参考一
该博文分为以下6个部分:
- tensor.requires_grad
- torch.no_grad()
- 反向传播及网络的更新
- tensor.detach()
- CPU and GPU
- tensor.item()
torch.detach()和torch.data的区别是,在求导时,torch.detach()会检查张量的数据是否发生变化,而torch.data则不会去检查。
参考二
该博文讲了backward()、叶子张量、inplace操作、动态图和静态图的区别等,概要如下:
- 在我们做正向传播的时候,需要求导的变量除了执行
forward()操作之外,还会同时会为反向传播做一些准备,为反向计算图添加一个Function节点。 - 如何判断是否是叶子张量:当这个tensor是用户创建的时候,它是一个叶子节点,当这个tensor是由其他运算操作产生的时候,它就不是一个叶子节点。
- 只有叶子张量的导数结果才会被最后保留下来,其他张量的导数用完就被释放。也就是说,在整个计算图的backward()完成之后,叶子张量的grad是有数值的,而其他张量的grad是None。
- inplace指的是在不更改变量的内存地址的情况下,直接修改变量的值。
- 如果一个变量同时参与了正向传播和反向传播,那么最好不要对它使用inplace操作,因为inplace操作可能会引起反响传播时报错。
- 所谓动态图,就是每次当我们搭建完一个计算图,然后在反向传播结束之后,整个计算图就在内存中被释放了。如果想再次使用的话,必须从头再搭一遍。而以TensorFlow为代表的静态图,每次都先设计好计算图,需要的时候实例化这个图,然后送入各种输入,重复使用,只有当会话结束的时候创建的图才会被释放。
- 变量.grad_fn表明该变量是怎么来的,用于指导反向传播。例如loss = a+b,则loss.gard_fn为<AddBackward0 at 0x7f2c90393748>,这个grad_fn可指导怎么求a和b的导数。
实例
import torch input = torch.tensor([[1., 2.], [3., 4.]], requires_grad=False) w1 = torch.tensor(2.0, requires_grad=True) w2 = torch.tensor(3.0, requires_grad=True) l1 = input * w1 l2 = l1 + w2 loss = l2.mean() loss.backward() print(input.grad) # 输出:None print(w1.grad) # 输出:tensor(2.5) print(w2.grad) # 输出:tensor(1.) print(l1.grad, l2.grad, loss.grad) # 输出: None None None # 因为l1, l2, loss都是非叶子张量,所以它们的导数不会被保存,即它们的.grad为None print(l1.grad_fn) # 输出:<MulBackward0 object at 0x7f10feeb1a20> 表明l1是由相乘得来的,用于指导向后求导 print(loss.grad_fn) # 输出:<MeanBackward1 object at 0x7f10feeb1a20>
我们可以手动求导验证一下w1和w2的导数对不对:
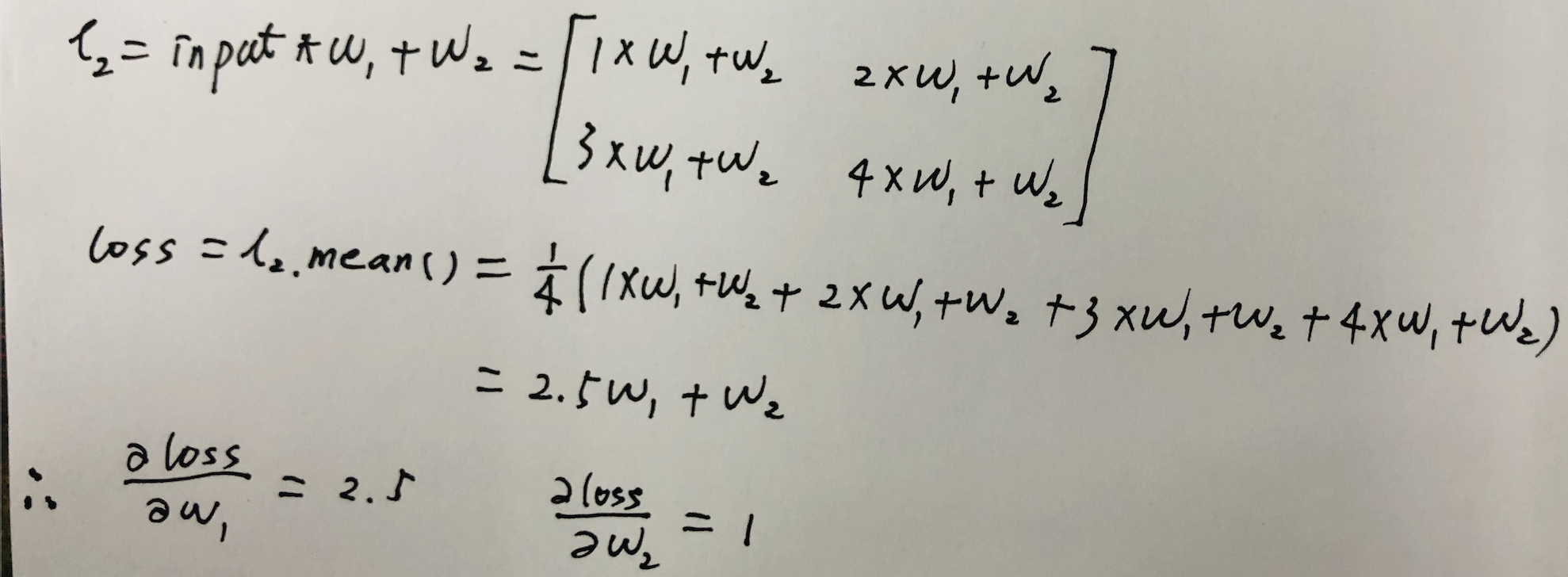
说明程序求导结果是对的。
如果我们把input的requires_grad改为True,则input也变为叶子张量了,loss需要对齐求导,并且导数会被保存:
import torch
input = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
w1 = torch.tensor(2.0, requires_grad=True)
w2 = torch.tensor(3.0, requires_grad=True)
l1 = input * w1
l2 = l1 + w2
loss = l2.mean()
loss.backward()
print(input.grad) # 输出:tensor([[0.5000, 0.5000],
# [0.5000, 0.5000]])
print(w1.grad) # 输出:tensor(2.5000)
print(w2.grad) # 输出:tensor(1.)
print(l1.grad, l2.grad, loss.grad) # 输出: None None None
# 因为l1, l2, loss都是非叶子张量,所以它们的梯度不会被保存,即它们的.grad为None
我们可以手动求导验证一下:
说明程序求导结果是对的。