NumPy进阶修炼第三期
import numpy as np import pandas as pd import warnings warnings.filterwarnings("ignore")
41 生成指定格式数据
备注:使用numpy生成6行6列的二维数组,值为1-100随机数
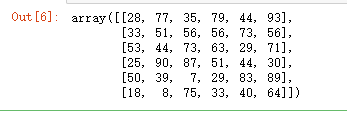
data = np.random.randint(1,100, [6,6])
data
42 找到每列的最大值
np.amax(data, axis=0)
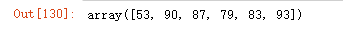
43 找到每行的最小值
np.amin(data, axis=1)

44 提取data每个元素的出现次数
np.unique(data,return_counts=True)

45 获取data每行元素的大小排名
data.argsort()

46 将数组按行重复一次
np.repeat(data, 2, axis=0)

47 去除数组的重复行
np.unique(data,axis = 0)

48 不放回抽样
备注:从data的第一行中不放回抽3个元素
np.random.choice(data[0:1][0], 3, replace=False)

49 提取data第二行中不含第三行的元素的元素
a = data[1:2] b = data[2:3] index=np.isin(a,b) array=a[~index] array

50 判断data是否有空行
(~data.any(axis=1)).any()

51 将每行升序排列
data.sort(axis = 1)
data

52 将data的数据格式修改为float
data1 = data.astype(float)
53 将小于5的元素修改为nan
data1[data1 < 5] = np.nan
data1

54 删除data1含有nan的行
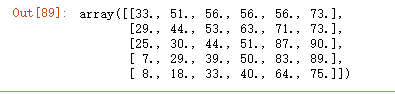
data1 = data1[~np.isnan(data1).any(axis=1), :]
data1
55 找出data1第一行出现频率最高的值
vals, counts = np.unique(data1[0,:], return_counts=True) print(vals[np.argmax(counts)])

56 找到data1中与100最接近的数字
a = 100
data1.flat[np.abs(data1 - a).argmin()]

57 data1每一行的元素减去每一行的平均值
data1 - data1.mean(axis=1, keepdims=True)

58 将data1归一化至区间[0,1]
a = np.max(data1) - np.min(data1)
(data1 - np.min(data1)) / a

59 将data1标准化
mu = np.mean(data1, axis=0) sigma = np.std(data1, axis=0) (data1 - mu) / sigma

60 将data1存储至本地
np.savetxt('test.txt',data1)