前言:
Redis hash是一个String类型的field和value的映射表。添加、删除操作复杂度平均为O(1),为什么是平均呢?因为Hash的内部结构包含zipmap和hash两种。hash特别适合用于存储对象。相对于将对象序列化存储为String类型,将一个对象存储在hash类型中会占用更少的内存,并且可以方便的操作对象。为什么省内存,因为对象刚开始使用zipmap存储的。
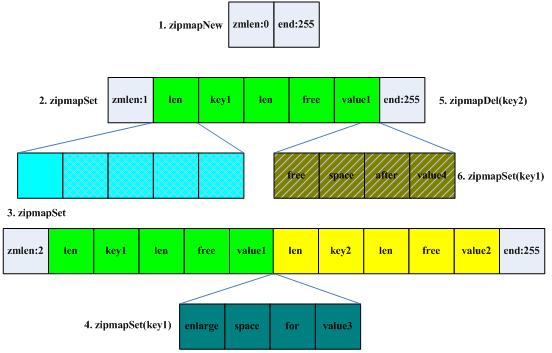
1. zipmap
zipmap其实并不是hashtable,zip可以节省hash本身需要的一些元数据开销。zipmap的添加、删除、查找复杂度为O(n),但是filed数量都不多,所以可以说平均是O(1)。
默认配置:
hash-max-ziplist-entries 512 //filed最多512个
hash-max-ziplist-value 64 //value最大64字节
内存分配如下:
例:"foo" => "bar", "hello" => "world":<zmlen><len>"foo"<len><free>"bar"<len>"hello"<len><free>"world"
(1)zmlen:记录当前zipmap的key-value对的数量。一个字节,因此规定其表示的数量只能为0~254,当zmlen>254时,就需要遍历整个zipmap来得到key-value对的个数
(2)len:记录key或value的长度,有两种情况,当len的第一个字节为0~254(注释是253,我们以代码为准)时,那么len就只占用这一个字节。若len的第一个字节为254时,那么len将用后面的4个字节来表示。因此len要么占用1字节,要么占用5字节。
(3)free:记录value后面的空闲字节数,将”foo” => “world”变为”foo” => “me” ,那么会导致3个字节的空闲空间。当free的字节数过大用1个字节不足以表示时,zipmap就会重新分配内存,保证字符串尽量紧凑。
(4)end: 记录zipmap的结束,0xFF
zipmap创建:
2.hash
在Redis中,hash表被称为字典(dictionary),采用了典型的链式解决冲突方法,即:当有多个key/value的key的映射值(每对key/value保存之前,会先通过类似HASH(key) MOD N的方法计算一个值,
以便确定其对应的hash table的位置)相同时,会将这些value以单链表的形式保存;同时为了控制哈希表所占内存大小,redis采用了双哈希表(ht[2])结构,并逐步扩大哈希表容量(桶的大小)的策略,
即:刚开始,哈希表ht[0]的桶大小为4,哈希表ht[1]的桶大小为0,待冲突严重(redis有一定的判断条件)后,ht[1]中桶的大小增为ht[0]的两倍,并逐步(注意这个词:”逐步”)将哈希表ht[0]中元素迁移(称为“再次Hash”)到ht[1],
待ht[0]中所有元素全部迁移到ht[1]后,再将ht[1]交给ht[0](这里仅仅是C语言地址交换),之后重复上面的过程。

Redis哈希表的实现位于文件dict.h和dict.c中,主要数据结构如下:
#define DICT_NOTUSED(V) ((void) V) typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry; typedef struct dictType { unsigned int (*hashFunction)(const void *key); void *(*keyDup)(void *privdata, const void *key); void *(*valDup)(void *privdata, const void *obj); int (*keyCompare)(void *privdata, const void *key1, const void *key2); void (*keyDestructor)(void *privdata, void *key); void (*valDestructor)(void *privdata, void *obj); } dictType; /* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht; typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ int iterators; /* number of iterators currently running */ } dict;
基本操作:
Redis中hash table主要有以下几个对外提供的接口:dictCreate、dictAdd、dictReplace、dictDelete、dictFind、dictEmpty等,而这些接口调用了一些基础操作,包括:_dictRehashStep,_dictKeyIndex等
Hash Table在一定情况下会触发rehash操作,即:将第一个hash table中的数据逐步转移到第二个hash table中。
(1)触发条件 当第一个表的元素数目大于桶数目且元素数目与桶数目比值大于5时,hash 表就会扩张,扩大后新表的大小为旧表的2倍。
/* Expand the hash table if needed */ static int _dictExpandIfNeeded(dict *d) { /* Incremental rehashing already in progress. Return. */ if (dictIsRehashing(d)) return DICT_OK; /* If the hash table is empty expand it to the initial size. */ if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); /* If we reached the 1:1 ratio, and we are allowed to resize the hash * table (global setting) or we should avoid it but the ratio between * elements/buckets is over the "safe" threshold, we resize doubling * the number of buckets. */ if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) { return dictExpand(d, d->ht[0].used*2); } return DICT_OK; }
(2)转移策略 为了避免一次性转移带来的开销,Redis采用了平摊开销的策略,即:将转移代价平摊到每个基本操作中,如:dictAdd、dictReplace、dictFind中,每执行一次这些基本操作会触发一个桶中元素的迁移操作。在此,有读者可能会问,如果这样的话,如果旧hash table非常大,什么时候才能迁移完。为了提高前移速度,Redis有一个周期性任务serverCron,每隔一段时间会迁移100个桶。
相关操作:
1.hset,hmset,hsetnx
hset命令用来将某个hash指定键的值,如果键不存在,则创建并设置对应的值,返回一个整数1,如果键已经存在,则对应的值将被覆盖并返回整数0.
