本文的主要目的是记住最主要的函数,具体的用法还得查API文档。
首先导入包:
1 %matplotlib inline
2 import numpy as np
3 import pandas as pd
4 from scipy import stats, integrate
5 import matplotlib.pyplot as plt
6 import seaborn as sns
7 sns.set(color_codes=True)
8 np.random.seed(sum(map(ord, "distributions")))
9 # 生产参数
几种重要的可视化图形:
灰度图
x = np.random.normal(size=100)
sns.distplot(x, kde=True)
最重要的是 sns.distplot()
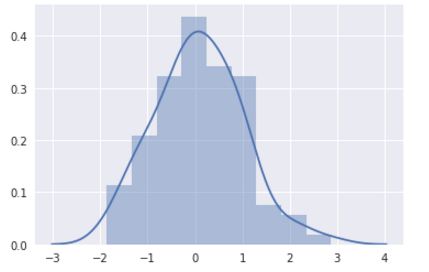
核密度估计
核密度估计的步骤:
- 每一个观测附近用一个正态分布曲线近似
- 叠加所有观测的正太分布曲线
- 归一化
sns.kdeplot(x)
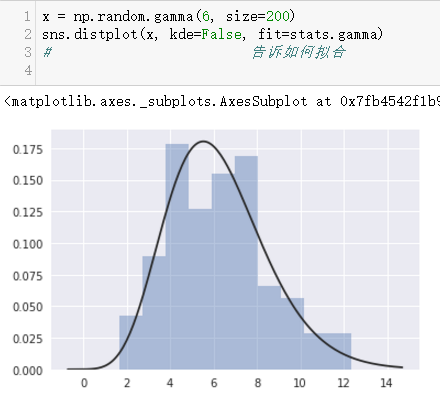
模型参数拟合
