Java里面两种配置文件:XML和Properties文件!
只要是A标签这种没有办法指定提交方式(GET/POST)的标签,都是GET方式提交!
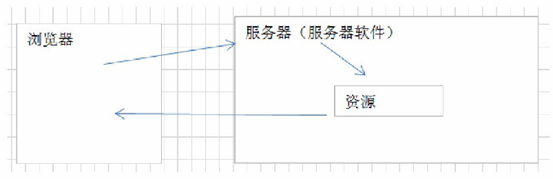
Servlet:请求-->响应!
XML指可扩展标记语言,XML被设计用来传输和存储数据!
Servlet执行机制:

XML个称为Extensible Markup Language,意思是可扩展的标记语言!XML语法上和HTML比较相似,但HTML中的元素是固定的,而XML的标签是可以由用户自定义的!
XML文档声明
1;文档声明必须为<?xml开头,以?>结束!
2;文档声明必须从文档的0行0列位置开始!
3;文档声明只有属性!
versioin:指定XML文档版本,必须属性,不会选择1.1,只会选择1.0!
encoding:指定当前文档的编码,可选属性,默认值是:utf-8!
元素Element:

1;元素是XML文档中最重要的组成部分!
2;普通元素的结构开始标签,元素体,结束标签组成!
3:元素体:元素体可以是元素,也可以是文本!
4:空元素:空元素只有开始标签,而没有结束标签,但元素必须自己闭介!
5:元素命名:
区分大小写!
不能使用空格,不能使用冒号!
不建议以XML,xml,Xml开头!
6:格式化良好的XML文档,必须只有一个根元素!
属性

1;属性是元素的一部分,它必须出现在元素的开始标签中!
2;属性的定义格式:属性名=属性值,其中属性值必须使用单引或双引!
3;一个元素可以有0~N个属性,但一个元素中不能出现同名属性!
4;属性名不能使用空格,冒号等特殊字符,且必须以字母开头!
注释:
XML的注释与HTML相同,即以<!--开始,以-->结束!注释内容会被XML解析器忽略!
转义字符
XML中的转义字符与HTML一样(HTML实体)!
因为很多符号己经被XML文档结构所使用,所以在元素体或属性值中想使用这些符号就必须使用转义字符!
CDATA区

当大量的转义字符出现在XML文档中时,会使XML文档的可读性大幅度降低!
此时可以使用CDATA!
1:内部DTD,在XML文档内部嵌入DTD,只对当前XML有效!
|
<?xml version="1.0" encoding="UTF-8"? standalone="yes" ?> <!DOCTYPE web-app [ ...//具体语法 ]> <web-app> </web-app> |
2:外部DTD——本地DTD,DTD文档在本地系统上,公司内部自己项目使用!

3:外部DTD——公共DTD,DTD文档在网络上,一般都有框架提供!

XML文件中的特殊符号释义:
|
定义元素语法:<!ELEMENT元素名 元素描述> 元素名:自定义 元素描述包括 : 符号和数据类型 常见符号: ? * + () | , 常见类型:#PCDATA表示内容是文本,不能是子标签 |
|
符号 |
符号类型 |
描述 |
示例 |
|
? |
问号 |
表示该对象可以出现,但只能出现一次 |
(菜鸟?) |
|
* |
星号 |
表示该对象允许出现任意多次,也可以是零次 |
(爱好*) |
|
+ |
加号 |
表示该对象最少出现一次,可以出现多次 |
(成员+) |
|
() |
括号 |
用来给元素分组 |
(古龙|金庸|梁羽生), (王朔|余杰),毛毛 |
|
| |
竖条 |
表明在列出的对象中选择一个 |
(男人|女人) |
|
, |
逗号 |
表示对象必须按指定的顺序出现 |
(西瓜,苹果,香蕉) |
DTD和Schema约束:
Schema约束更加规范化一点!
Schema优点:
Schema是新的XML文档约束:
Schema要比DTD强大很多,是DTD替代者;
Schema本身也是XML文档,但Schema文档的扩展名为xsd,而不是xml .
Schema功能更强大,数据类型更完善
Schema支持名称空间
DTD约束文件:
<servlet>
<!-- 不可以使用空格和冒号 -->
<!-- 3 -->
<servlet-name>HelloServlet</servlet-name>
<!-- 4是包名加类名文件 -->
<servlet-class>com.oracle.helloservlet</servlet-class>
</servlet>
<servlet-mapping>
<!-- 2和3名字必须相同 -->
<servlet-name>HelloServlet</servlet-name>
<!-- 1页面进来先找URL地址,必须以/开头 -->
<url-pattern>/hello</url-pattern>
</servlet-mapping>
Schema约束文件规范:
<!-- Schema约束,需要手动加入结束标签 -->
<web-app xmlns="http://www.example.org/web-app_2_5"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.example.org/web-app_2_5 web-app_2_5.xsd"
version="2.5">
</web-app>
解析方式和解析器:
1;DOM:要求解析器把整个XML文档装载到内存,并解析成一个Document对象!
① 优点:元素与元素之间保留结构关系,故可以进行增删改查操作!
② 缺点:XML文档过大,可能出现内存溢出显现!
2;SAX:是一种速度更快,更有效的方法!它逐行扫描文档,一边扫描一边解析!并以事件,驱动的方式进行具体解析,每执行一行,都将触发对应的事件!
① 优点:处理速度快,可以处理大文件
② 缺点:只能读,逐行后将释放资源!
3;PULL:Android内置的XML解析方式,类似SAX!
解析器释义:
① 解析器:就是根据不同的解析方式提供的具体实现,有的解析器操作过于繁琐,为了方便开发人员,有提供易于操作的解析开发包!

