Linux文件系统结构
在Linux底下,所有的文件与目录都是由根目录开始,是目录与文件的源头,然后一个个的分支下来,如同树枝状,因此称为这种目录配置为:目录树。
目录树的特点是什么呢?
- 目录树的起始点是根目录(/,root);
- 每一个目录不止能使用本地的文件系统,也可以使用网络上的文件系统,可以利用NFS服务器挂载特定目录。
- 每一个文件在此目录树中的文件名,包含完整路径都是独一无二的。
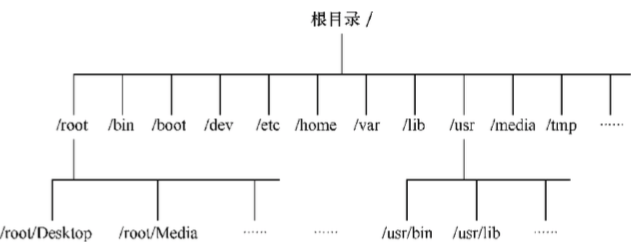
以下是对这些目录的解释:

目录的相关操作
. 当前目录 .. 上一层目录 - 前一个工作目录 ~ 当前【用户】所在的家目录 命令: ls -la / 查看命令解释:man ls (Linux下的帮助指令) 结论:ls - list directory contens (列出目录内容) ls -la / 以竖状格式化显示列出/目录所有内容 cd : (change directory,更改目录) pwd:(显示当前目录) mkdir:(建立一个新目录) rmdir:(删除一个空目录)
touch xxx.py 创建文件 cd 目录名 变换目录 mkdir 文件名 建立新目录 rmdir 文件夹名 删除空目录 echo $PATH 查看环境变量,cho命令是有打印的意思,$符号后面跟上PATH,表示输出PATH的变量 cd /var/log (绝对路径) cd ../var/log(相对路径) cat 文件路径或文件名 查看文件内容
Shell基本命令


显示文件或文件系统的状态。 #用法 stat [参数] 文件 参数列表: -L, --dereference 跟随链接 -f, --file-system 显示文件系统状态而非文件状态 -c --format=格式 使用指定输出格式代替默认值,每用一次指定格式换一新行 --printf=格式 类似 --format,但是会解释反斜杠转义符,不使用换行作 输出结尾。如果您仍希望使用换行,可以在格式中 加入" " -t, --terse 使用简洁格式输出 --help 显示此帮助信息并退出 --version 显示版本信息并退出 格式化输出参数: %a 八进制权限 %A 用可读性较好的方式输出权限
#方法,命令 vi vim 使用vi打开oldboy.py,默认是命令模式,需要输入a/i进入编辑模式,然后输入文本"Life is short,i use python" 按下esc键,回到命令模式 输入 :wq! 强制保存退出 w write 写入 q quit 退出 ! 强制 或者 :x 保存退出 ------ :q 不保存退出 :q! 不保存强制退出 移动光标===================== w(e) 移动光标到下一个单词 b 移动到光标上一个单词 数字0 移动到本行开头 $ 移动光标到本行结尾 H 移动光标到屏幕首行 M 移动到光标到屏幕的中间一行 L 移动光标到屏幕的尾行 gg 移动光标到文档的首行 G 移动光标到文档尾行 ctrl + f 下一页 ctrl + b 上一页 `. 移动光标到上一次的修改行 查找========================= /chaoge 在整篇文档中搜索chaoge字符串,向下查找 ?chaoge 在整篇文档中搜索chaoge字符串,向上查找 * 查找整个文档,匹配光标所在的所有单词,按下n查找下一处,N上一处 # 查找整个文档,匹配光标所在的所有单词,按下n查找下一处,N上一处 gd 找到光标所在单词匹配的单词,并停留在非注释的第一个匹配上 % 找到括号的另一半!! 复制,删除,粘贴======================== yy 拷贝光标所在行 dd 删除光标所在行 D 删除当前光标到行尾的内容 dG 删除当前行到文档尾部的内容 p 粘贴yy所复制的内容 x 删除光标所在的字符 u 撤销上一步的操作 数字命名========================= 3yy 拷贝光标所在的3行 5dd 删除光标所在5行
1.more命令用于查看内容较多的文本,例如要看一个很长的配置文件,cat查看内容屏幕会快速翻滚到结尾。 2.more命令查看文本会以百分比形式告知已经看到了多少,使用回车键向下读取内容 more /etc/passwd 按下空格space是翻页 按下b键是上一页 回车键向下读取内容
1.tab键 用于自动补全命令/文件名/目录名 2.ctrl + l 清理终端显示 3.clear/cls 清理终端显示 4.ctrl + c 终止当前操作
#默认吧内容显示到终端上 echo "python" #打印 python字符串 echo "python" > /tmp/py.txt #将python 写入到py.txt中 echo $PATH #取出打印PATH的值
输入/输出 重定向符号 1.>> 追加重定向,把文字追加到文件的结尾 2.> 重定向符号,清空原文件所有内容,然后把文字覆盖到文件末尾 3.< 输入重定向 4.<< 将输入结果输入重定向 通配符 ls -l /etc/us*
复制 > copy > cp #移动xxx.py到/tmp目录下 cp xxx.py /tmp/ #移动xxx.py顺便改名为chaoge.py cp xxx.py /tmp/chaoge.py Linux下面很多命令,一般没有办法直接处理文件夹,因此需要加上(参数) cp -r 递归,复制目录以及目录的子孙后代 cp -p 复制文件,同时保持文件属性不变 可以用stat cp -a 相当于-pdr #递归复制test文件夹,为test2 cp -r test test2 cp是个好命令,操作文件前,先备份 cp main.py main.py.bak
移动(搬家)命令 > move > mv cd /home mv 文件a路径 文件b路径 (将文件a移动到文件b处) 文件/文件夹改名 mv x.log xx.log
