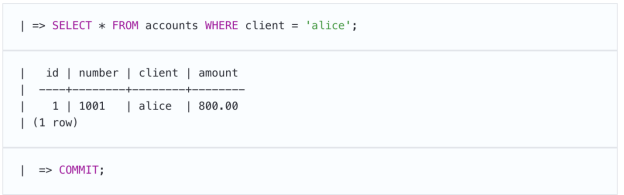
该查询已获取新数据,这是不可重复的读取异常,在“读取已提交”级别允许。
实际结论:在事务中,您不能基于前一个操作读取的数据来做出决策,因为数据在执行这些操作之间可能会发生变化。这是一个示例,其变体经常在应用程序代码中发生,因此被认为是经典的反例:

在检查和更新之间的这段时间内,其他事务可以以任何方式更改帐户的状态,因此这种“检查”不能确保任何事。可以很容易的想象到在一个的操作之间其他事物的其他操作啃呢个会插入进来,比如:
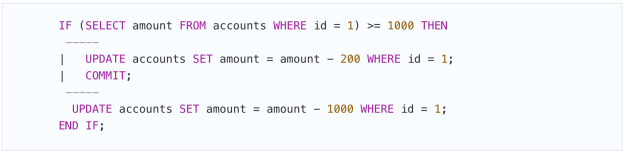
如果一切都可以通过重新编写操作顺序来避免,则代码编写错误。也不要自欺欺人,安慰自己这种情况不会发生。
但是如何正确编写代码?选项通常如下:
- 不写代码
这不是一个玩笑。例如,在这种情况下,检查很容易变成完整性约束:
ALTER TABLE accounts ADD CHECK amount> = 0;
现在无需检查:只需执行该操作,并在必要时处理出现完整性冲突时发生的异常。 - 使用单个SQL语句
出现一致性问题是因为在操作之间的时间间隔内,另一个事务可以完成,这将更改可见数据。而且,如果只有一个操作,则这中间没有时间间隔。PostgreSQL拥有足够的技术让一个SQL语句解决复杂问题。让我们注意一下通用表表达式(CTE),在其余表中,您可以使用INSERT/UPDATE/DELETE语句,以及INSERT ON CONFLICT语句,该语句实现了“插入,但如果该行已经存在,则更新。 - 自定义锁
最后的方法是在所有必需的行(SELECT FOR UPDATE)上甚至在整个表(LOCK TABLE)上手动设置排他锁。这始终有效,但是使多版本并发的好处无效:某些操作将顺序执行,而不是并发执行。
不一致读
在进入下一个隔离级别之前,您必须承认它并不像听起来那样简单。PostgreSQL的实现允许其他不受标准规范的鲜为人知的异常。
假设第一笔事务开始将资金从一个Bob的帐户转移到另一个帐户:

同时,另一笔事务计算了Bob的余额,并且会一个一个的检查Bob名下的账户。实际上,事务是从第一个帐户开始的(显然,看到的是先前的状态):
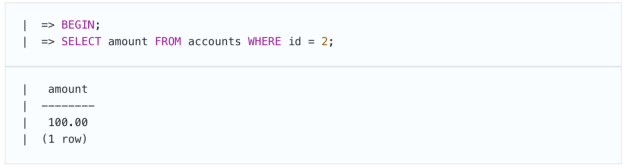
此时,第一个事务成功完成:

另一个读取第二个帐户的状态(并且已经看到新值):

因此,第二笔事务总计1100,即数据不正确。这是不一致的读取异常。
在 “读取已提交” 级别中如何避免这种异常?请使用一个操作。例如:

到现在为止,我断言数据可见性只能在操作之间改变,实际情况是这么明显吗?如果查询花费的时间很长,是否可以查看处于一种状态的数据的一部分和处于另一种状态的数据的一部分?
让我们看一下。一种方便的方法是通过调用pg_sleep函数将强制延迟插入到操作中。其参数以秒为单位指定延迟时间。

执行此操作后,我们将在另一笔事务中将资金转回:

结果显示,第一个事务以执行操作开始时的状态查看数据。这无疑是正确的。

但这也不是那么简单。PostgreSQL允许您定义函数,并且函数具有Volatility 类别的概念。如果在查询中调用了VOLATILE函数,并在该函数中执行了另一个查询,则该函数内部的查询将看到与主查询中的数据不一致的数据。



在这种情况下,我们得到的数据不正确-损失了100:

