https://www.cnblogs.com/huangqingshi/p/12496743.html
随着Flink 1.10的发布,对SQL的支持也非常强大。Flink 还提供了 MySql, Hive,ES, Kafka等连接器Connector,所以使用起来非常方便。
接下来咱们针对构建流式SQL应用文章的梗概如下:
1. 搭建流式SQL应用所需要的环境准备。
2. 构建一个按每小时进行统计购买量的应用。
3. 构建每天以10分钟的粒度进行统计应用。
4. 构建按分类进行排行,取出想要的结果应用。
1. 搭建流式应用所需要的环境准备
注意:elasticsearch,mysql要配置允许远程访问
Kafka,用于将数据写入到Kafka中,然后Flink通过读取Kafka的数据然后再进行处理。版本号:2.11。
MySQL, 用于保存数据的分类。Flink从中读取分类进行处理和计算 。版本号:8.0.15。
ElasticSearch, 用于保存结果数据和进行索引存储。下载的时候可以在搜索引擎里边搜索“elasticsearch 国内”,这样就可以从国内快速下载,要不然下载的太慢了。版本号:7.6.0。
Kibana, 用于ES的结果展示,图形化的界面美观。 下载的时候也需要搜索“Kibana 国内”,比较快速。版本号:7.6.0。
Flink, 核心的流处理程序,版本号:1.10。Flink支持国内镜像下载,这个到时候可以自行找一下。
Zookeeper, Kafka依赖这个应用,所以也会用到的,这个什么版本都是可以的。我的版本号:3.4.12。
当然我的是mac电脑,如果是mac电脑的话,下载ES和Kibana的时候要下载文件中带“darwin”字样的,可以在Mac中使用其他的不能执行。应该是程序里边的编译不同,这个也是一个小坑。
因为Flink需要连接Mysql, Elasticseratch , Kafka,所以也需要提前下载Flink所需要的Connector jar包到Flink的lib里边。
wget -P ./lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-json/1.10.0/flink-json-1.10.0.jar |
wget -P ./lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.10.0/flink-sql-connector-kafka_2.11-1.10.0.jar |
wget -P ./lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-elasticsearch6_2.11/1.10.0/flink-sql-connector-elasticsearch6_2.11-1.10.0.jar |
wget -P ./lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-jdbc_2.11/1.10.0/flink-jdbc_2.11-1.10.0.jar |
wget -P ./lib/ https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.48/mysql-connector-java-5.1.48.jar
