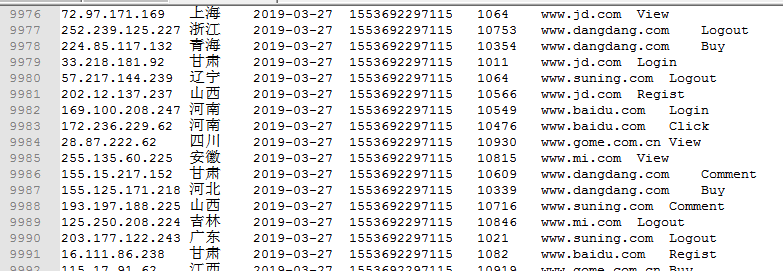
写脚本生成类似文件
java 代码
封装类
package day0327;
import java.util.UUID;
public class data {
private String ip;
private String address;
private String date;
private long timestamp;
// private UUID uuid;
private String uuid;
public String getUuid() {
return uuid;
}
public void setUuid(String uuid) {
this.uuid = uuid;
}
private String port;
private String method;
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public long getTimestamp() {
return timestamp;
}
public void setTimestamp(long timestamp) {
this.timestamp = timestamp;
}
/*public UUID getUuid() {
return uuid;
}
public void setUuid(UUID uuid) {
this.uuid = uuid;
}*/
public String getPort() {
return port;
}
public void setPort(String port) {
this.port = port;
}
public String getMethod() {
return method;
}
public void setMethod(String method) {
this.method = method;
}
}
主函数
package day0327;
import entity.Costinfo;
import java.io.*;
import java.sql.Array;
import java.sql.Timestamp;
import java.text.SimpleDateFormat;
import java.util.*;
public class Main {
public static void main(String[] args) {
/*Date date=new Date();
SimpleDateFormat dateFormat=new SimpleDateFormat("yyyy-MM-dd");
System.out.println(dateFormat.format(date));
// String s=dateFormat.format(date);
// long a=date.getTime();
System.out.println(date.getTime());
// Timestamp timestamp=new Timestamp();
Timestamp timestamp=new Timestamp(date.getTime());
System.out.println(timestamp);
UUID uuid = UUID.randomUUID();
System.out.println (uuid);*/
int i=1;
List<data> datas=new ArrayList<>();
for (i=1;i<=10000;i++){
data data=new data();
Random random=new Random();
int ip1=random.nextInt(256);
int ip2=random.nextInt(256);
int ip3=random.nextInt(256);
int ip4=random.nextInt(256);
String ip=ip1+"."+ip2+"."+ip3+"."+ip4;
data.setIp(ip);
String[] address={"北京", "天津", "上海", "重庆", "河北", "辽宁","山西","吉林", "江苏", "浙江", "黑龙江", "安徽", "福建", "江西","山东", "河南", "湖北", "湖南", "广东", "海南", "四川","贵州", "云南", "山西", "甘肃", "青海"};
int n=random.nextInt(address.length);
data.setAddress(address[n]);
Date date=new Date();
SimpleDateFormat dateFormat=new SimpleDateFormat("yyyy-MM-dd");
data.setDate(dateFormat.format(date));
data.setTimestamp(date.getTime());
/*UUID uuid = UUID.randomUUID();
data.setUuid(uuid);*/
int uid=random.nextInt(1000);
String uuid="10"+uid;
data.setUuid(uuid);
String[] port={"www.baidu.com", "www.taobao.com", "www.dangdang.com", "www.jd.com", "www.suning.com", "www.mi.com", "www.gome.com.cn"};
int pn=random.nextInt(port.length);
data.setPort(port[pn]);
String[] method={"Regist", "Comment", "View", "Login", "Buy", "Click", "Logout"};
int mn=random.nextInt(method.length);
data.setMethod(method[mn]);
datas.add(data);
}
write(datas);
}
public static void write(List<data>datas){
StringBuffer sb=new StringBuffer();
for (data c:datas){
sb.append(c.getIp()+" "+c.getAddress()+" "+c.getDate()+" "+c.getTimestamp()+" "+c.getUuid()+" "+c.getPort()+" "+c.getMethod()+" ");
}
File file=new File("E:/newdata.txt");
FileOutputStream fos=null;
OutputStreamWriter osw=null;
BufferedWriter bw=null;
try {
file.createNewFile();
fos=new FileOutputStream(file);
osw=new OutputStreamWriter(fos,"utf-8");
bw=new BufferedWriter(osw);
bw.write(sb.toString());
} catch (Exception e) {
e.printStackTrace();
}finally {
if(bw!=null){
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(osw!=null){
try {
osw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fos!=null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
需要完成任务
1.pv pageview 得出每个网站总的访问量
2.uv unique vistor 得出每个网站不同ip的访问量
3.每个网址 访问量top3地区 和对应的人数
www.baidu.com 北京 2000
河北 1800
辽宁 1000
www.taobao.com....
java测试spark环境所需pom文件,以及建立工程项目参考
object test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//设置应用名称
conf.setAppName("word_count")
//设置Spark运行的模式
conf.setMaster("local")
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("E:/newdata.txt")
//第一题
/*val rdd2=rdd1.map(line=>{
(line.split(" ")(5),1)
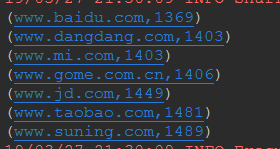
}).reduceByKey(_+_).sortBy(_._2,true).foreach(println)*/
/*解释:文件内容读取到rdd后,通过map以 分割取第六个数据(即网站(按行读取进行map运算))以及进行1计数,之后通过key进行
累加计算,最后通过sortby即value值即运算结果值,大小排序,输出
如图*/
//第二题
/*val rdd2 = rdd1.map(line => {
(line.split(" ")(5), line.split(" ")(0))
}).distinct().countByKey().foreach(println)*/
/*第二题是通过map划分为(String,String)格式的,然后去重相同的,即去掉ip重复的,通过key值即网站进行计数,最后输出
*/
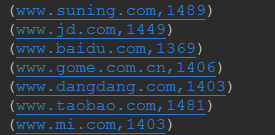
数据的不完整性,和第一题不产生区别,此时将以下两个数据ip和网站设置为相同

