在机器学习领域,特别是涉及到模型的调参与优化部分,k折交叉验证是一个经常使用到的方法,本文就结合示例对它做一个简要介绍。
该方法的基本思想就是将原训练数据分为两个互补的子集,一部分做为训练数据来训练模型,另一部分做为验证数据来评价模型。(以下将前述的两个子集的并集称为原训练集,将它的两个互补子集分别称为训练集和验证集;此处要区别验证集与测试集,验证集是原训练集的一个子集,而测试集相对于原训练集而言。)
图示如下:

k折,就是将原训练集分为k份,其中k-1份作训练集,另一份作验证集。
k折交叉验证的基本思路如下:
第一步,不重复地将原训练集随机分为 k 份;
第二步,挑选其中 1 份作为验证集,剩余 k-1 份作为训练集用于模型训练,在训练集上训练后得到一个模型,用这个模型在验证集上测试,保存模型的评估指标;
第三步,重复第二步 k 次(确保每个子集都有一次机会作为验证集);
第四步,计算 k 组测试指标的平均值作为模型精度的估计,并作为当前 k 折交叉验证下模型的性能指标。
通常情况下,k一般取10;当原训练集较小时,k可以大一点,这样训练集占整体比例就不至于太小,但训练的模型个数也随之增多;原训练集较大时,k可以小一点。
1 使用k折交叉验证反映模型平均性能
为了贴近实用,下面以一个鸢尾花分类的例子具体说明该验证方法的细节:

上图是在没有使用k折交叉验证的情况下,一个模型初次训练之后的准确率,并不能代表模型的平均性能。
使用了k折交叉验证方法后,准确率情况如下,大致可以反映该模型的平均水平:
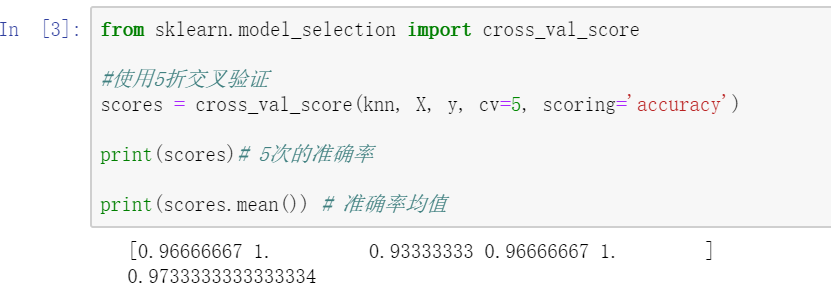
2 借助k折交叉验证调整模型超参数
当所需训练的模型需要调节超参数时,可以在多个不同的超参数下用训练集训练多个模型,选择在验证集上有最佳性能的超参数值,最后用测试集做一次测试,以得到推广误差率的预估。
为了避免浪费过多训练数据在验证集上,交叉验证便是常用方法:训练集分成互补的子集,每个模型用不同的训练子集训练,再用剩下的验证子集验证。一旦确定模型类型和超参数,最终的模型使用这些超参数在全部的训练集(即上文所述的原训练集)上进行训练,用测试集得到推广误差率。
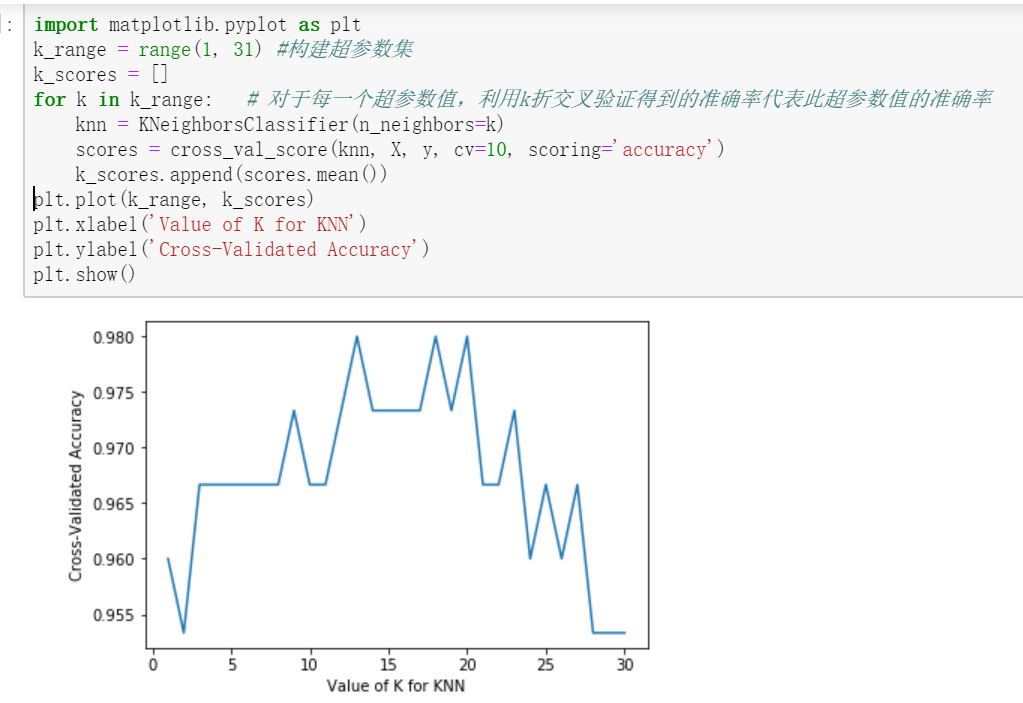
从上图中可以知,对于每一个超参数值,选用10折交叉验证,选择12~18的超参数值最好,大于18之后,准确率开始下降(过拟合)。
注意:此处的准确率是在验证集上的准确率;在细节处理上,由于模型较小,针对每一个超参数,准确率是在10个(因为是10折交叉验证)验证集上的平均准确率。