初次学习scrapy ,觉得spider代码才是最重要的,越往后学,发现pipeline中的代码也很有趣,
今天顺便把pipeline中三种储存方法写下来,算是对自己学习的一点鼓励吧,也可以为后来者的学习提供
绵薄之力,写的不怎么好,谅解
爬虫7部曲,虽然我不知道其他人是规划的
1.创建工程
scrapy startproject xiaohuawang
2.进入xiaohuawang目录 ,命名爬虫名和爬取的域名
cd xiaohuawang
scrapy genspider xhwang
此时在能看到如下结构
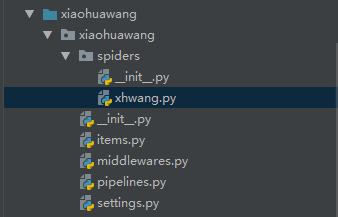
文件说明:
scrapy.cfg 项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中。
items.py 设置数据存储模板,用于结构化数据,
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等。
spiders 爬虫目录,如:创建文件,编写爬虫规则
xhwang.py 爬虫主要代码
包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容,提取生成 item 的方法。
为了创建一个Spider,必须继承 scrapy.Spider 类,且定义以下三个属性:
name:用于区别Spider。该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
start_urls:包含了Spider在启动时进行爬取的url列表。因此,第一个被获取到的页面将是其中之一。
后续的URL则从初始的URL获取到的数据中提取。
该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request 对象。
注意:一般创建爬虫文件时,以网站域名命名
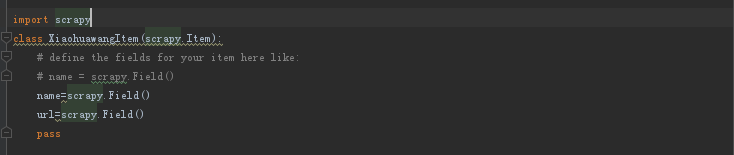
3、编写item (数据模板) 这里只编写两项
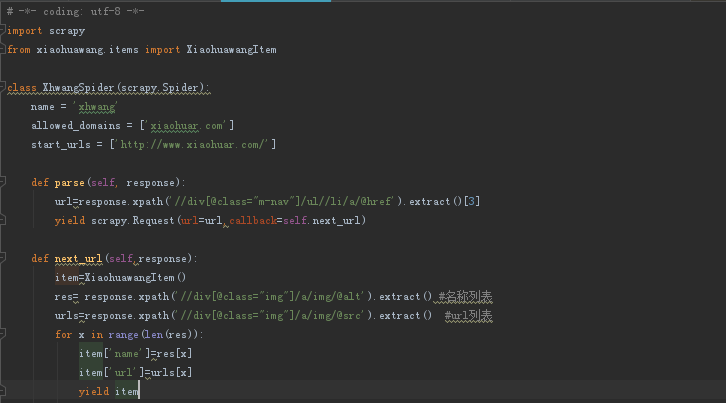
4、编写爬虫,爬虫主体代码还是挺容易理解的
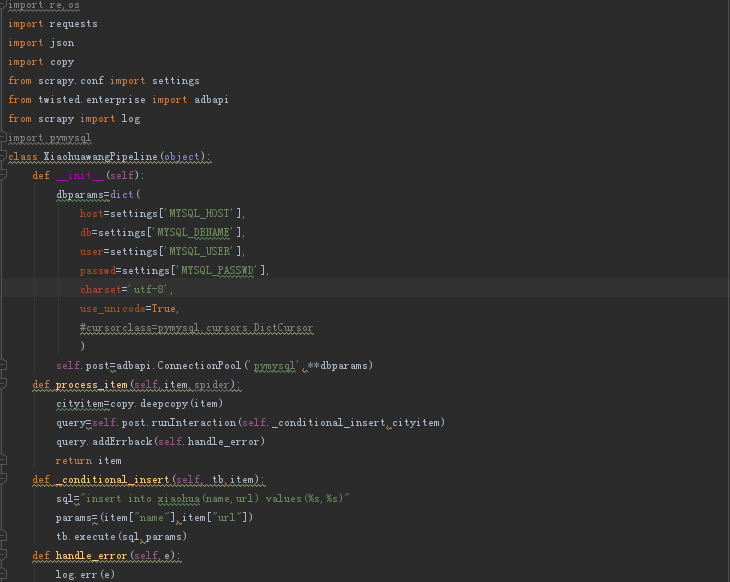
5、编写pipeline(重点)此处编写了三种 (保存到mysql 、保存到json文件、以及将图片存储到本)
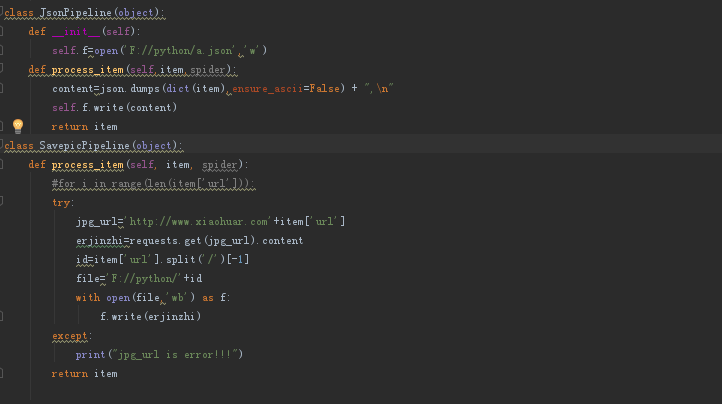
6、settings设置,为了使三种pipeline均生效需要设置如下 数字越小优先级越高

7、运行scrapy crawl xhwang