删除 > remove > rm 参数 -i 需要删除确认 -f 强制删除 -r 递归删除目录和内容 #默认有提示删除,需要输入y rm -f boy.py #不需要提示,强制删除 #rm默认无法删除目录,需要跟上参数-r rm -rf /tmp/boy/ -------- 友情提醒:初学者使用rm命令,随时快照虚拟机
#Linux里如何找到需要的文件 例如 boy.py find 在哪里(目录) 什么类型(文件类型) 叫什么名字(文件名) 参数 -name 按照文件名查找文件 -type 查找某一类型的文件,诸如: b - 块设备文件。 d - 目录。 c - 字符设备文件。 p - 管道文件。 l - 符号链接文件。 f - 普通文件。 s - socket文件 find /tmp/ -type f -name "boy.py" #找出/tmp所有以 .txt 结尾的文件 find /tmp/ -type f -name "*.txt" #找到/etc下所有名字以host开头的文件 find /etc -name 'host*' #找到/opt上一个名为settings.py find /opt -name 'settings.py'
Linux提供的管道符“|”讲两条命令隔开,管道符左边命令的输出会作为管道符右边命令的输入。 常见用法: #检查python程序是否启动 ps -ef|grep "python" #找到/tmp目录下所有txt文件 ls /tmp|grep '.txt' #检查nginx的端口是否存活 netstat -tunlp |grep nginx
grep 语法: grep [参数] [--color=auto] [字符串] filename 参数详解: -i : 忽略大小写 -n : 输出行号 -v : 反向选择 --color = auto : 给关键词部分添加颜色 grep "我要找什么" #排除 -v,排除我要找的东西 grep -v "我要找什么
head显示文件前几行,默认前10行 tail显示文件后几行,默认后10行 #查看前两行 head -2 /tmp/oldboy.txt #查看后两行 tail -2 /tmp/oldboy.txt #持续刷新显示 tail -f xx.log #显示文件10-30行 head -30 /tmp/boy.txt |tail -21
sed sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。 命令格式 sed [options] 'command' file(s) sed [options] -f scriptfile file(s) 选项 -e<script>或--expression=<script>:以选项中的指定的script来处理输入的文本文件; -f<script文件>或--file=<script文件>:以选项中指定的script文件来处理输入的文本文件; -h或--help:显示帮助; -n或--quiet或——silent:仅显示script处理后的结果; -V或--version:显示版本信息。 -i ∶插入, i 的后面可以接字串 sed命令 a 在当前行下面插入文本。 i 在当前行上面插入文本。 c 把选定的行改为新的文本。 d 删除,删除选择的行。 D 删除模板块的第一行。 s 替换指定字符 h 拷贝模板块的内容到内存中的缓冲区。 H 追加模板块的内容到内存中的缓冲区。 g 获得内存缓冲区的内容,并替代当前模板块中的文本。 G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 l 列表不能打印字符的清单。 n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。 N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。 p 打印模板块的行。 P(大写) 打印模板块的第一行。 q 退出Sed。 b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。 r file 从file中读行。 t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 w file 写并追加模板块到file末尾。 W file 写并追加模板块的第一行到file末尾。 ! 表示后面的命令对所有没有被选定的行发生作用。 = 打印当前行号码。 # 把注释扩展到下一个换行符以前。 sed替换标记 g 表示行内全面替换。 p 表示打印行。 w 表示把行写入一个文件。 x 表示互换模板块中的文本和缓冲区中的文本。 y 表示把一个字符翻译为另外的字符(但是不用于正则表达式) 1 子串匹配标记 & 已匹配字符串标记 sed元字符集 ^ 匹配行开始,如:/^sed/匹配所有以sed开头的行。 $ 匹配行结束,如:/sed$/匹配所有以sed结尾的行。 . 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。 * 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。 [] 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed。 [^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。 (..) 匹配子串,保存匹配的字符,如s/(love)able/1rs,loveable被替换成lovers。 & 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。 < 匹配单词的开始,如:/<love/匹配包含以love开头的单词的行。 > 匹配单词的结束,如/love>/匹配包含以love结尾的单词的行。 x{m} 重复字符x,m次,如:/0{5}/匹配包含5个0的行。 x{m,} 重复字符x,至少m次,如:/0{5,}/匹配至少有5个0的行。 x{m,n} 重复字符x,至少m次,不多于n次,如:/0{5,10}/匹配5~10个0的行。 