环境都准备好了,那么需要把环境都启动起来,进行检查。
Elasticsearch启动好了之后需要访问这个网址没有问题,说明成功了:http://localhost:9200/_cluster/health?pretty。
Flink启动好之后需要访问 http://localhost:8081 会有界面展示。
Kibana 启动好了之后访问:http://127.0.0.1:5601/ 会有界面展示。当然Kibana在目录conf/kibana.yml里边需要把ES的地址给打开。
Zookeeper 这个相信很多同学都会配置了,如果有不会配置的,可以自己搜索一下。
我们先看一下最后的效果图,可能不是特别好,是这么个意思。
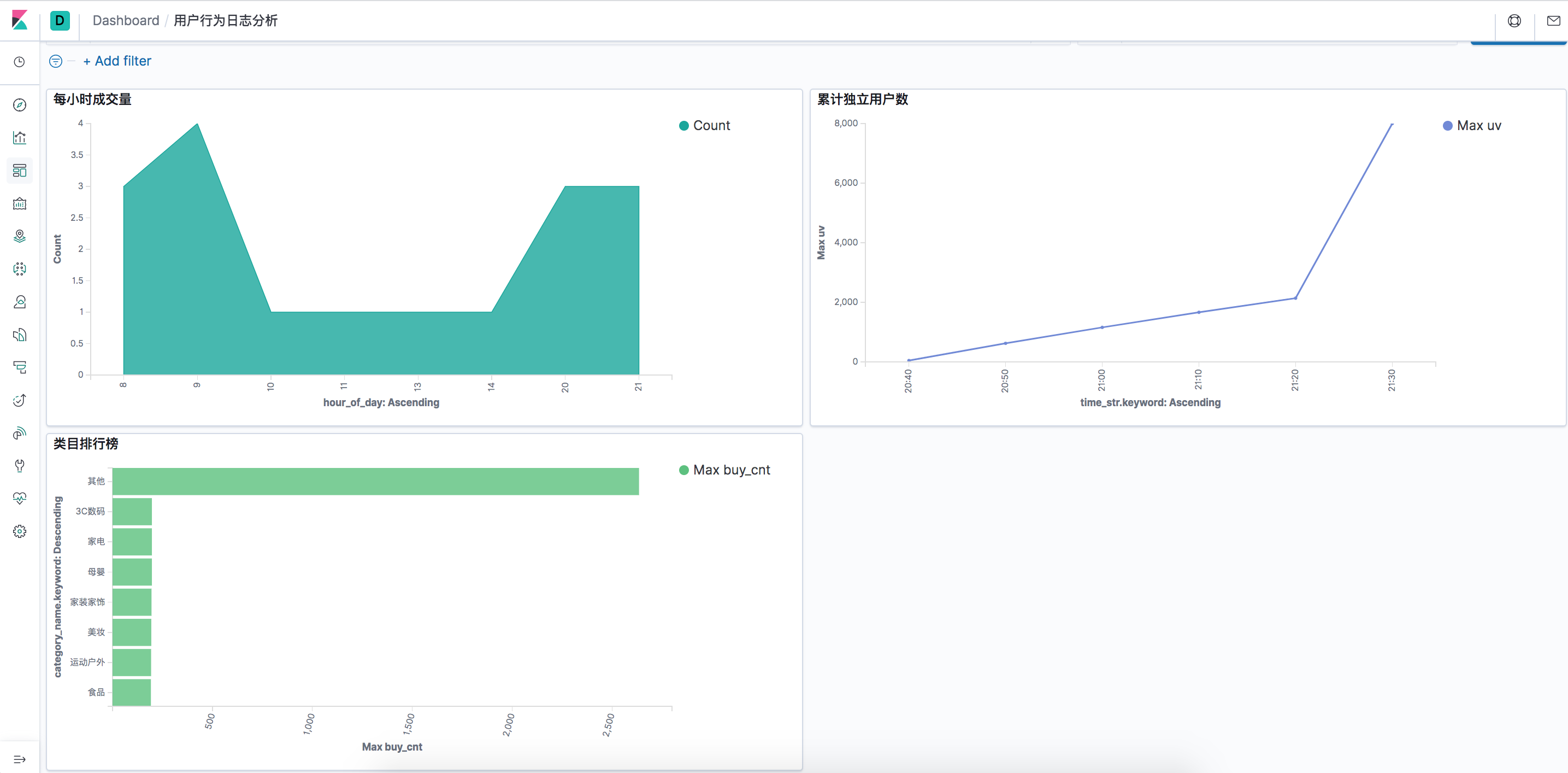
2. 构建一个按每个小时统计购买量应用。
我们写一个程序,往Kafka里边写数据,模拟一些连续的数据源头。
首先定义一个Pojo类。

package myflink.pojo;
public class UserBehavior {
//用户ID
public long userId;
//商品ID
public long itemId;
//商品类目ID
public int categoryId;
//用户行为,包括{"pv","buy","cart", "fav"}
public String behavior;
//行为发生的时间戳,单位秒
public String ts;
public long getUserId() {
return userId;
}
public void setUserId(long userId) {
this.userId = userId;
}
public long getItemId() {
return itemId;
}
public void setItemId(long itemId) {
this.itemId = itemId;
}
public int getCategoryId() {
return categoryId;
}
public void setCategoryId(int categoryId) {
this.categoryId = categoryId;
}
public String getBehavior() {
return behavior;
}
public void setBehavior(String behavior) {
this.behavior = behavior;
}
public String getTimestamp() {
return ts;
}
public void setTimestamp(String ts) {
this.ts = ts;
}
}
接着写一个往Kafka写数据的类。随机生成用于的行为,里边包括用户的id,类目id等。让程序运行起来。
package myflink.kafka;
import com.alibaba.fastjson.JSON;
import myflink.pojo.UserBehavior;
import org.apache.commons.lang3.RandomUtils;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
