转自:https://www.cnblogs.com/chaojiyingxiong/p/9822444.html
前言:
我们知道,计算机是以二进制为单位的,也就是说计算机只识别0和1,也就是我们平时在电脑上看到的文字,只有先变成0和1,计算机才会识别它的意思。这种数据和二进制的转换规则就是编码。计算机的发展中,有ASCII码,GBK,Unicode,utf-8编码。我们先从编码的发展史了解一下编码的进化过程。
一、编码发展史
- 美国人发明了计算机,用八位0和1的组合,一一对应英文中的字符,整出了一个表格,ASCII表。
- 计算机传入中国,中国地大物博,繁体字和简体字多,8位字节最多表示256个字符,满足不了,于是对ASCII扩展,新表叫GB2312
- 后来发现GB2312还不够用,扩充之后形成GB18030。
- 每个国家都像中国一样,把自己的语言编码,于是出现了各种各样的编码,如果你不安装相应的编码,就无法解释相应编码想表达的内容。
- 各自编码无法国际交流。一个国际组织一起创造了一种编码 UNICODE(Universal Multiple-Octet Coded Character Set)规定所有字符用两个字节表示,就是固定的,所有的字符就两个字节,计算机容易识别。2的16次方可以表示所有的字符了。
- UNICODE虽然解决了各自为战的问题,但是美国人不愿意了,因为美国原来的ASCII只需要一个字节就可以了。UNICODE编码却让他们的语言多了一个字节,白白浪费一个字节的存储空间。经过协商,出现了一种新的转换格式,被称为通用转换格式,也就是UTF(unicode transformation format).常见的有utf-8,utf-16。utf-8规定,先分类,美国字符一个字节,欧洲两个字符,东南亚三个字符。
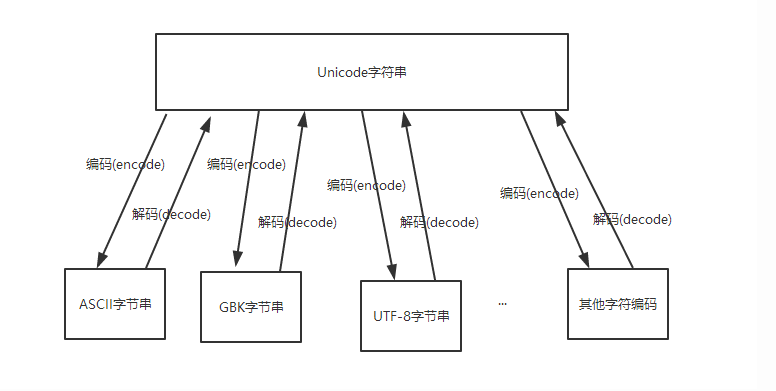
二、encode()和decode()
- decode英文意思是 解码,encode英文原意 编码
- 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码, 即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
- decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
- encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
- UTF-8 是 Unicode 的实现方式之一
- 总得意思:想要将其他的编码转换成utf-8必须先将其解码成unicode然后重新编码成utf-8,它是以unicode为转换媒介的 如:s='中文' 如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用 decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件