sed实际用例 #替换oldboy.txt中所有的oldboy变为oldboy_python #此时结果输出到屏幕,不会写入到文件 sed 's/oldboy/oldboy_python/' /tmp/oldboy.txt #使用选项-i,匹配每一行第一个oldboy替换为oldboy_python,并写入文件 sed -i 's/oldboy/oldboy_python/' /tmp/oldboy.txt #使用替换标记g,同样可以替换所有的匹配 sed -i 's/book/books/g' /tmp/oldboy.txt #删除文件第二行 sed -i '2d' /tmp/oldboy.txt #删除空白行 sed -i '/^$/d' /tmop/oldboy.txt #删除文件第二行,到末尾所有行 sed '2,$d' /tmp/oldboy.txt #显示10-30行 -p --print -n --取消默认输出 sed -n '10,30p' /tmp/oldboy.txt sed
alias rm='rm -i' 当你输入rm的时候,就是输入了 rm -i 取消别名 unalias
which命令用于查找并显示给定命令的绝对路径,环境变量PATH中保存了查找命令时需要遍历的目录。 which指令会在环境变量$PATH设置的目录里查找符合条件的文件。 也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。 which pwd which python which python #python命令在哪
scp 【可选参数】 本地源文件 远程文件标记 -r :递归复制整个目录 -v:详细方式输出 -q:不显示传输进度条 -C:允许压缩 #传输本地文件到远程地址 scp 本地文件 远程用户名@远程ip:远程文件夹/ scp 本地文件 远程用户名@远程ip:远程文件夹/远程文件名 scp /tmp/chaoge.py root@192.168.1.155:/home/ scp /tmp/chaoge.py root@192.168.1.155:/home/chaoge_python.py scp -r 本地文件夹 远程用户名@远程ip:远程文件夹/ scp -r /tmp/oldboy root@192.168.1.155:/home/oldboy #复制远程文件到本地 scp root@192.168.1.155:/home/oldboy.txt /tmp/oldboy.txt scp -r root@192.168.1.155:/home/oldboy /home/
Linux du命令用于显示目录或文件的大小。 du会显示指定的目录或文件所占用的磁盘空间。 用法 du 【参数】【文件或目录】 -s 显示总计 -h 以k,M,G为单位显示,可读性强
top 命令用于动态地监视进程活动与系统负载等信息 第一行 (uptime) 系统时间 主机运行时间 用户连接数(who) 系统1,5,15分钟的平均负载 第二行:进程信息 进程总数 正在运行的进程数 睡眠的进程数 停止的进程数 僵尸进程数 第三行:cpu信息 1.5 us:用户空间所占CPU百分比 0.9 sy:内核空间占用CPU百分比 0.0 ni:用户进程空间内改变过优先级的进程占用CPU百分比 97.5 id:空闲CPU百分比 0.2 wa:等待输入输出的CPU时间百分比 0.0 hi:硬件CPU中断占用百分比 0.0 si:软中断占用百分比 0.0 st:虚拟机占用百分比 第四行:内存信息(与第五行的信息类似与free命令) total:物理内存总量 used:已使用的内存总量 free:空闲的内存总量(free+used=total) buffers:用作内核缓存的内存量 第五行:swap信息 total:交换分区总量 used:已使用的交换分区总量 free:空闲交换区总量 cached Mem:缓冲的交换区总量,内存中的内容被换出到交换区,然后又被换入到内存,但是使用过的交换区没有被覆盖,交换区的这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入。
给文件加锁,只能写入数据,无法删除文件 chattr +a test.py chattr -a test.py
查看文件隐藏属性
lsattr test.py
-d --date=string 显示指定的时间,而不是当前时间 以年-月-日显示当前时间 date +"%Y-%m-%d" 以年-月-日 时分秒 显示当前时间 date +"%Y-%m-%d %T"
wget命令用于在终端下载网络文件
参数是 wget [参数] 下载地址
reboot命令用于重启机器
poweroff用于关闭系统
网卡配置
linux安装好了之后,如何初始化服务器
防火墙1:iptables 第三方
防火墙2: selinux 系统自带的
1.关闭linux的防火墙(就是一堆安全机制的规则, 如同保安的贴墙上的那些规则,共享单车禁止入内)
因为后期我们去学习软件,学习nginx mysql redis ,为了学习的方便,关闭防火墙,允许所有的端口可以访问
iptables -F 清空防火墙规则
centos7默认已经使用firewall作为防火墙了 1.关闭防火墙 systemctl status firewalld #查看防火墙状态 systemctl stop firewalld #关闭防火墙 systemctl disable firewalld#关闭防火墙开机启动
systemctl is-enabled firewalld.service#检查防火墙是否启动
2.关闭selinux ,此步骤,需要重启linux方可生效
vi /etc/selinux/config 找到 SELINUX=enforcing这一行 改成 SELINUX=disabled
配置linux的ip地址的方法
1.选择上网的方式,可以选择2种,桥接,nat
2.选择了上网模式之后,可以通过命令管理网卡服务
systemctl stop network 停止网络服务