hset hash_name field value
127.0.0.1:6379> hset userid:1000 age 100 (integer) 1 127.0.0.1:6379> hset userid:1000 age 10 (integer) 0
hmset命令和hset命令的作用相似,可以用来设置hash的键和值。不同的是hmset可以同时设置多个键值对。操作成功后hmset命令返回一个简单的字符串“OK”。
hset hash_name field value
127.0.0.1:6379> hmset userid:1000 name zhangsan age 10 OK
hsetnx命令也用来在指定键不存在的情况下设置键值信息。如果键不存在,则Redis会先创建键,然后设置对应的值,操作成功后返回整数1。如果该键已经存在,则该命令不进行任何操作,返回值为0
hsetnx hash_name field value
127.0.0.1:6379> HSETNX userid:1000 age 10 (integer) 0 127.0.0.1:6379> HSETNX userid:1000 weight 100 (integer) 1
2.hget,hmget,hgetall
hget命令用来获取某个hash指定key的值。如果该键存在,直接返回对应的值,否则返回nil。
hget hash_name field
127.0.0.1:6379> hget user:1000 name (nil) 127.0.0.1:6379> hget userid:1000 name "zhangsan"
hmget命令和hget命令类似,用来返回某个hash多个键的值的列表,对于不存在的键,返回nil值。
hmget hash_name field1 field2...
127.0.0.1:6379> hmget userid:1000 name age 1) "zhangsan" 2) "10"
hgetall命令返回一个列表,该列表包含了某个hash的所有键和值。在返回值中,先是键,接下来的一个元素是对应的值,所以hgetall命令返回的列表长度是hash大小的两倍。
hgetall hash_name
127.0.0.1:6379> HGETALL userid:1000 1) "age" 2) "10" 3) "name" 4) "zhangsan" 5) "weight" 6) "100"
3.hexists
hexists命令用来判断某个hash指定键是否存在,若存在返回整数1,否则返回0。
hexists hash_name field
127.0.0.1:6379> HEXISTS userid:1000 name integer) 1 127.0.0.1:6379> HEXISTS userid:1000 sex (integer) 0
4.hlen
hlen命令用来返回某个hash中所有键的数量。
hlen hash_name
127.0.0.1:6379> hlen userid:1000 (integer) 3
5.hdel
hdel命令用来删除某个hash指定的键。如果该键不存在,则不进行任何操作。hdel命令的返回值是成功删除的键的数量(不包括不存在的键)。
hdel hash_name field
127.0.0.1:6379> hlen userid:1000 (integer) 3 127.0.0.1:6379> hdel userid:1000 age (integer) 1 127.0.0.1:6379> hlen userid:1000 (integer) 2
6.Hkeys,hvals
hkeys命令返回某个hash的所有键,如果该hash不存在任何键则返回一个空列表。
hkeys hash_name
hvals命令返回某个hash的所有值的列表。
hvals hash_name
127.0.0.1:6379> hkeys userid:1000 1) "name" 2) "weight" 127.0.0.1:6379> hvals userid:1000 1) "zhangsan" 2) "100"
7.hincrby,hincrbyfloat
这两个命令都用来对指定键进行增量操作,不同的是hincrby命令每次加上一个整数值,而hincrbyfloat命令每次加上一个浮点值。操作成功后返回增量操作后的最终值
hincrby hash_name field i
hincrbyfloat hash_name field f
127.0.0.1:6379> HINCRBY userid:1000 weight 10 (integer) 110 127.0.0.1:6379> HINCRBYFLOAT userid:1000 weight 10.0 "120"