对于spark前来围观的小伙伴应该都有所了解,也是现在比较流行的计算框架,基本上是有点规模的公司标配,所以如果有时间也可以补一下短板。
简单来说Spark作为准实时大数据计算引擎,Spark的运行需要依赖资源调度和任务管理,Spark自带了standalone模式资源调度和任务管理工具,运行在其他资源管理和任务调度平台上,如Yarn、Mesos、Kubernates容器等。
spark的搭建和Hadoop差不多,稍微简单点,本文针对下面几种部署方式进行详细描述:
-
Local:多用于本地测试,如在eclipse,idea中写程序测试等。
-
Standalone:Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
-
Yarn:Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
了解一个框架最直接的方式首先要拿来玩玩,玩之前要先搭建,废话少说,进入正题,搭建spark集群。
一、环境准备
搭建环境:CentOS7+jdk8+Hadoop2.10.1+Spark3.0.1
- 机器准备,由于已经搭建过Hadoop,spark集群也是使用相同集群(个人电脑资源有限),可以参照Hadoop搭建博客:centos7中搭建hadoop2.10高可用集群
- 需要安装jdk1.8、Scala2.12.12、hadoop2.10.1、spark3.0.1,其中jdk1.8和Hadoop2.10也都已经安装完成,这里只介绍Scala和spark环境配置
- 机器免密登录,也在Hadoop部署时做过,可以参照Hadoop搭建博客:centos7中搭建hadoop2.10高可用集群
- 下载Scala2.12.12(https://www.scala-lang.org/download/2.12.12.html)、下载spark3.0.1(http://spark.apache.org/downloads.html)
二、配置环境变量
1.配置Scala环境
tar -zxvf scala-2.12.12.tgz -C /opt/soft/ cd /opt/soft ln -s scala-2.12.12 scala
vim /etc/profile
添加环境变量
#SCALA
export SCALA_HOME=/opt/soft/scala
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile
测试是否正常

正常
2.配置spark环境变量
由于各个部署方式都需要该步骤,在此单独配置,各个部署方式不再配置
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz -C /opt/soft cd /opt/soft ln -s spark-3.0.1-bin-hadoop2.7 spark
vim /etc/profile
添加环境变量
#spark
export SPARK_HOME=/opt/soft/spark
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
三、搭建步骤
1.本地Local模式
上述已经解压配置好spark环境变量,本地模式不需要配置其他配置文件,可以直接使用,很简单吧,先测试一下运行样例:
cd /opt/soft/spark/binrun-example SparkPi 10

可以计算出结果
测试spark-shell
spark-shell

启动成功,说明Local模式部署成功
2.Standalone模式
1>修改Spark的配置文件spark-env.sh
cd /opt/soft/spark/conf cp spark-env.sh.template spark-env.sh vim spark-env.sh
添加如下配置:
# 主节点机器名称 export SPARK_MASTER_HOST=s141 # 默认端口号为7077 export SPARK_MASTER_PORT=7077
2>修改配置文件slaves(从节点配置)
cd /opt/soft/spark/conf
cp slaves.template slaves
vim slaves
删除原有节点,添加从节点主机如下配置:
s142
s143
s144
s145
3>将spark目录发送到其他机器,可以使用scp一个一个机器复制,这里使用的是自己写的批量复制脚本xrsync.sh(hadoop批量命令脚本xrsync.sh传输脚本)
xrsync.sh spark-3.0.1-bin-hadoop2.7
4>在各个机器中建立spark软连接,可以进入各个机器的/opt/soft目录
ln -s /opt/soft/spark-3.0.1-bin-hadoop2.7 /opt/soft/spark
这里使用的是批量执行命令脚本xcall.sh(hadoop批量命令脚本xcall.sh及jps找不到命令解决)
xcall.sh ln -s /opt/soft/spark-3.0.1-bin-hadoop2.7 /opt/soft/spark