systemctl start network 开启网络服务
选择了上网模式之后,可以通过命令管理网卡服务
1.进入网卡的工作目录
cd /etc/sysconfig/network-scripts/
2.查看网卡配置文件
vi ifcfg-ens33 找到ONBOOT=no这一行 ONBOOT=yes 使得下次开启机器,自动加载网络服务
权限
id指令查看用户所属群主 [root@oldboy_python ~ 16:34:52]#id root uid=0(root) gid=0(root) 组=0(root)
普通用户只能修改自己的文件名,时间与权限(注意) 因此修改其他用户权限,只能用最nb的root用户 chown root pyyu.txt 修改属主为root chgrp root pyyu.txt 修改属组 我们已知三种身份权限(属主,属组,其他人),每种身份都有rwx的三种权限,系统还提供了数字计算权限。 r read 4 w write 2 x execute 1 每种身份最低是0分,最高是r+w+x 7分 因此三种身份,最高权限是777,最低是000 -rw-rw-r-- 1 root root 0 8月 11 16:41 pyyu.txt 因此可知pyyu.txt的权限是 属主是6 r+w(4+2) 属组是6 r+w(4+2) 其他人是4 r(4)
chmod [身份] [参数] [文件] u(user) +(添加) g(group) -(减去) o(other) =(赋值) a(all) 减去属主的写权限 chmod u-w pyyu.txt
软连接
软连接也叫做符号链接,类似于windows的快捷方式。
常用于安装软件的快捷方式配置,如python,nginx等
ln -s 目标文件 软连接名 1.存在文件/tmp/test.txt [root@master tmp]# ls -l -rw-r--r-- 1 root root 10 10月 15 21:23 test.txt 2.在/home目录中建立软连接,指向/tmp/test.txt文件 ln -s /tmp/test.txt my_test 3.查看软连接信息 lrwxrwxrwx 1 root root 13 10月 15 21:35 my_test -> /tmp/test.txt 4.通过软连接查看文件 cat my_test my_test只是/tmp/test.txt的一个别名,因此删除my_test不会影响/tmp/test.txt,但是删除了本尊, 快捷方式就无意义不存在了
PS1变量
echo $PS1 可以自行调整全局变量/etc/profile文件用于永久生效 PS1='[u@h W ]$' d 日期 H 完整主机名 h 主机名第一个名字 时间24小时制HHMMSS T 时间12小时制 A 时间24小时制HHMM u 当前用户账号名 v BASH的版本 w 完整工作目录 W 利用basename取得工作目录名 # 下达的第几个命令 $ 提示字符,root为#,普通用户为$ PS1 > 变量名 $PS1 > 查看变量内容 PS1=新内容 重新赋值 变量赋值,查看 name='chaoge' echo $name PS1显示ip地址 export PS1="[u@h `/sbin/ifconfig ens33 | sed -nr 's/.*inet (addr:)?(([0-9]*.){3}[0-9]*).*/2/p'` w]$"
tar解压命令
tar 命令:用来压缩和解压文件。tar本身不具有压缩功能。他是调用压缩功能实现的 tar(选项)(参数) -A或--catenate:新增文件到以存在的备份文件; -B:设置区块大小; -c或--create:建立新的备份文件; -C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。 -d:记录文件的差别; -x或--extract或--get:从备份文件中还原文件; -t或--list:列出备份文件的内容; -z或--gzip或--ungzip:通过gzip指令处理备份文件; -Z或--compress或--uncompress:通过compress指令处理备份文件; -f<备份文件>或--file=<备份文件>:指定备份文件; -v或--verbose:显示指令执行过程; -r:添加文件到已经压缩的文件; -u:添加改变了和现有的文件到已经存在的压缩文件; -j:支持bzip2解压文件; -v:显示操作过程; -l:文件系统边界设置; -k:保留原有文件不覆盖; -m:保留文件不被覆盖; -w:确认压缩文件的正确性; -p或--same-permissions:用原来的文件权限还原文件; -P或--absolute-names:文件名使用绝对名称,不移除文件名称前的“/”号; -N <日期格式> 或 --newer=<日期时间>:只将较指定日期更新的文件保存到备份文件里; --exclude=<范本样式>:排除符合范本样式的文件。
tar -zxvf Python-3.7.0b3.tgz #解压 tar -czvf oldboy.txt.tar.gz oldboy.txt #压缩oldboy.txt 上述命令等于 tar -cvf oldboy.tar oldboy.txt gzip oldboy.tar tar -cf all_pic.tar *.jpg #压缩当前目录所有jpg结尾的文件 tar -xjf xx.tar.bz2 #解压缩bz2结尾的文件
gzip命令
gzip用来压缩文件,是个使用广泛的压缩程序,被压缩的以".gz"扩展名 gzip可以压缩较大的文件,以60%~70%压缩率来节省磁盘空间
-d或--decompress或----uncompress:解开压缩文件; -f或——force:强行压缩文件。 -h或——help:在线帮助; -l或——list:列出压缩文件的相关信息; -L或——license:显示版本与版权信息; -r或——recursive:递归处理,将指定目录下的所有文件及子目录一并处理; -v或——verbose:显示指令执行过程;