/**
* @author huangqingshi
* @Date 2020-03-15
*/
public class KafkaWriter {
//本地的kafka机器列表
public static final String BROKER_LIST = "localhost:9092";
//kafka的topic
public static final String TOPIC_USER_BEHAVIOR = "user_behaviors";
//key序列化的方式,采用字符串的形式
public static final String KEY_SERIALIZER = "org.apache.kafka.common.serialization.StringSerializer";
//value的序列化的方式
public static final String VALUE_SERIALIZER = "org.apache.kafka.common.serialization.StringSerializer";
private static final String[] BEHAVIORS = {"pv","buy","cart", "fav"};
private static KafkaProducer<String, String> producer;
public static void writeToKafka() throws Exception{
//构建userBehavior, 数据都是随机产生的
int randomInt = RandomUtils.nextInt(0, 4);
UserBehavior userBehavior = new UserBehavior();
userBehavior.setBehavior(BEHAVIORS[randomInt]);
Long ranUserId = RandomUtils.nextLong(1, 10000);
userBehavior.setUserId(ranUserId);
int ranCate = RandomUtils.nextInt(1, 100);
userBehavior.setCategoryId(ranCate);
Long ranItemId = RandomUtils.nextLong(1, 100000);
userBehavior.setItemId(ranItemId);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss'Z'");
userBehavior.setTimestamp(sdf.format(new Date()));
//转换为json
String userBehaviorStr = JSON.toJSONString(userBehavior);
//包装成kafka发送的记录
ProducerRecord<String, String> record = new ProducerRecord<String, String>(TOPIC_USER_BEHAVIOR, null,
null, userBehaviorStr);
//发送到缓存
producer.send(record);