我强调,只有在“读已提交”隔离级别和带有VOLATILE的函数中,这种效果才可能实现。问题在于,默认情况下,仅使用此隔离级别和volatility类别。不要陷入陷阱!
读取不一致以换取丢失的更改
在更新过程中,尽管有各种出乎意料的方式,我们也可能在单个操作中读取到不一致的内容。
让我们看看当两个事务试图修改同一行时会发生什么。现在鲍勃在两个帐户上有1000元:
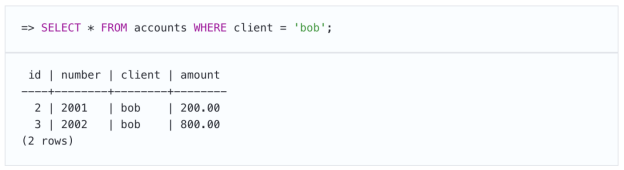
我们开始进行事务以减少Bob的余额:

同时,在另一笔事务中,所有客户帐户的总余额等于或大于1000英镑,产生利息:
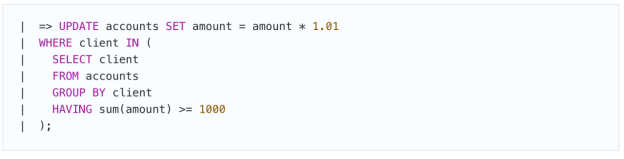
UPDATE运算符的执行包括两个部分。首先,实际上是执行SELECT,这将选择要更新的符合适当条件的行。因为第一笔事务中的更改未提交,所以第二笔事务看不到它,因此该更改不会影响应计利息行的选择。好了,鲍勃的帐户满足条件,一旦执行更新,他的余额应增加10元。
执行的第二阶段是逐一更新所选行。在这里,第二个事务被迫“挂起”,因为id = 3的行已被第一个事务锁定。
同时,第一个事务提交更改:

结果将是什么?
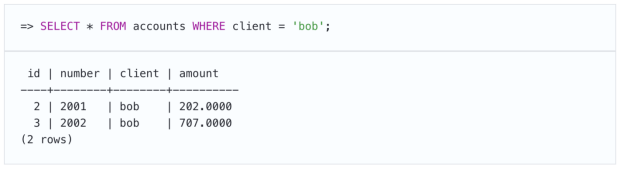
好吧,一方面,UPDATE命令应该看不到第二个事务的更改。但是,另一方面,它不应丢失在第二笔事务中提交的更改。
释放锁后,UPDATE将重新读取它尝试更新的行(但仅此行)。结果,鲍勃根据900英镑的金额累计了9英镑。但是如果鲍勃有900英镑,那么他的帐户根本就不会出现在此次更新中。
因此,该事务获取了不正确的数据:某些行在某个时间点可见,而另一些在另一时间点可见。取代了丢失更新,我们还是再次看到了不一致的读取异常。
细心的读者会注意到,在应用程序的某些帮助下,即使在“读已提交”级别下,也可能会丢失更新。例如:

我们不应该责怪数据库,因为它执行了两个SQL语句,并且对x + 100的值与帐户金额有某种关系这一事实一无所知。我们应避免以这种方式编写代码。
可重复读
不可重复读和幻读
隔离级别的确切名称假定读取是可重复的。让我们检查一下,同时确保没有幻读。为此,在第一笔事务中,我们将Bob的帐户还原为以前的状态,并为Charlie创建一个新帐户:

在第二个会话中,我们通过在BEGIN命令中指定”可重复读”级别来启动事务(第一个事务的级别是非必需的)。
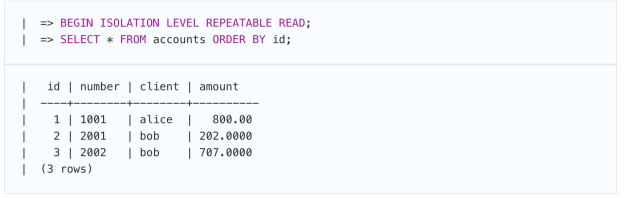
现在,第一个事务提交更改,第二个事务重新执行相同的查询。