netstat命令
netstat命令用来打印Linux中网络系统的状态信息,可让你得知整个Linux系统的网络情况。 netstat [选项] -t或--tcp:显示TCP传输协议的连线状况; -u或--udp:显示UDP传输协议的连线状况; -n或--numeric:直接使用ip地址,而不通过域名服务器; -l或--listening:显示监控中的服务器的Socket; -p或--programs:显示正在使用Socket的程序识别码和程序名称; -a或--all:显示所有连线中的Socket;
ps命令
ps 命令用于查看系统中的进程状态,格式为“ps [参数]”。 ps 命令常用参数 -a 显示所有进程 -u 用户以及其他详细信息 -x 显示没有控制终端的进程
kill 命令
kill命令用来删除执行中的程序或工作。kill可将指定的信息送至程序。 -a:当处理当前进程时,不限制命令名和进程号的对应关系; -l <信息编号>:若不加<信息编号>选项,则-l参数会列出全部的信息名称; -p:指定kill 命令只打印相关进程的进程号,而不发送任何信号; -s <信息名称或编号>:指定要送出的信息; -u:指定用户。
HUP 1 终端断线 INT 2 中断(同 Ctrl + C) QUIT 3 退出(同 Ctrl + ) TERM 15 终止 KILL 9 强制终止 CONT 18 继续(与STOP相反, fg/bg命令) STOP 19 暂停(同 Ctrl + Z)
通常来讲,复杂软件的服务程序会有多个进程协同为用户提供服务,如果逐个去结束这 些进程会比较麻烦,此时可以使用 killall 命令来批量结束某个服务程序带有的全部进程。
例如nginx启动后有2个进程
killall nginx
SELinux功能
SELinux(Security-Enhanced Linux) 是美国国家安全局(NSA)对于强制访问控制的实现,这个功能管理员又爱又恨,大多数生产环境也是关闭的做法,安全手段使用其他方法。
大多数ssh连接不上虚拟机,都是因为防火墙和selinux阻挡了
1.修改配置文件,永久生效关闭selinux cp /etc/selinux/config /etc/selinux/config.bak #修改前备份 2.修改方式可以vim编辑,找到 # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled 3.用sed替换 sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config 4.检查状态 grep "SELINUX=disabled" /etc/selinux/config #出现结果即表示修改成功
getenforce #获取selinux状态 #修改selinux状态 setenforce usage: setenforce [ Enforcing | Permissive | 1 | 0 ] 数字0 表示permissive,给出警告,不会阻止,等同disabled 数字1表示enforcing,表示开启
Linux中文显示设置(防止中文乱码)
此项优化为可选项,根据个人情况选择是否调整Linux系统的字符集,字符集就是一套文字符号以及编码。
Linux下常用字符集有:
- GBK 实际企业应用较少
- UTF-8 广泛支持,MYSQL也使用UTF-8,企业广泛使用
#查看系统当前字符集 echo $LANG #检查xshell crt的字符集 #命令修改字符集 export LANG=en_US.utf8 1.修改配置文件/etc/locale.conf LANG="zh_CN.UTF-8" 2.更改后查看系统语言变量 locale
df命令
df命令用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
语法 df(选项)(参数) -h或--human-readable:以可读性较高的方式来显示信息; -k或--kilobytes:指定区块大小为1024字节; -T或--print-type:显示文件系统的类型; --help:显示帮助; --version:显示版本信息。 查看系统磁盘设备,默认是KB为单位: df 使用-h选项以KB以上的单位来显示,可读性高: df -h
普通命令
tree命令以树状图列出目录的内容。 -a:显示所有文件和目录; -A:使用ASNI绘图字符显示树状图而非以ASCII字符组合; -C:在文件和目录清单加上色彩,便于区分各种类型; -d:先是目录名称而非内容; -D:列出文件或目录的更改时间; -f:在每个文件或目录之前,显示完整的相对路径名称; -F:在执行文件,目录,Socket,符号连接,管道名称名称,各自加上"*","/","@","|"号; -g:列出文件或目录的所属群组名称,没有对应的名称时,则显示群组识别码; -i:不以阶梯状列出文件和目录名称; -l:<范本样式> 不显示符号范本样式的文件或目录名称; -l:如遇到性质为符号连接的目录,直接列出该连接所指向的原始目录; -n:不在文件和目录清单加上色彩; -N:直接列出文件和目录名称,包括控制字符; -p:列出权限标示; -P:<范本样式> 只显示符合范本样式的文件和目录名称; -q:用“?”号取代控制字符,列出文件和目录名称; -s:列出文件和目录大小; -t:用文件和目录的更改时间排序; -u:列出文件或目录的拥有者名称,没有对应的名称时,则显示用户识别码; -x:将范围局限在现行的文件系统中,若指定目录下的某些子目录,其存放于另一个文件系统上,则将该目录予以排除在寻找范围外。 tree参数
[root@yugo /tmp 11:04:42]#hostnamectl set-hostname pyyuc [root@pyyuc ~ 11:05:12]#hostname pyyuc