① 常见的解析开发包:
① JAXP:Sun公司提供支持DOM和SAX开发包!
② JDom:Dom4J兄弟!
③ JSoup:一种处理HTML特定解析开发包!
④ Dom4J:比较常用的解析开发包,Hibernate底层采用!
原理示意图:
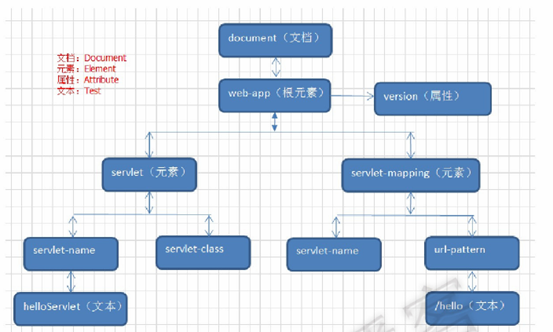
解析器使用如下:

步骤:
1.获取解析器
2.获得document文档对象
3.获取根元素
4.获取根元素下的子元素
5.遍历子元素
6.判断元素名称为servlet的元素
7.获取servlet-name元素
8.获取servlet-class元素
作业代码:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE web-app SYSTEM "web-app_2_3.dtd"> <web-app> <servlet> <servlet-name>HelloServlet</servlet-name> <servlet-class>com.oracle.homework.HelloServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>HelloServlet</servlet-name> <url-pattern>/HelloServlet</url-pattern> </servlet-mapping> <welcome-file-list> <welcome-file>index.jsp</welcome-file> </welcome-file-list> </web-app> <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://www.example.org/web-app_2_5" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.example.org/web-app_2_5 web-app_2_5.xsd" version="2.5"> <servlet> <servlet-name>TestServlet</servlet-name> <servlet-class>com.oracle.homework.TestServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>TestServlet</servlet-name> <url-pattern>/TestServlet</url-pattern> </servlet-mapping> <welcome-file-list> <welcome-file>index.jsp</welcome-file> </welcome-file-list> </web-app> package com.oracle.homework; import java.util.List; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class TestQues3 { public static void main(String[] args) throws DocumentException { //获取解析器: SAXReader saxr=new SAXReader(); //获取Document文档: Document doc=saxr.read("src/com/oracle/homework/WebXSD.xml"); //获取文档中的根标签,拿到web-app: Element rootEle=doc.getRootElement(); //获取跟标签的子标签放进List集合: List<Element> childEle=rootEle.elements(); //遍历该集合: for(Element ele:childEle){ if("servlet".equals(ele.getName())){ System.out.println(ele.element("servlet-name").getName()); System.out.println(ele.element("servlet-class").getName()); }else if("servlet-mapping".equals(ele.getName())){ System.out.println(ele.element("servlet-name").getName()); System.out.println(ele.element("url-pattern").getName()); } System.out.println(ele.getName()); } } } //定义接口: package com.oracle.homework; public interface MyServlet { public void init(); public void service(); public void distory(); } //实现以上接口: package com.oracle.homework; public class MyServletImp implements MyServlet { @Override public void init() { System.out.println("这是Init"); } @Override public void service() { System.out.println("这是Service"); } @Override public void distory() { System.out.println("这是Distory"); } } //进行不可描述的操作: package com.oracle.homework; import java.util.List; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class TestMyServlet { public static void main(String[] args) throws DocumentException, ClassNotFoundException, InstantiationException, IllegalAccessException { //获取解析器: SAXReader saxr=new SAXReader(); //获取Document文档: Document doc=saxr.read("src/com/oracle/homework/MyServletXSD.xml"); //获取根标签web-app: Element rootEle=doc.getRootElement(); //获取rootEle的子元素并放进List集合: List<Element> childEle=rootEle.elements(); //定义String接收,并遍历赋值: String getPackClass=null; for(Element ele:childEle){ if("servlet".equals(ele.getName())){ getPackClass=ele.element("servlet-class").getText(); } } //获取字节码文件对象: Class cla=Class.forName(getPackClass); //获取Object对象: MyServletImp myser=(MyServletImp)cla.newInstance(); myser.init(); myser.service(); myser.distory(); } }