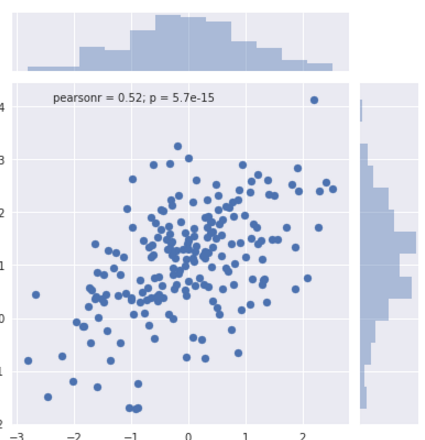
双变量分布
两个相关的变量
散点图
sns.jointplot( )
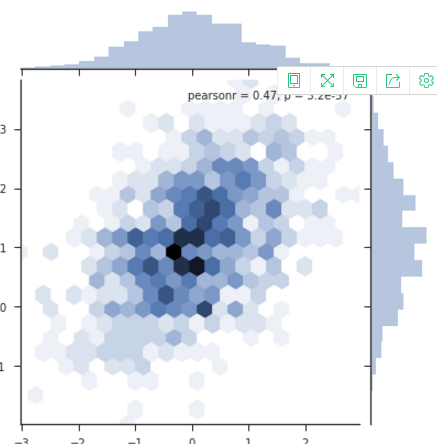
六角箱图
sns.jointplot( )
核密度估计
sns.jointplot(......., kind="kde") 重要的是后面的那个参数
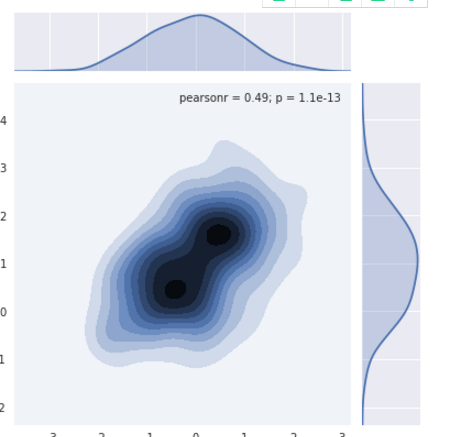
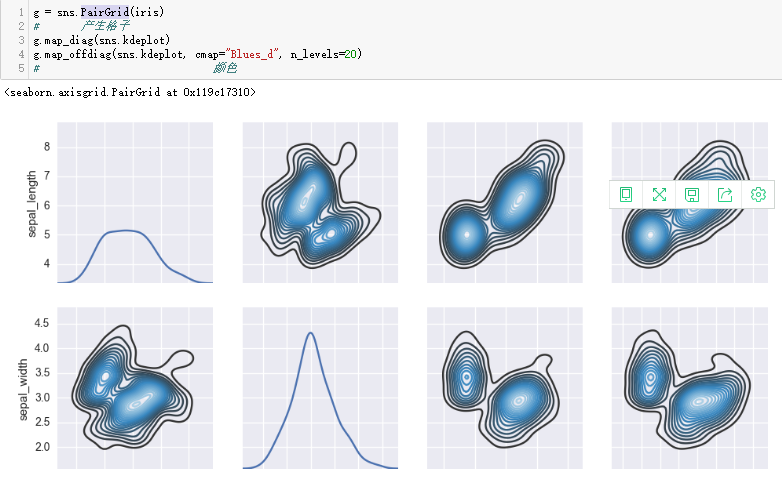
这个图,着实有点难啊
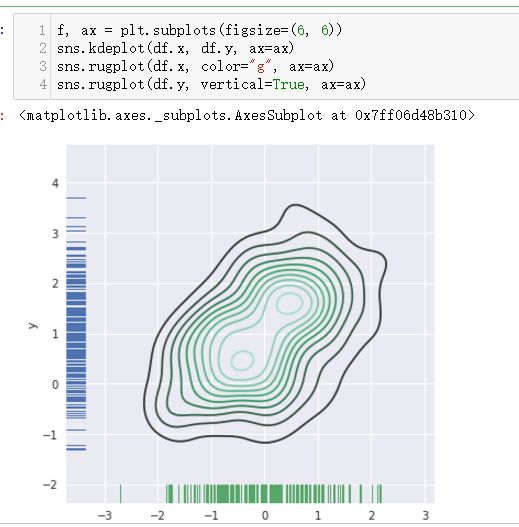
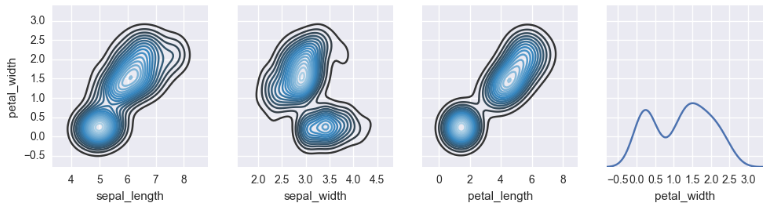
也不知道这个是啥
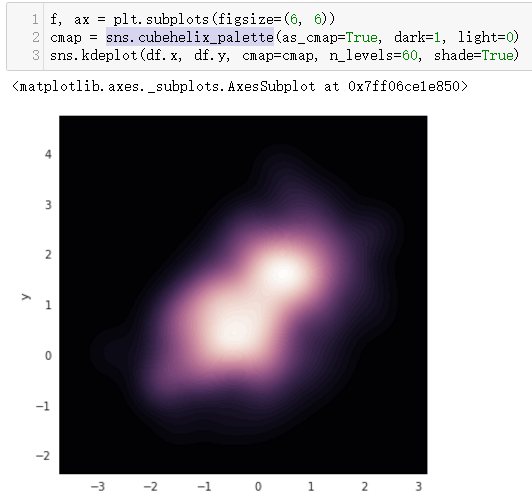
还有这个,
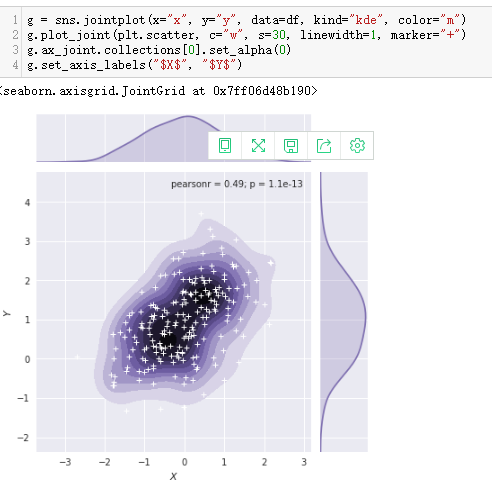
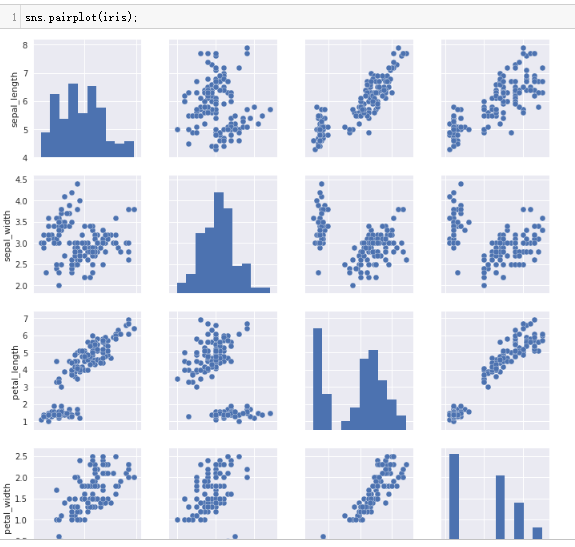
数据集中的两两关系
iris = sns.load_dataset("iris")