DNS(Domain Name System,域名系统),万维网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。 通过域名,最终得到该域名对应的IP地址的过程叫做域名解析(或主机名解析)。 linux dns配置文件是 /etc/resolv.conf [root@s15fafafa home]# cat /etc/resolv.conf # Generated by NetworkManager nameserver 119.29.29.29 主dns nameserver 223.5.5.5 备dns /etc/hosts文件 本地dns强制解析的文件
nslookup命令是常用域名查询工具,就是查DNS信息用的命令。 nslookup4有两种工作模式,即“交互模式”和“非交互模式”。在“交互模式”下,用户可以向域名服务器查询各类主机、域名的信息,或者输出域名中的主机列表。而在“非交互模式”下,用户可以针对一个主机或域名仅仅获取特定的名称或所需信息。 进入交互模式,直接输入nslookup命令,不加任何参数,则直接进入交互模式,此时nslookup会连接到默认的域名服务器(即/etc/resolv.conf的第一个dns地址)。或者输入nslookup -nameserver/ip。进入非交互模式,就直接输入nslookup 域名就可以了。 #解析 nslookup www.oldboyedu.com
[root@MiWiFi-R3-srv ~]# rpm -qa |grep cron cronie-anacron-1.4.11-14.el7.x86_64 crontabs-1.11-6.20121102git.el7.noarch cronie-1.4.11-14.el7.x86_64 这些包在最小化安装系统时就已经安装了,并且会开机自启动crond服务,并为我们提供好编写计划任务的crontab命令。 crontab命令被用来提交和管理用户的需要周期性执行的任务,与windows下的计划任务类似 crontab (选项)(参数) -e:编辑该用户的计时器设置; -l:列出该用户的计时器设置; -r:删除该用户的计时器设置; -u<用户名称>:指定要设定计时器的用户名称。 存放定时任务的文件 /var/spool/cron
注意:
1 查看计划任务的执行:tail -f /var/log/cron
2 写计划任务时,命令必须加上绝对路径,否则会出现这种情况:从日志中看,确实触发了计划任务的执行,但是命令却没有执行成功,比如* * * * * reboot就会出现这种情况,需要将reboot写成/usr/sbin/reboot
3. 计划任务执行的命令 是否存在,软件是否安装
4. 确保crontab服务运行
systemctl status cron
ps -ef|grep crond
5. 检测crontab是否开机启动
systemctl is-enabled crond crontab配置文件 在/etc目录下有一个crontab文件,这个就是系统任务调度的配置文件 SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root # For details see man 4 crontabs # Example of job definition: # .---------------- minute (0 - 59) # | .------------- hour (0 - 23) # | | .---------- day of month (1 - 31) # | | | .------- month (1 - 12) OR jan,feb,mar,apr ... # | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat # | | | | | # * * * * * user-name command to be executed 分 时 日 月 周
crontab任务配置基本格式: * * * * * command 分钟(0-59) 小时(0-23) 日期(1-31) 月份(1-12) 星期(0-6,0代表星期天) 命令 第1列表示分钟1~59 每分钟用*或者 */1表示 第2列表示小时1~23(0表示0点) 第3列表示日期1~31 第4列表示月份1~12 第5列标识号星期0~6(0表示星期天) 第6列要运行的命令 星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。 08 * * * 每天8.30去上班 逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9” 中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6” 正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。 */3 * * * * /usr/sbin/ntpdate ntp1.aliyun.com 每隔三分钟执行下时间同步
crontab任务配置基本格式: * * * * * command 分钟(0-59) 小时(0-23) 日期(1-31) 月份(1-12) 星期(0-6,0代表星期天) 命令 第1列表示分钟1~59 每分钟用*或者 */1表示 第2列表示小时1~23(0表示0点) 第3列表示日期1~31 第4列表示月份1~12 第5列标识号星期0~6(0表示星期天) 第6列要运行的命令 星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。 08 * * * 每天8.30去上班 逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9” 中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6” 正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。 */3 * * * * /usr/sbin/ntpdate ntp1.aliyun.com 每隔三分钟执行下时间同步