System.out.println("向kafka发送数据:" + userBehaviorStr);
//立即发送
producer.flush();
}
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", BROKER_LIST);
props.put("key.serializer", KEY_SERIALIZER);
props.put("value.serializer", VALUE_SERIALIZER);
producer = new KafkaProducer<>(props);
while(true) {
try {
//每一秒写一条数据
TimeUnit.SECONDS.sleep(1);
writeToKafka();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
本地idea Console 输出的结果是这样的:
向kafka发送数据:{"behavior":"buy","categoryId":7,"itemId":75902,"timestamp":"2020-03-15T11:35:11Z","ts":"2020-03-15T11:35:11Z","userId":4737}
我们将Flink的任务数调整成10个,也就是同时执行的任务数。 位置在 conf/flink-conf.yaml,taskmanager.numberOfTaskSlots: 10,然后重启下。我的已经启动并且运行了3个任务,看下图:
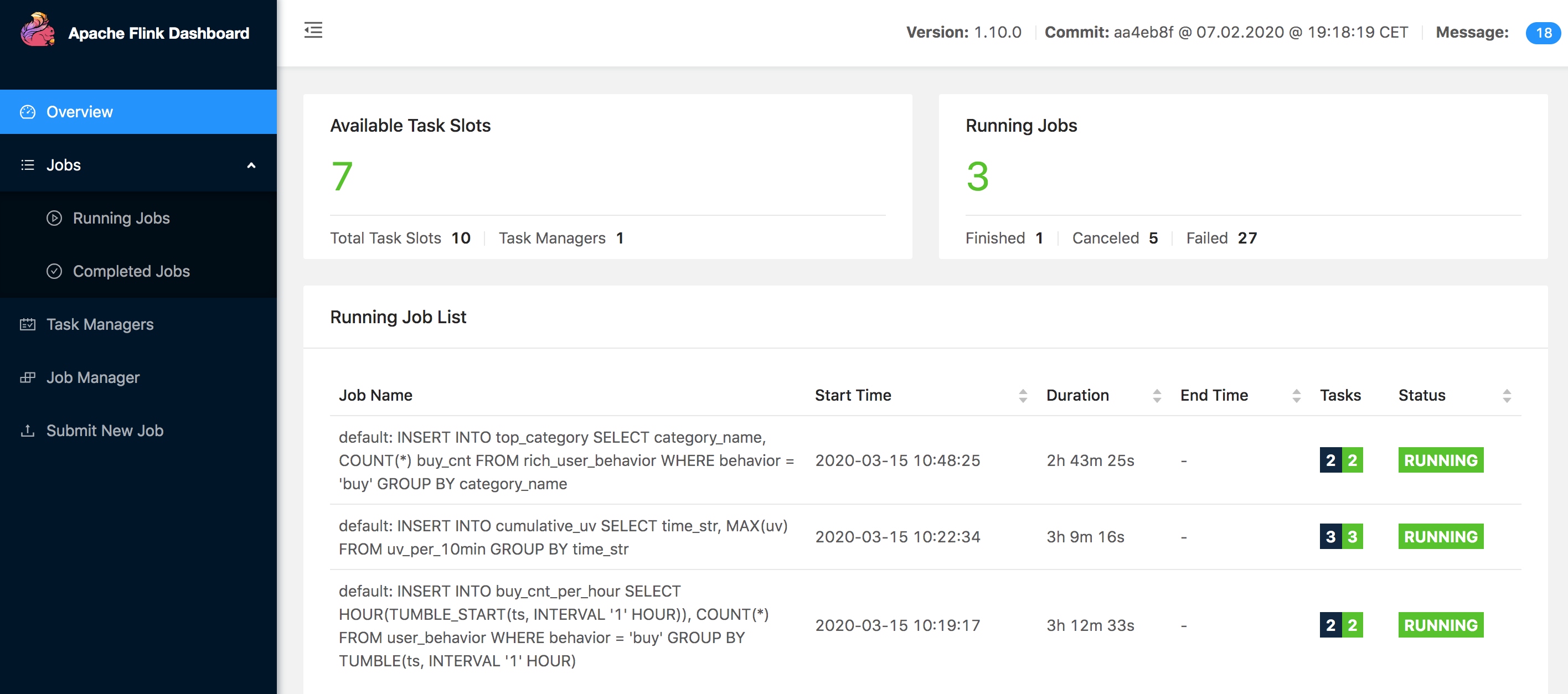
我们接下来运行Flink 内置的客户端。命令: bin/sql-client.sh embedded,这样我们就开始了Flink SQL之旅了。我们使用Flink的DDL,从Kafka里边读取数据,采用ProcessingTime的时间事件进行处理,为ts设置水位线,允许5秒延迟。更多参考 时间属性 和 Flink DDL。里边的Kafka 连接以及相关的配置,相信大家都不是很陌生。
CREATE TABLE user_behavior (
userId BIGINT,
itemId BIGINT,
categoryId BIGINT,
behavior STRING,
ts TIMESTAMP(3),
proctime as PROCTIME(), -- 通过计算列产生一个处理时间列
WATERMARK FOR ts as ts - INTERVAL '5' SECOND -- 在ts上定义watermark,ts成为事件时间列
) WITH (
'connector.type' = 'kafka', -- 使用 kafka connector
'connector.version' = 'universal', -- kafka 版本,universal 支持 0.11 以上的版本
'connector.topic' = 'user_behaviors', -- kafka topic
'connector.startup-mode' = 'earliest-offset', -- 从起始 offset 开始读取
'connector.properties.zookeeper.connect' = 'localhost:2181', -- zookeeper 地址
