一般最短路径算法习惯性的分为两种:单源最短路径算法和全顶点之间最短路径。前者是计算出从一个点出发,到达所有其余可到达顶点的距离。后者是计算出图中所有点之间的路径距离。
单源最短路径
Dijkstra算法
思维
本质上是贪心的思想,声明一个数组dis来保存源点到各个顶点的最短距离和一个保存已经找到了最短路径的顶点的集合:S,原本的元素构成集合Q,初始时,原点 s 的路径权重被赋为 0 (dis[s] = 0)。若对于顶点 s 存在能直接到达的边(s,m),则把dis[m]设为w(s, m),同时把所有其他(s不能直接到达的)顶点的路径长度设为无穷大。初始时,集合S只有顶点s
然后,从dis数组选择最小值,则该值就是源点s到该值对应的顶点的最短路径,并且把该点加入到S中,此时完成一个顶点, 然后,我们需要看看新加入的顶点是否可以到达其他顶点并且看看通过该顶点到达其他点的路径长度是否比源点直接到达短,如果是,那么就替换这些顶点在dis中的值。 然后,又从dis中找出最小值,重复上述动作,直到S中包含了图的所有顶点。
但是很可惜,由于算法特性,一个点的距离确定后不会再改变,这里的确定不是指得到数值,而且该点被作为观察点观察后所以这个算法并不能处理带负权边的图。
但是可以利用该算法+优先队列来优化,优化后的算法打破了之前的一个点的距离确定后不会再改变的算法特性,更加类似SPFA,并且可以处理负权边。但个人觉得已经不能称作dijkstra算法了。
证明
这里给出一个命题:从集合Q中找到dis[k]最小的v,dis[k]即为源点到v的最短路径长度。
如果这个命题为真,dij的正确性就可以得证。
- 证明:从开始利用算法取得一个v1,即dis[v1]是最小的,(forall)v,dis[v]>dis[v1]。
假设dis[v1]不是从源点到v1最短路径
则(exists)v,使得dis[v]<dis[v1],与已知矛盾。
得证。 - 证明:已利用算法从Q中找到k个点,并确定了k个点的最短路径,此时再从Q中用算法找出一个vk+1,dis[vk+1]即为源点到vk+1最短路径。
假设dis[vk+1不是源点到vk+1的最短路径长度。
则设从源点到vk+1的最短路径经过的点的集合为V,dis为路径长度,切dis < dis[vk+1]。
设V中最靠近vk+1且不属于S的点为vx,vx的后继点为vy
。如果有向图中皆为正权边,则易得dis[vx] < dis[vy] <= dis。(vy = vk+1时等号成立)
但又因为vx不属于S,则dis[vx] > dis,矛盾。
得证。 - 综上所述,命题得证。
- 负权边的时候,dis[vx] < dis[vy]和dis[vx] > dis都不一定成立。故不得证。
举例演算
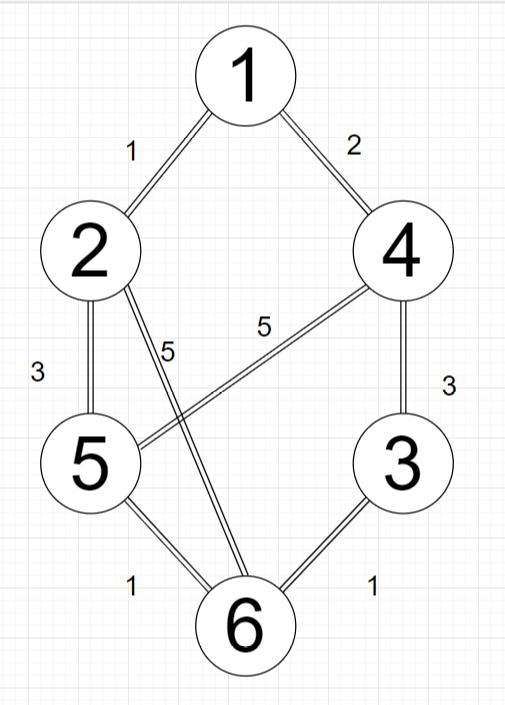
| 集合S | 当前观察点u | dis[2] | dis[3] | dis[4] | dis[5] | dis[6] |
|---|---|---|---|---|---|---|
| 1 | - | 1 | ∞ | 2 | ∞ | ∞ |
| 1,2 | 2 | 1 | ∞ | 2 | 4 | 6 |
| 1,2,4 | 4 | 1 | 5 | 2 | 4 | 6 |
| 1,2,4,5 | 5 | 1 | 5 | 2 | 4 | 6 |
| 1,2,4,5,3 | 3 | 1 | 5 | 2 | 4 | 5 |
| 1,2,4,5,3,6 | 6 | 1 | 5 | 2 | 4 | 5 |
从结点1出发,1与2、4连通,确定(1,2),(1,4)的距离,其中到2的距离最短,再从观察点2出发,2与5、6连通,根据dis[u]+c[u][v]<dis[v]的判断关系出发,更新dis。接着再分别从观察点4,5,3,6出发更新dis,得到最终的结点1的单源最短路径。
代码实现
朴素dij算法,时间复杂度约为O(n2)
#include<iostream>
#include<algorithm>
#include<cmath>
#include<vector>
#include<queue>
using namespace std;
const int maxn = 1000;
const int inf = 0x7fffffff;
int n, m;
int e[maxn][maxn], dis[maxn];
int book[maxn];
void dij(int s) {