rpm软件包管理器
#现在要安装mysql #下载地址 https://dev.mysql.com/downloads/mysql/ 安装软件的命令格式 rpm -ivh filename.rpm # i表示安装 v显示详细过程 h以进度条显示 升级软件的命令格式 rpm -Uvh filename.rpm 卸载软件的命令格式 rpm -e filename.rpm 查询软件描述信息的命令格式 rpm -qpi filename.rpm 列出软件文件信息的命令格式 rpm -qpl filename.rpm 查询文件属于哪个 RPM 的命令格式 rpm -qf filename
#下载软件包 wget https://rpmfind.net/linux/centos/7.5.1804/os/x86_64/Packages/lrzsz-0.12.20-36.el7.x86_64.rpm #安装软件包 rpm -ivh lrzsz-0.12.20-36.el7.x86_64.rpm
rpm -q lrzsz #查询lrzsz是否安装 rpm -qi lrzsz #查询lrzsz包的说明信息 rpm -ql lrzsz #查询lrzsz包生成的文件列表 rpm -qc nginx #查询nginx安装生成后的配置文件路径 rpm -qf /etc/nginx/fastcgi.conf #查看这个文件由哪个rpm包安装
rpm -Uvh /PATH/TO/NEW_PACKAGE_FILE: 如果装有老版本的,则升级;否则,则安装;
rpm -Fvh /PATH/TO/NEW_PACKAGE_FILE:如果装有老版本的,则升级;否则,退出;
rpm -e PACKAGE_NAME
需要手动解决依赖
不如 yum remove
yum命令
yum命令是在Fedora和RedHat以及SUSE中基于rpm的软件包管理器,它可以使系统管理人员交互和自动化地更细与管理RPM软件包,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载、安装。 尽管 RPM 能够帮助用户查询软件相关的依赖关系,但问题还是要运维人员自己来解决, 而有些大型软件可能与数十个程序都有依赖关系,在这种情况下安装软件会是非常痛苦的。 Yum 软件仓库便是为了进一步降低软件安装难度和复杂度而设计的技术。Yum 软件仓库可以 根据用户的要求分析出所需软件包及其相关的依赖关系,然后自动从服务器下载软件包并安 装到系统。 Yum 软件仓库中的 RPM 软件包可以是由红帽官方发布的,也可以是第三方发布的,当 然也可以是自己编写的。 yum源的仓库路径在 /etc/yum.repos.d/ 然后这个目录底下,只有 以 .repo结尾的文件,才会被识别为yum仓库
配置环境
配置国内的yum源 1.在/etc/yum.repos.d/目录底下,定制我们自己的repo仓库文件 2.我们自己没有yum仓库,我们就去拿阿里巴巴的yum仓库 3.https://opsx.alibaba.com/mirror 这就是阿里巴巴的镜像站 4.下载阿里巴巴的yum仓库文件 wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo wget下载文件后,-O参数,指定放到某个目录,且改名 5.清除yum缓存 yum clean all 6.生成新的阿里云的yum软件缓存 yum makecache 再配置epel额外的仓库源,这个仓库里就存放了很多第三方软件,例如redis mysql nginx 1.配置epel仓库 wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo 2.最好再生成yum缓存 yum makecache 3.请随心所欲的使用 yum工具 yum示例用法 yum安装nginx web服务器软件 1. yum install nginx -y -y 一路都是默认yes 2.启动nginx 直接输入nginx命令 3.修改nginx主页面 ,文件名字叫做 index.html find / -name index.html 查找这个文件所在地 vim /usr/share/nginx/html/index.html 修改这个nginx首页文件
1.下载python3的源码 cd /opt yum install wget -y 安装wget命令 wget https://www.python.org/ftp/python/3.6.2/Python-3.6.2.tgz 1.安装python3之前,环境依赖解决 通过yum安装工具包,自动处理依赖关系,每个软件包通过空格分割 提前安装好这些软件包,日后就不会出现很多坑 得保证这些依赖工具包,正确安装 yum install gcc patch libffi-devel python-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel -y 2.解压缩源码包 下载好python3源码包之后 Python-3.6.2.tgz 解压缩、 tar命令可以解压缩 tgz格式 tar -xvf Python-3.6.2.tgz 3.切换源码包目录 cd Python-3.6.2 4.编译且安装 1.释放编译文件makefile,这makefile就是用来编译且安装的 ./configure --prefix=/opt/python36/ --prefix 指定软件的安装路径 2. 开始编译python3 make 3.编译且安装 (只有在这一步,才会生成/opt/python36) make install 4.配置python3.6的环境变量 1.配置软连接(注意,这个和PATH配置,二选一) ln -s 目标文件 软连接文件 ln -s /opt/python36/bin/python3.6 /usr/bin/python3 此时还没有pip ln -s /opt/python36/bin/pip3 /usr/bin/pip3 2.