来源:https://mp.weixin.qq.com/s/PLWovsMDxO0wUrDTMaOh4w
Cube相关
GROUPING SETS:使用频率 ★
类似于kylin中的cube,将多种维度进行组合统计;在一个GROUP BY查询中,根据不同维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
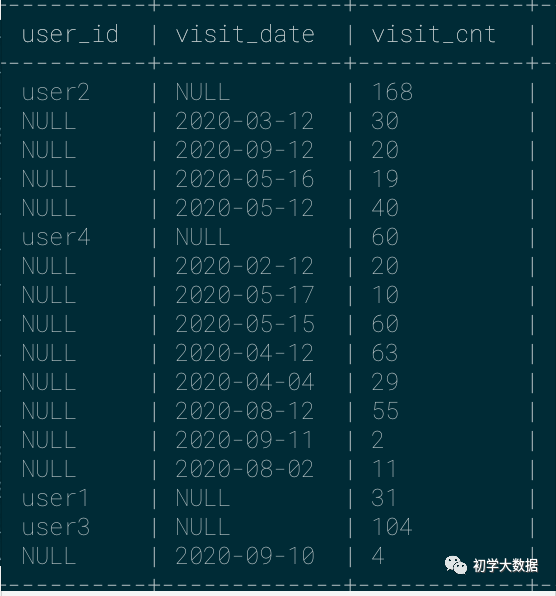
1 --按照用户+访问日期统计统计次数 2 select 3 user_id, 4 visit_date, 5 sum(visit_cnt) as visit_cnt 6 from wedw_tmp.tmp_url_info 7 group by user_id,visit_date 8 grouping sets(user_id,visit_date) 9 10 --下图的结果类似于以下sql 11 select 12 user_id, 13 NULL as visit_date, 14 sum(visit_cnt) as visit_cnt 15 from wedw_tmp.tmp_url_info 16 union all 17 select 18 NULL as user_id, 19 visit_date, 20 sum(visit_cnt) as visit_cnt 21 from wedw_tmp.tmp_url_info 22 union all 23 select 24 user_id, 25 visit_date, 26 sum(visit_cnt) as visit_cnt 27 from wedw_tmp.tmp_url_info
字符相关
concat:使用频率 ★★★★★
字符拼接,concat(string|binary A, string|binary B…);该函数比较简单
1select concat('a','b','c') 2--最后结果就是abc
concat_ws:使用频率 ★★★★★
按照指定分隔符将字符或者数组进行拼接;concat_ws(string SEP, array)/concat_ws(string SEP, string A, string B…)
1 --还是concat使用的例子,这里可以写成 2 select concat_ws('','a','b','c') 3 4 --将数组列表元素按照指定分隔符拼接,类似于python中的join方法 5 select concat_ws('',array('a','b','c'))
instr:使用频率 ★★★★
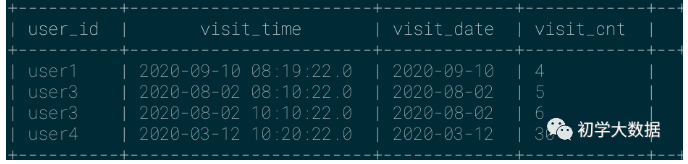
查找字符串str中子字符串substr出现的位置,如果查找失败将返回0,如果任一参数为Null将返回null,注意位置为从1开始的;通常笔者用这个函数作为模糊查询来查询
1 --查询vist_time包含10的记录 2 select 3 user_id, 4 visit_time, 5 visit_date, 6 visit_cnt 7 from wedw_tmp.tmp_url_info 8 where instr(visit_time,'10')>0
length:使用频率 ★★★★★
统计字符串的长度
1select length('abc')
size:使用频率 ★★★★★
是用来统计数组或者map的元素,通常笔者用该函数用来统计去重数(一般都是通过distinct,然后count统计,但是这种方式效率较慢)
1--使用size 2 select 3 distinct size(collect_set(user_id) over(partition by year(visit_date))) 4 from wedw_tmp.tmp_url_info 5+-----------+--+ 6| user_cnt | 7+-----------+--+ 8| 4 | 9+-----------+--+ 101 row selected (0.268 seconds) 11 12--使用通过distinct,然后count统计的方式 13 select 14 count(1) 15 from 16 ( 17 select 18 distinct user_id 19 from wedw_tmp.tmp_url_info 20 )t 21+-----------+--+ 22| count(1) | 23+-----------+--+ 24| 4 | 25+-----------+--+ 261 row selected (0.661 seconds) 27 28--笔者这里只用到了19条记录数,就可以明显观察到耗时差异,这里涉及到shuffle问题,后续将会有单独的文章来讲
trim:使用频率 ★★★★★
将字符串前后的空格去掉,和java中的trim方法一样,这里还有ltrim和rtrim,不再讲述了
1 --最后会得到sfssf sdf sdfds 2 select trim(' sfssf sdf sdfds ')
regexp_replace:使用频率 ★★★★★
regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT)
按照Java正则表达式PATTERN将字符串中符合条件的部分成REPLACEMENT所指定的字符串,如里REPLACEMENT空的话,抽符合正则的部分将被去掉
1--将url中?参数后面的内容全部剔除 2 select 3 distinct regexp_replace(visit_url,'\?(.*)','') as visit_url 4 from wedw_tmp.tmp_url_info

regexp_extract:使用频率 ★★★★
regexp_extract(string subject, string pattern, int index)
抽取字符串subject中符合正则表达式pattern的第index个部分的子字符串,注意些预定义字符的使用
类型于python爬虫中的xpath,用于提取指定的内容
1--提取csdn文章编号 2 select 3 distinct regexp_extract(visit_url,'/details/([0-9]+)',1) as visit_url 4 from wedw_tmp.tmp_url_info

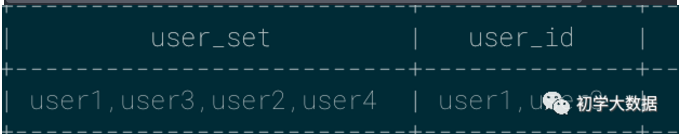
substring_index:使用频率 ★★
substring_index(string A, string delim, int count)
截取第count分隔符之前的字符串,如count为正则从左边开始截取,如果为负则从右边开始截取
1 --比如将2020年的用户组合获取前2个用户,下面的sql将上面讲解的函数都结合在一起使用了 2 select 3 user_set, 4 substring_index(user_set,',',2) as user_id 5 from 6( 7 select 8 distinct concat_ws(',',collect_set(user_id) over(partition by year(visit_date))) as user_set 9 from wedw_tmp.tmp_url_info 10 )t