'connector.properties.bootstrap.servers' = 'localhost:9092', -- kafka broker 地址
'format.type' = 'json' -- 数据源格式为 json
);
接下来我们使用select来看一下Flink的数据,执行语句:select * from user_behavior,会出现如下图。同时SQL上面还支持 show tables、describe user_behavior 等操作。
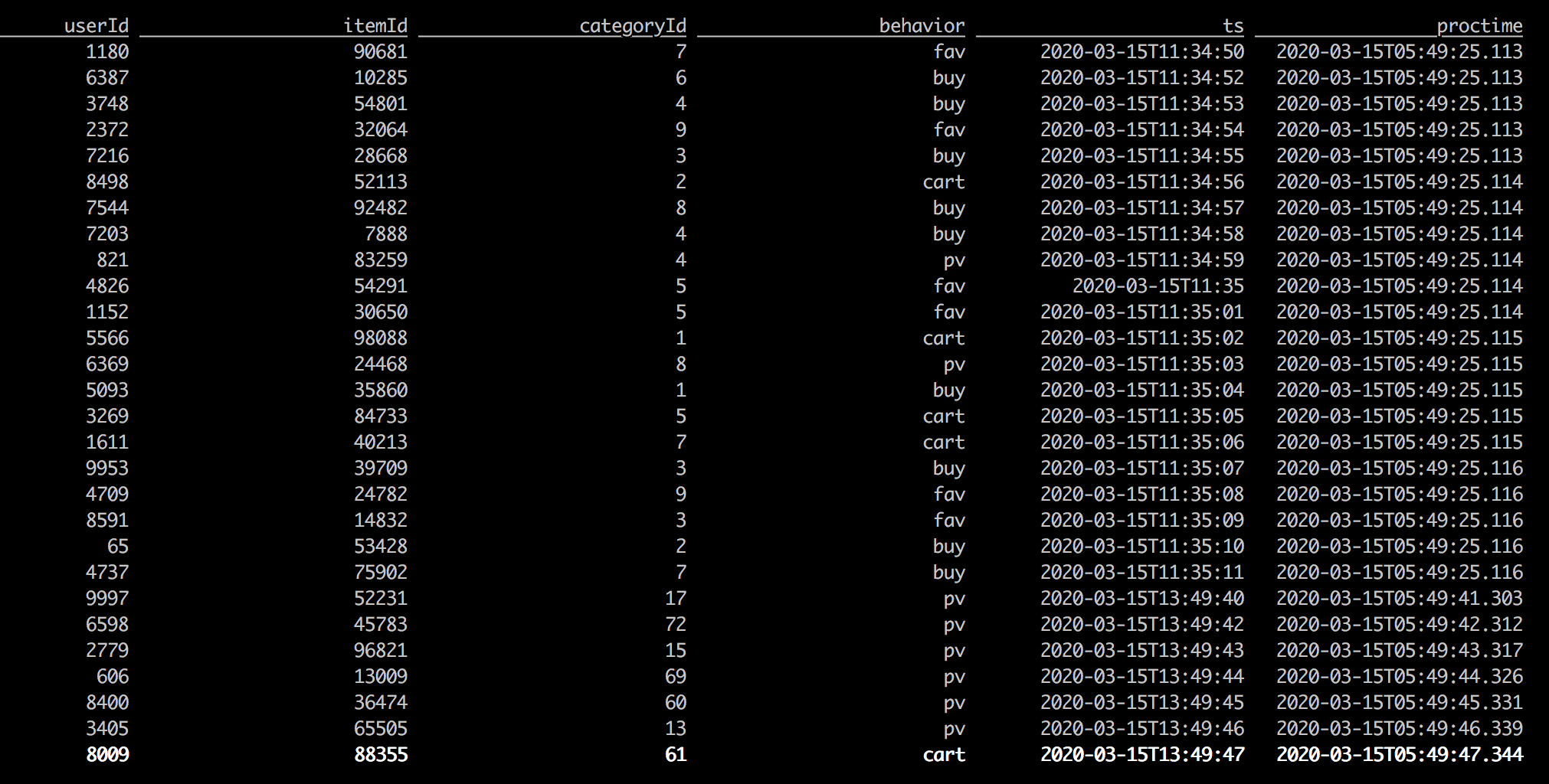
我们需要将结果放入Elasticsearch,这样也比较简单,我们还通过DDL来创建一个表。我们只需要一个语句,就可以实现连接Elasticsearch(后边简称ES)并且创建相应的Type和Index了。不需要自己再去创建一次,是不是很简单,哈。里边有两个字段,一个是每天的小时数,一个是购买的统计量。当有数据写入这个表的时候,那么就会将数据写入到ES上,非常方便。
CREATE TABLE buy_cnt_per_hour (
hour_of_day BIGINT,
buy_cnt BIGINT
) WITH (
'connector.type' = 'elasticsearch', -- 使用 elasticsearch connector
'connector.version' = '6', -- elasticsearch 版本,6 能支持 es 6+ 以及 7+ 的版本
'connector.hosts' = 'http://localhost:9200', -- elasticsearch 地址
'connector.index' = 'buy_cnt_per_hour', -- elasticsearch 索引名,相当于数据库的表名
'connector.document-type' = 'user_behavior', -- elasticsearch 的 type,相当于数据库的库名
'connector.bulk-flush.max-actions' = '1', -- 每条数据都刷新
'format.type' = 'json', -- 输出数据格式 json
'update-mode' = 'append'
);
每个小时的购买量,那么我们需要的是使用滚动窗口,Tumbling Window,那么使用TUMBLE_START函数,另外我们还需要获取ts中的小时数,那么需要使用HOUR函数。将所有behavior为buy的写入到这个表中。
INSERT INTO buy_cnt_per_hour SELECT HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)), COUNT(*) FROM user_behavior WHERE behavior = 'buy' GROUP BY TUMBLE(ts, INTERVAL '1' HOUR);
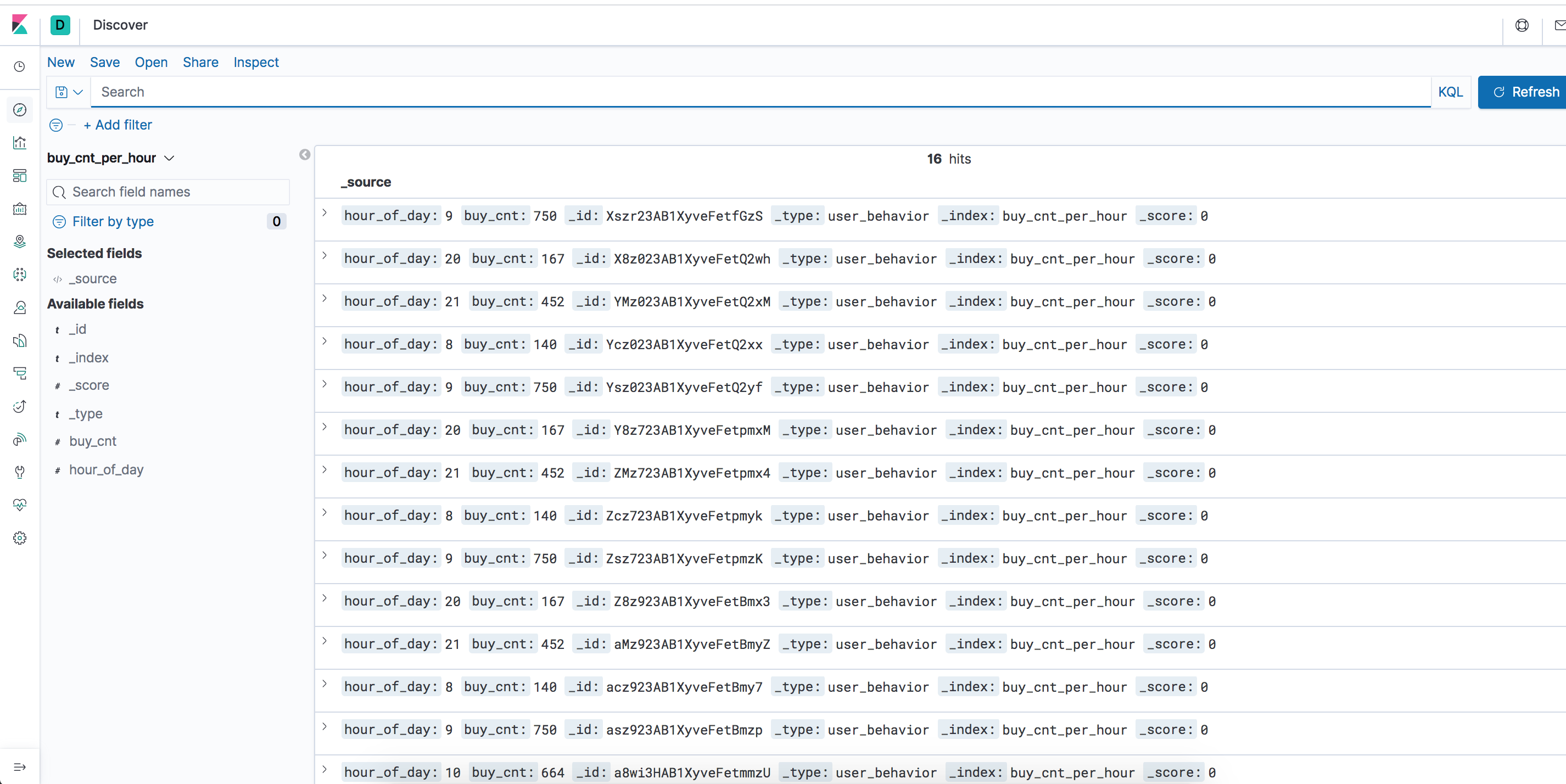
这个时候看Flink里边的任务中会出现这个任务,因为是持续不断的进行处理的。执行过程中如果有数据的话,那么会将数据写到表 buy_cnt_per_hour,同时也会将数据写到ES里边。