第二个事务仍然看到与开始时完全相同的数据:现有行或新行的更改均不可见。
在此级别上,您可以避免担心两个操作之间的数据可能会发生。
序列化错误以换取丢失的更改
前面我们已经讨论过,当两个事务在“读取已提交”级别更新同一行时,可能会发生读取不一致的异常。这是因为等待的事务重新读取了锁定的行,因此在与其他行相同的时间点看不到它。
在“可重复读取”级别,此异常是不允许的,但是如果发生这种异常,则无法进行任何操作-因为,事务因序列化错误而终止。让我们通过重现应计利息的场景来检查它:

忽略



数据保持一致:

即使一行的任何其他竞争性更改没有发生,即使我们关注的列没有实际更改,也会发生相同的错误。
实际结论:如果您的应用程序对写入事务使用“可重复读取”隔离级别,则它必须准备好重复因序列化错误而终止的事务。对于只读事务,此结果是不可能的。
写入不一致(写入偏差)
因此,在PostgreSQL中,在“可重复读取”隔离级别上,可以防止标准中描述的所有异常。但总的来说并非所有异常。事实证明,仍然有两种异常仍然可能。(这不仅适用于PostgreSQL,而且适用于快照隔离的其他实现。)
这些异常中的第一个是不一致的写。
让以下一致性规则成立:如果该客户所有帐户上的总金额保持非负数,则允许该客户帐户上的负金额。第一笔事务在鲍勃的帐户上获得的金额为900。
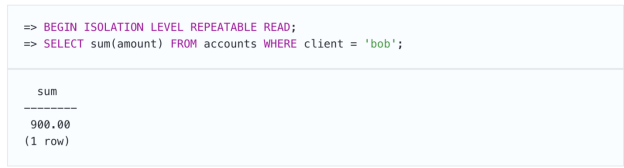
第二笔事务获得相同的金额。
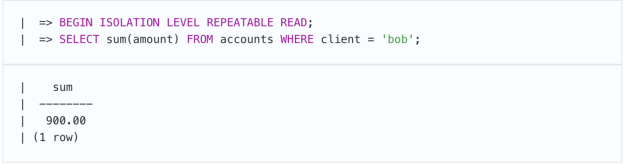
第一笔事务正确地认为,其中一个帐户的金额可以减少600。

第二笔事务得出相同的结论。但这减少了另一个帐户:

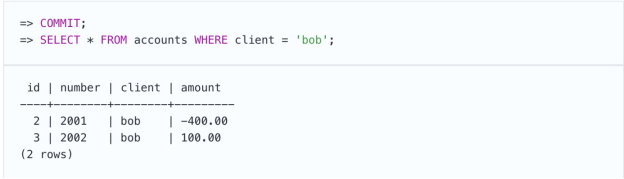
尽管每笔事务都能正常运作,但我们设法使Bob的余额变成了红色。
只读事务异常
这是可重复读取级别可能出现的第二个异常,也是最后一个异常。为了演示它,您将需要三个事务,其中两个事务将更改数据,而第三个事务将仅读取它。
首先让我们恢复Bob的帐户状态:

在第一笔事务中,将累积所有Bob帐户上可用金额的利息。利息记入他的帐户之一:

然后,另一笔事务从另一个鲍勃的帐户中提款并进行更改:

如果此时执行了第一笔事务,则不会发生异常:我们可以假设第一笔事务先执行,然后再执行第二笔事务(但反之则不然,因为在此之前,第一笔事务的帐户状态为id = 3帐户已被第二次事务更改)。
但是,想象一下,第三点(只读)事务在此时开始,它读取不受前两个事务影响的某些帐户的状态:
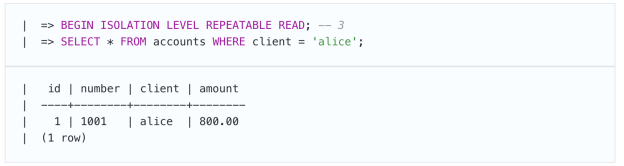
并且只有在第一笔事务完成后:

第三笔事务现在应该看到什么状态?