for (int i = 1; i <= n; i++) dis[i] = e[s][i];
for (int i = 1; i <= n; i++) book[i] = 0;
book[s] = 1;
dis[s] = 0;
for (int i = 1; i <= n - 1; i++) {
int min = inf;
int u;
for (int j = 1; j <= n; j++) {
if (book[j] == 0 && dis[j] < min) {
min = dis[j];
u = j;
}
}
book[u] = 1;
for (int v = 1; v <= n; v++) {
if (e[u][v] < inf && book[v] == 0) {
if (dis[v] > dis[u] + e[u][v]) {
dis[v] = dis[u] + e[u][v];
}
}
}
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
e[i][j] = inf;
}
}
for (int i = 0; i < m; i++) {
int u, v, w;
cin >> u >> v >> w;
e[u][v] = w;
}
int x;
cin >> x;
dij(x);
for (int i = 1; i <= n; i++) {
cout << dis[i] << " ";
}
return 0;
}
为了能够方便的寻找当前最小的dis作为观察点,可以利用优先队列最小堆来优化。同时利用初始化建表来节省寻找每个点的相邻点的过程。这里使用的是stl中的优先队列,底层是heap实现的,应该是二叉堆,所以时间复杂度应该是O((m+n)logn),如果是使用斐波那契堆,可以到O(nlogn)。
#include<iostream>
#include<algorithm>
#include<cmath>
#include<vector>
#include<queue>
using namespace std;
const int MAX = 1000;
int h[MAX * 2], to[MAX * 2], nxt[MAX * 2], co[MAX * 2], dis[MAX], k = 0, n, m;
priority_queue<pair<int, int>, vector<pair<int, int> >, greater<pair<int, int> > > que;
void insert(int u,int v,int c) {
nxt[++k] = h[u];
h[u] = k;
to[k] = v;
co[k] = c;
nxt[++k] = h[v];
h[v] = k;
to[k] = u;
co[k] = c;
}
void dij(int s) {
for (int i = 0; i < MAX; i++) dis[i] = 0x7FFFFFFF;
dis[s] = 0;
que.push(make_pair(dis[s], s));
while (!que.empty()) {
pair<int, int> u = que.top();
que.pop();
if (dis[u.second] < u.first) continue;
for (int i = h[u.second]; i; i = nxt[i]) {
if (dis[to[i]] > dis[u.second] + co[i]) {
dis[to[i]] = dis[u.second] + co[i];
que.push(make_pair(dis[to[i]], to[i]));
}
}
}
}
int main() {
cin >> n >> m;
memset(h, 0, sizeof(h));
int u, v, c;
for (int i = 0; i < m; i++) {
cin >> u >> v >> c;
insert(u, v, c);
}
int x;
cin >> x;
dij(x);
for (int i = 1; i <= n; i++) {
if (dis[i] > 100000) cout << "none" << " ";
else cout << dis[i] << " ";
}
cout << endl;
return 0;
}