下面我们来配置一下Kinbana来将结果进行展示,访问 http://localhost:5601, 然后选择左边菜单的“Management”,然后选择 “Index Patterns” -> “Create Index Pattern”, 输入我们刚才创建的Index: “buy_cnt_per_hour”。可以通过左侧的“Discover”按钮就可以看到我们的数据了。
我们继续点击左侧的“Dashboard”按钮,创建一个“用户行为日志分析”的Dashboard。 进入左侧的 “Visualize” - “Create Visualization" 选择“Area”图,Bucket的按我下边截图左下进行配置和选择。
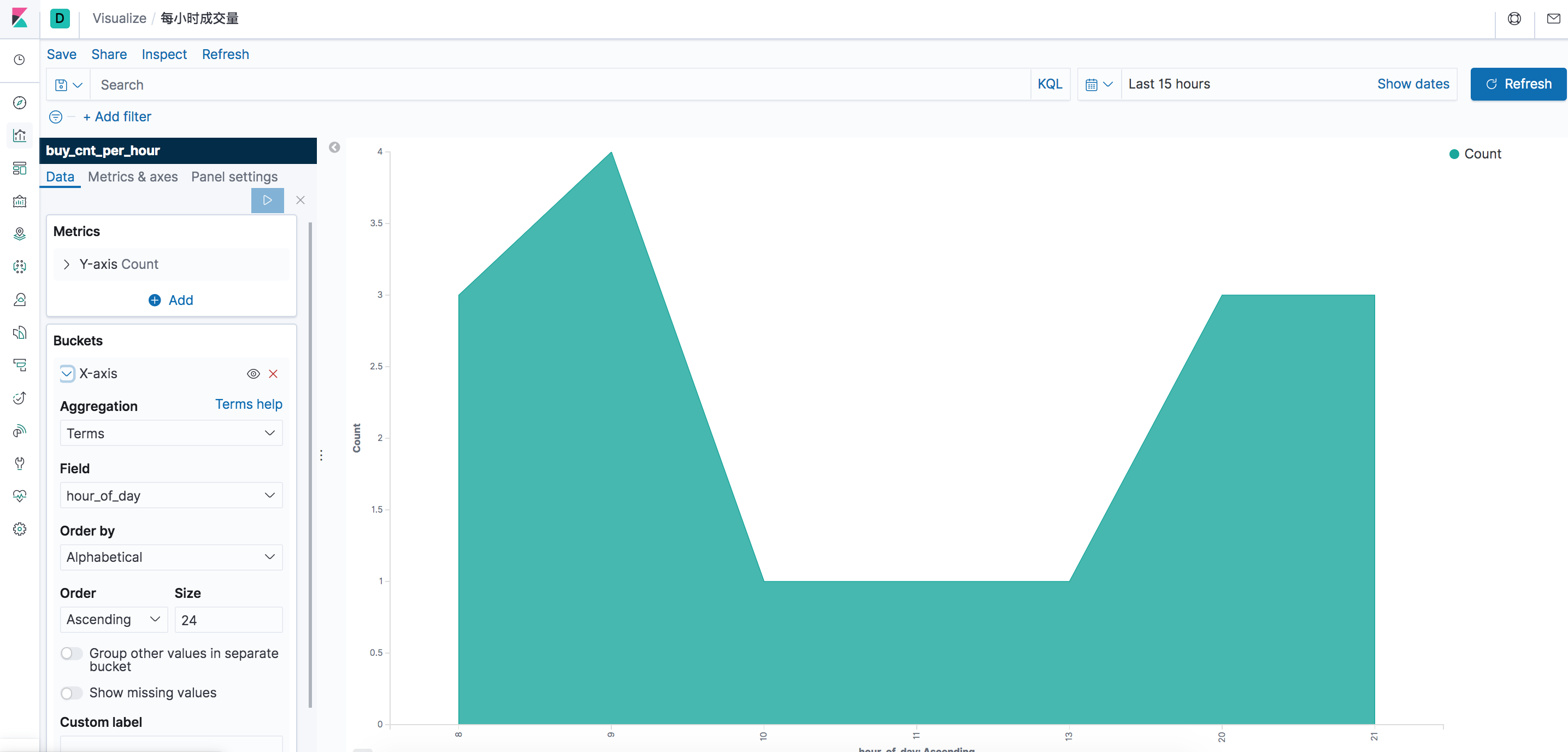
保存后添加到Dashboard即可。这样就从数据源头到数据展示就构建完成了,是不是很快~
3. 构建每天以10分钟的粒度进行统计独立用户数应用。
我们继续使用DDL创建Flink的表以及对应的ES的Index。
CREATE TABLE cumulative_uv (
time_str STRING,
uv BIGINT
) WITH (
'connector.type' = 'elasticsearch',
'connector.version' = '6',
'connector.hosts' = 'http://localhost:9200',
'connector.index' = 'cumulative_uv',
'connector.document-type' = 'user_behavior',
'format.type' = 'json',
'update-mode' = 'upsert'
);
创建好了需要将ts进行分解出来小时和分钟,通过一个视图,这个视图和数据库的视图类似,不存储数据,也不占用Flink的执行Task。首先将ts格式化,然后转换成时间:小时:分钟,分钟后边没有0,结尾需要补个0。然后统计不同的用户数需要使用DISTINCT函数和COUNT函数。还有使用Over Window功能,也就是从之前的数据到现在,以处理时间升序把数据按Window的功能来进行统计。直白的将就是有一条数据的话就会将数据处理, 然后有一条数据比当前最大值大的话会保留最大值。当前窗口是以每10分钟为一个窗口。
CREATE VIEW uv_per_10min AS SELECT MAX(SUBSTR(DATE_FORMAT(ts, 'HH:mm'),1,4) || '0') OVER w AS time_str, COUNT(DISTINCT userId) OVER w AS uv FROM user_behavior WINDOW w AS (ORDER BY proctime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW);
这个视图主要是数据比较多,只需要每10分钟一个点其实就满足要求了,那么现在我们需要做的就是再将数据处理一下即可写入ES。
INSERT INTO cumulative_uv SELECT time_str, MAX(uv) FROM uv_per_10min GROUP BY time_str;