一旦开始,第三个事务可以看到第二个事务(已经提交)的更改,但是看不到第一个(尚未提交)的更改。另一方面,我们已经在上面确定了第二笔事务应视为在第一笔事务之后开始。无论第三笔事务看到什么状态,都将不一致-这只是只读事务的异常。但在“可重复读取”级别,则允许:

可序列化
可序列化级别可防止所有可能的异常。实际上,可序列化是建立在快照隔离之上的。可重复读取不会发生的那些异常(例如脏读,不可重复读取或幻读)也不会在可序列化级别上发生。并且检测到那些发生的异常(不一致的写入和只读事务异常),会导致事务中止-发生一个熟悉的序列化错误:无法序列化访问。
写入不一致(写入偏差)
为了说明这一点,让我们复现不一致的写入异常的场景:

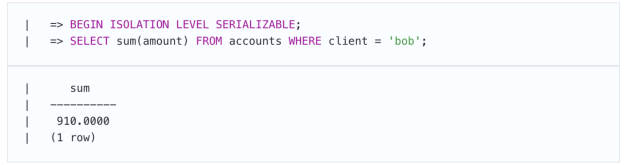


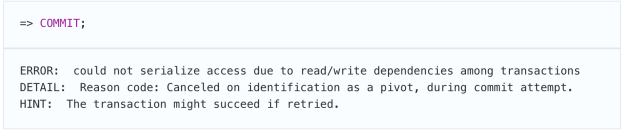
就像在“可重复读取”级别上一样,使用“可序列化”隔离级别的应用程序必须重复被序列化错误终止的事务,如错误消息提示我们的那样。
我们可以简化编程,但是这样做的代价是强制终止部分事务,并且需要重复执行。当然,问题是这个收益有多大。如果仅那些终止的事务与其他事务不兼容地重叠,那就太好了。但是,由于您必须跟踪每一行的操作,因此这种实现不可避免地会占用大量资源并且效率低下。
实际上,PostgreSQL的实现允许错误的否定:一些绝对“不幸”的绝对正常的事务也将中止。稍后我们将看到,这取决于许多因素,例如适当索引的可用性或可用的RAM数量。此外,还有其他一些(相当严格的)实现限制,例如,“可序列化”级别的查询将不适用于副本,并且它们将不使用并行执行计划。尽管改进实施的工作仍在继续,但是现有的限制使这种隔离级别的吸引力降低了。
并行执行计划最早会在PostgreSQL 12(patch)中出现。对副本的查询可以在PostgreSQL 13(另一个补丁)中开始工作。
只读事务异常
为了使只读事务不引起异常并且不遭受异常的困扰,PostgreSQL提供了一种有趣的技术:可以锁定这样的事务,直到其执行安全为止。只有通过行更新才能锁定SELECT运算符时,这是唯一的情况。这是这样的:



第三个事务被显式声明为READ ONLY和DEFERRABLE:

尝试执行查询时,事务将被锁定,因为否则会导致异常。

并且只有在提交第一个事务之后,第三个事务才继续执行:

另一个重要说明:如果使用了可序列化隔离,则应用程序中的所有事务都必须使用此级别。您不能将已提交读(或可重复读)事务与可序列化混在一起。也就是说,您可以混合使用,但是Serializable的行为类似于“可重复读取”,而没有任何警告。我们将在稍后讨论实现时,讨论为什么会发生这种情况。因此,如果您决定使用Serializble,则最好全局设置默认级别(尽管这当然不会阻止您明确指定不正确的级别):

您可以在Boris Novikov的“数据库技术基础”一书和讲座中找到有关事务,一致性和异常问题的更加严格的介绍(目前仅有俄文版)。
使用什么隔离级别?
PostgreSQL默认使用Read Committed隔离级别,并且可能在绝大多数应用程序中使用此级别。此默认设置很方便,因为在此级别上,只有在失败的情况下才可能中止事务,但不能用作防止不一致的手段。换句话说,不会发生序列化错误。
另一方面这可能带来大量可能的异常,上面已经详细讨论过。软件工程师必须在编写代码的过程中始终牢记它们,以免它们出现。如果无法在单个SQL语句中编写必要的操作,则必须诉诸显式锁定。最麻烦的是,代码很难测试与获取不一致的数据相关的错误,并且错误本身可能以不可预测和不可重现的方式发生,因此难以修复。
可重复读取隔离级别消除了一些不一致的问题,但可惜的是,并不是全部。因此,您不仅必须记住剩余的异常情况,还必须修改应用程序以使其正确处理序列化错误。当然不方便。但是对于只读事务,此级别完美地补充了“已提交读”操作,并且非常方便,例如,用于构建使用多个SQL查询的报表。
最后,可序列化级别使您完全不必担心不一致,这大大简化了编码。该应用程序唯一需要的是在发生序列化错误时能够重复任何事务。但是中止事务的比例,额外的开销以及无法并行化查询会显着降低系统吞吐量。还要注意,可序列化级别不适用于并行,并且不能与其他隔离级别混合。