5>启动spark集群
cd /opt/soft/spark/sbin 可以单独启动master和slave ./start-master.sh ./start-slaves.sh spark://s141:7077 也可以一键启动master和slave ./start-all.sh
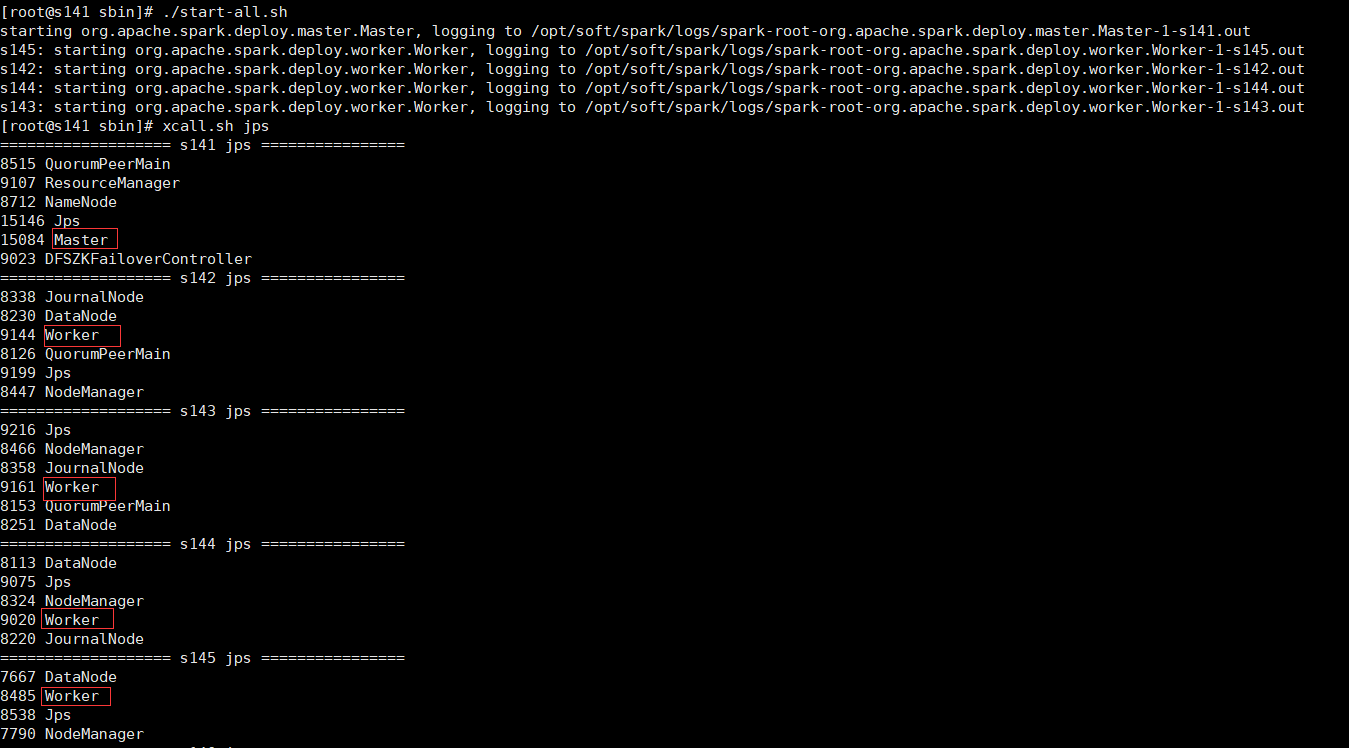
可以看到master和worker进程已经启动成功
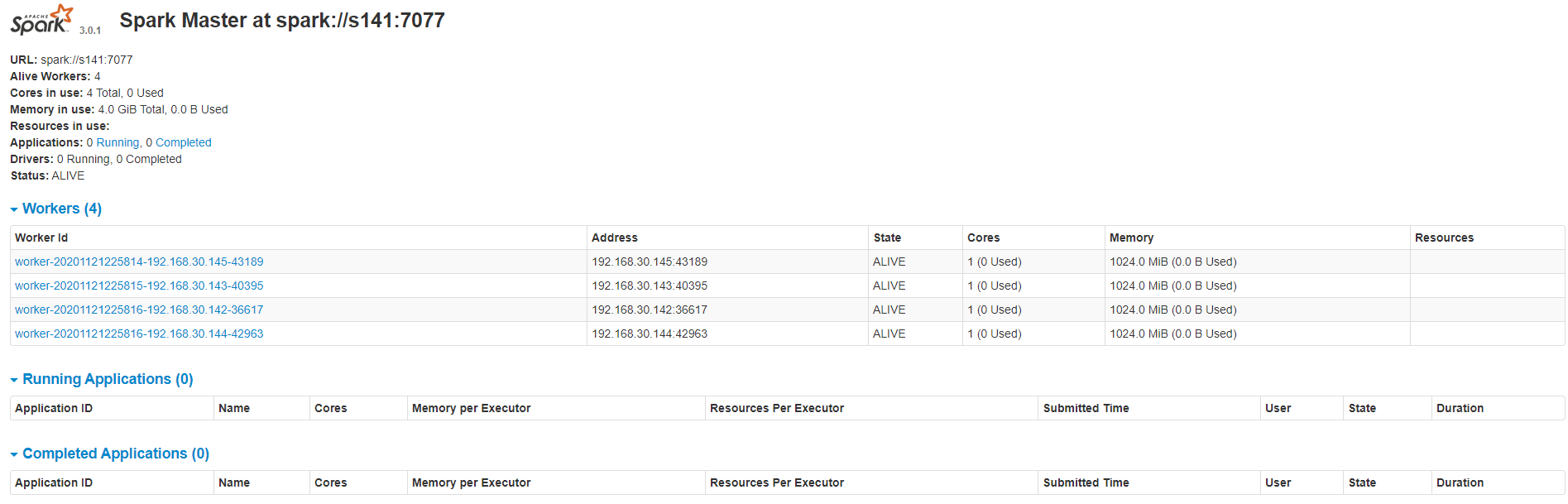
6>查看集群资源页面(webUI:http://192.168.30.141:8080/),如果8080端口查不到可以看一下master启动日志,可能是8081端口