配置path环境变量 (二选一即可) echo $PATH查看环境变量 /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin #这个变量赋值操作,只是临时生效,需要写入到文件,永久生效 PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/opt/python36/bin #linux有一个全局个人配置文件 编辑这个文件,在最底行写入PATH vim /etc/profile 写入 PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/opt/python36/bin 保存退出 读一下这个/etc/profile 使得生效 source /etc/profile 5.测试linux安装一个django, pip3 install django 6.创建django项目 django-admin startproject mysite 7.创建django的APP应用 django-admin startapp app01 8.编写视图函数,测试一个index视图 9.注意修改settings.py的allow_hosts,windows方可访问linux的django项目
安装virtualevn 1.下载virtualenv工具 通过物理环境的pip工具安装 pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple virtualenv 安装完成后你的linux就多了一个virtualenv命令 2.创建虚拟环境venv1 venv2 virtualenv --no-site-packages --python=python3 s15venv1 调用虚拟环境的命令 --no-site-packages 这是构建干净,隔离的模块的参数 --python=python3 这个参数是指定虚拟环境以哪一个物理解释器为基础的 最后一个是虚拟环境的名字 会创建这么一个文件夹 3.进入虚拟环境目录,激活虚拟环境 找到你的虚拟环境目录bin地下的activate文件 source myenv/s15venv1/bin/activate - 激活虚拟环境,原理就是修改了PATH变量,path是有顺序执行的 echo $PATH 检查环境变量 which python3 which pip3 检查虚拟环境是否正常 4.测试安装2个虚拟环境,venv1,venv2,并且运行2个django不同版本的项目 pip3 install django==1.11.11 安装django 不指定则为最新版本 django-admin startproject venv1 创建一个项目 cd venv1/ cd venv1/ vim settings.py 修改setting.py -> ALLOWED_HOSTS = ['*'] python3 manage.py runserver 0.0.0.0:8000 运行程序 5.退出虚拟换的命令 deactivate
保证本地开发环境和线上一致性的操作
解决方案: 1.通过命令保证环境的一致性,导出当前python环境的包 pip3 freeze > requirements.txt 这将会创建一个 requirements.txt 文件,其中包含了当前环境中所有包及 各自的版本的简单列表。 可以使用 “pip list”在不产生requirements文件的情况下, 查看已安装包的列表。 2.上传至服务器后,在服务器下创建virtualenv,在venv中导入项目所需的模块依赖 pip3 install -r requirements.txt
1.安装这个命令,必须得在物理解释器底下,注意!! pip3 install virtualenvwrapper 1.1 注意 ,请看这里 注意 ,请看这里 注意 ,请看这里 注意这里path的配置,需要将物理解释器的python,放在path最前面 echo $PATH 这里保持配置和我一样,将python3放在最前面 编辑这个文件,在最底行写入PATH vim /etc/profile [root@localhost ~]# echo $PATH /opt/python36/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/bin 2.修改环境变量,每次开机就加载这个virtualenvwrapper工具 vim ~/.bashrc #vim编辑用户家目录下的.bashrc文件,这个文件是用户在登录的时候,就读取这个文件 #export 是读取shell命令的作用 #这些变量根据你自己的绝对路径环境修改 export WORKON_HOME=~/Envs #设置virtualenv的统一管理目录 export VIRTUALENVWRAPPER_VIRTUALENV_ARGS='--no-site-packages' #添加virtualenvwrapper的参数,生成干净隔绝的环境 export VIRTUALENVWRAPPER_PYTHON=/opt/python36/bin/python3 #指定python解释器 source /opt/python36/bin/virtualenvwrapper.sh #执行virtualenvwrapper安装脚本 3.重新登录会话,使得这个配置生效 logout ssh .... 4.此时正确的话 virtualenvwrapper工具已经可以使用 提供了哪些命令? mkvirtualenv 虚拟环境名 #自动下载虚拟环境,且激活虚拟环境 workon 虚拟环境名 #激活虚拟环境 deactivate 退出虚拟环境 rmvirtualenv 删除虚拟环境 cdvirtualenv 进入当前已激活的虚拟环境所在的目录 cdsitepackages 进入当前激活的虚拟环境的,python包的目录