这样ES里边就会有新的index产生,下一步我们在kibana里边创建一个 index pattern, 输入index “cumulative_uv”,接下来到 “Visualize”里边创建一个 Visualization ,名为“累计独立用户数”,表选择“Line”类型的图标,其他指标和我下图配置的一样即可。

累计独立用户数也创建好了。
4. 构建按分类进行排行,取出想要的结果应用。
接下来我们需要按主类目进行统计和排序。因为子类目非常多。
首先我们需要准备一个mysql, 然后创建好表。简单些几条对应的类目关系,当然可以根据自己所生成的数据进行自行写入一些对应的关系表。
create table category (
sub_category_id bigint(20),
parent_category_id bigint(20)
);
insert into category(sub_category_id, parent_category_id) values(1038, 1);
insert into category(sub_category_id, parent_category_id) values(91244, 1);
insert into category(sub_category_id, parent_category_id) values(44712, 1);
insert into category(sub_category_id, parent_category_id) values(2,2);
insert into category(sub_category_id, parent_category_id) values(3,3);
insert into category(sub_category_id, parent_category_id) values(4,4);
insert into category(sub_category_id, parent_category_id) values(5,5);
insert into category(sub_category_id, parent_category_id) values(6,6);
insert into category(sub_category_id, parent_category_id) values(7,7);
insert into category(sub_category_id, parent_category_id) values(8,8);
insert into category(sub_category_id, parent_category_id) values(9,9);
定义一个Flink表,数据从Mysql获取,用于进行类目关系关联。
CREATE TABLE category_dim (
sub_category_id BIGINT, -- 子类目
parent_category_id BIGINT -- 顶级类目
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://localhost:3306/flink',
'connector.table' = 'category',
