python对于string的截取是 str[start,end]
一 string类型的字符串拼接
先查看英文,可以看到他们截取是正确的。
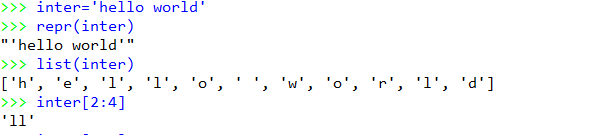
inter='hello world'
repr(inter)
list(inter)
inter[2:4]
当存在中文字符时,却不能正确解析了,

zw='静夜思abc d'
repr(zw)
list(zw)
zw[2:5]#截取字符串
zw[1:4]
查看一下控制台的编码格式,可以看到是utf-8编码。当然,str还可以用其他编码。
import charade
det=charade.detect(zw)
print det
{'confidence': 0.87625, 'encoding': 'utf-8'}
页面是用utf-8编码的。
解决方法,使用unicode进行编码。下面看看他们之间的区别
二 unicode类型的字符串拼接
当为英文时,区别不大
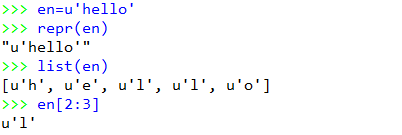
en=u'hello'
repr(en)
list(en)
en[2:3]
中文夹杂英文时,能查看出,list是按字拆分的

zw=u'静夜思ab d'
repr(zw)
list(zw)
zw[2:3]
由此可以看出转换为unicode进行截取正确,但在跟其他字符进行拼接时,需要注意字符串类型问题,str+unicode会报错~