改为

此时预计结果为,www.mi.com结果会少一个
//第三题
rdd1.map(line=>{
((line.split(" ")(5),line.split(" ")(1)),line.split(" ")(0))
}).distinct().countByKey().groupBy(_._1._1).map(one=>{
one._2.toSeq.sortBy(_._2).takeRight(3)
}).foreach(println)
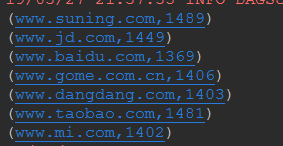
/*大致和以上两个一样,不同的是通过map取值时是((String,String),String)格式,去重后计数,再通过groupby排序
由于是按照第一个数的第一个值排序,groupby后格式为

如上图格式,因此再通过map,取其中的第二个值(即把全部提前,因为提取键做第一个,整体做第二个部分),进行toseq或者toList
否则无法sortby,最后通过takeright取倒数三个(因为排序为默认从小到大排序)(take取前n个,drop去掉前n个,first取第一个)
*/

val inputFile = "hdfs://master:9000/home/hadoop/hadoop_home/datas/pvuvdata"
rdd1.map(line=>{
((line.split(" ")(5),line.split(" ")(1)),line.split(" ")(0))
}).distinct().countByKey().groupBy(_._1._1).map(one=>{
one._2.toSeq.sortBy(_._2).takeRight(3)
}).toList.saveAsTextFile("hdfs://master:9000/home/hadoop/hadoop_home/PvUv")
//上面会报错,通过名字.var回车,勾选,table确定,查看类型应该是countByKey后,已经不是RDD类型
//才不能使用saveAsTextFile操作,用下面这种方法可以
rdd1.map(three => (three.split(" ")(5) + "_" + three.split(" ")(1), three.split(" ")(4))).distinct()
.map(two => ((two._1.split("_")(0), two._1.split("_")(1)), 1)).reduceByKey(_ + _)
.groupBy(_._1._1).map(_._2.toList.sortBy(_._2).reverse.take(3))
.saveAsTextFile("hdfs://master:9000/home/hadoop/hadoop_home/PvUv")
//output文件夹,要不存在,input文件夹放内容,才能在集群跑(打包文件参考idea打包)
//集群运行代码
//spark-master --master spark://master:7077 --class com.yjsj.spark.test MySpark.jar
//即要指定哪个包路径下面的哪个类,以及打包的jar包名,放在本地执行即可(这是在jar包上传到虚拟机上的路径位置处执行的,已经执行过格式化,参考打包文件执行)
//运行结果在master:8080端口查看spark执行结果日志,最终生成文件路径在hadoop集群上
sc.stop();
}
}
若是放在集群上运行,以及另一种方法
package com.yjsj.spark.day_3
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
object PvUvTest {
def main(args: Array[String]): Unit = {
//spark-submit --master spark://marter:7077 --class com.yjsj.spark.day_3.PvUvTest MySpark.jar
val inputFile = "hdfs://master:9000/home/hadoop/hadoop_home/datas/pvuvdata"
val conf = new SparkConf().setAppName("PvUvCount").setMaster("spark://master:7077")
val sc = new SparkContext(conf)
val lines = sc.textFile(inputFile)
/*
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("test")
val sc = new SparkContext(conf)
val lines = sc.textFile("./data/pvuvdata")
*/
//1
/*
val value: RDD[String] = lines.map(line => {line.split(" ")(5)})
val value1: RDD[(String, Int)] = value.map(one =>(one,1))
val value2: RDD[(String, Int)] = value1.reduceByKey(_+_)
value2.sortBy(_._2,false).foreach(println)
*/
lines.map(line => {line.split(" ")(5)}).map(one =>(one,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile("hdfs://master:9000/home/hadoop/hadoop_home/PvUv")
/*
val stringToLong: collection.Map[String, Long] = value.countByValue()
//jd.com 100000
//taobao.com 300000
stringToLong.toVector.sortBy(_._2).foreach(println)
//countByValue().toSeq.sortBy(_._2).foreach(println)
*/
//2
//lines.map(line => {line.split(" ")(0) + "_" + line.split(" ")(5)}).distinct().map(one =>{(one.split("_")(1), 1)}).reduceByKey(_+_).sortBy(_._2,false).foreach(println)
/*
//3
val web_province: RDD[(String, String)] = lines.map(line => {(line.split(" ")(5),line.split(" ")(1))})
val web_province_it: RDD[(String, Iterable[String])] = web_province.groupByKey()
val last_result = web_province_it.map(one =>{
val localMap = mutable.Map[String, Int]()
val strWeb = one._1
while(one._2.iterator.hasNext){
val local = one._2.iterator.next()
if (localMap.contains(local)){
val value = localMap.get(local).get
localMap.put(local,value+1)
}else{
localMap.put(local,1)
}
}
val tuples: List[(String, Int)] = localMap.toList.sortBy(_._2)
if(tuples.size>3){
val returnList = new ListBuffer[(String, Int)]()
for(i <- 0 to 2){
returnList.append(tuples(i))
}
(strWeb, returnList)
}else{
(strWeb, tuples)
}
})
//last_result.foreach(println)
last_result.saveAsTextFile("hdfs://master:9000/home/hadoop/hadoop_home/PvUv")
*/
sc.stop()
}
}