'connector.driver' = 'com.mysql.jdbc.Driver',
'connector.username' = 'root',
'connector.password' = 'root',
'connector.lookup.cache.max-rows' = '5000',
'connector.lookup.cache.ttl' = '10min'
);
创建ES的index,用于存储统计后的结果。
CREATE TABLE top_category (
category_name STRING, -- 类目名称
buy_cnt BIGINT -- 销量
) WITH (
'connector.type' = 'elasticsearch',
'connector.version' = '6',
'connector.hosts' = 'http://localhost:9200',
'connector.index' = 'top_category',
'connector.document-type' = 'user_behavior',
'format.type' = 'json',
'update-mode' = 'upsert'
);
接下来还是创建一个视图,将表和类目关联起来,方便后边的统计结果。使用的是 Temporal Join。
CREATE VIEW rich_user_behavior AS
SELECT U.userId, U.itemId, U.behavior,
CASE C.parent_category_id
WHEN 1 THEN '服饰鞋包'
WHEN 2 THEN '家装家饰'
WHEN 3 THEN '家电'
WHEN 4 THEN '美妆'
WHEN 5 THEN '母婴'
WHEN 6 THEN '3C数码'
WHEN 7 THEN '运动户外'
WHEN 8 THEN '食品'
ELSE '其他'
END AS category_name
FROM user_behavior AS U LEFT JOIN category_dim FOR SYSTEM_TIME AS OF U.proctime AS C
ON U.categoryId = C.sub_category_id;
将类型为“buy”的写入到表,同时也就是写入了ES里边,然后ES里边的index-top_category 也就有了数据了。
INSERT INTO top_category SELECT category_name, COUNT(*) buy_cnt FROM rich_user_behavior WHERE behavior = 'buy' GROUP BY category_name;
我们继续在Kibana里边创建一个index pattern,输入“top_category”,然后visualize里边创建一个visualization 名为类目排行榜。详细的配置可参考如下。

好了整个的过程计算创建完了。
通过使用Flink 1.10以及对应的Connector, 实现了对Mysql, Kafka, Elasticsearch 的快速连接,更快的达到的我们想要实现的效果。
里边涉及到往kafka里边写数据可参考工程:https://github.com/stonehqs/flink-demo