7>进入集群shell验证
cd /opt/soft/spark/bin
./spark-shell –master spark://s141:7077

也是正常的,说明Standalone模式部署成功
3.yarn集群模式
1>修改配置文件spark-env.sh
在Standalone模式下搭建yarn集群模式很简单,只需要在spark-env.sh配置文件加入如下内容即可。
# 添加hadoop的配置目录
export HADOOP_CONF_DIR=/opt/soft/hadoop/etc/hadoop
将spark-env.sh分发到各个机器

4>启动spark集群
先启动Hadoop的yarn集群
start-yarn.sh
再启动spark集群,和Standalone模式一样有两种方式
cd /opt/soft/spark/sbin 可以单独启动master和slave ./start-master.sh ./start-slaves.sh spark://s141:7077 也可以一键启动master和slave ./start-all.sh
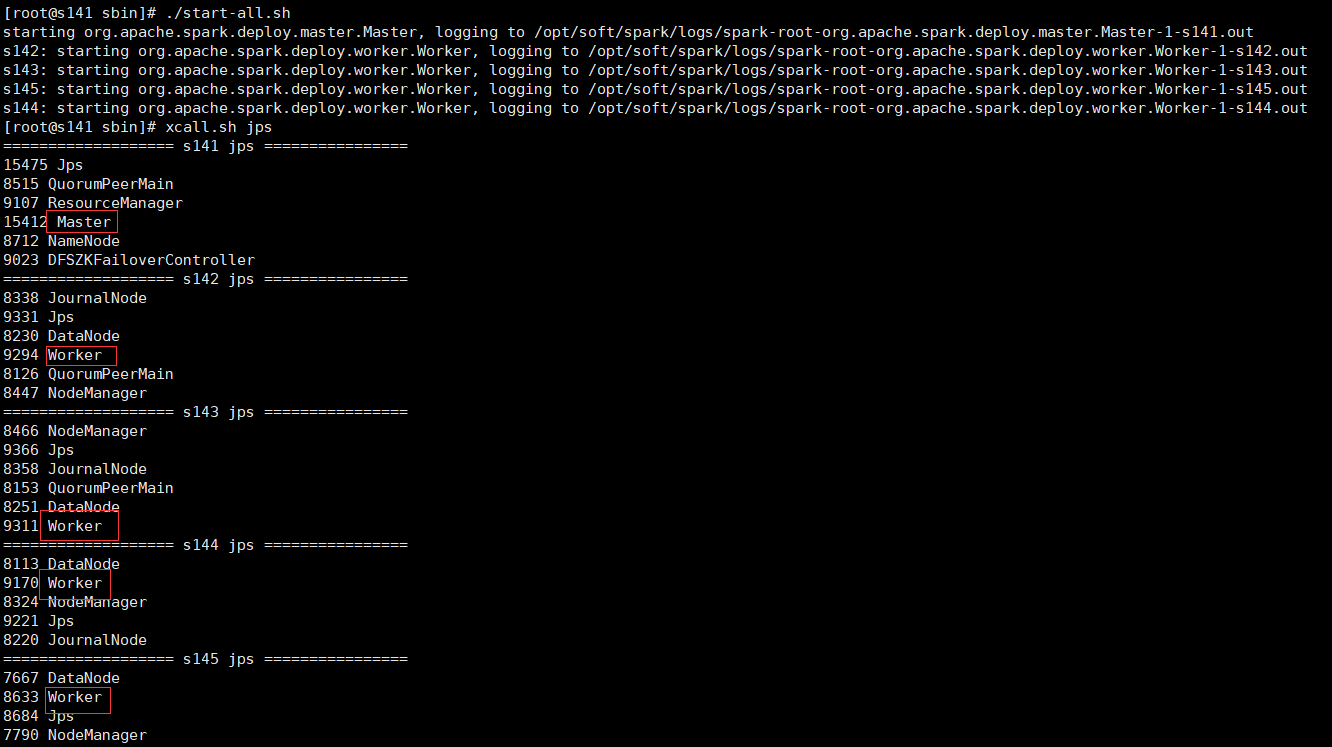
查看master和worker进程正常
5>查看集群资源页面(webUI:http://192.168.30.141:8080/),如果8080端口查不到可以看一下master启动日志,可能是8081端口
6>进入集群shell验证
cd /opt/soft/spark/bin
./spark-shell –master yarn

启动也正常
7>spark的历史服务器集成yarn
修改Hadoop的mapred-site.xml,将下面配置直接追加到最后,s141改成自己的机器即可
<!--Spark Yarn-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>s141:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>s141:19888</value>
</property>
由于虚拟机资源有限,在运行时会因为使用内存超出分配值杀死而失败,需要修改hadoop的/hadoop/etc/hadoop/yarn-site.xml配置文件,然后分发
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否开启聚合日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--允许第三方程序,例如spark将Job的日志,提交给Hadoop的历史服务 -->
<property>
<name>yarn.log.server.url</name>
<value>http://s141:19888/jobhistory/logs</value>
</property>
<!-- 配置日志过期时间,单位秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
将上述修改的配置文件分发到其他机器
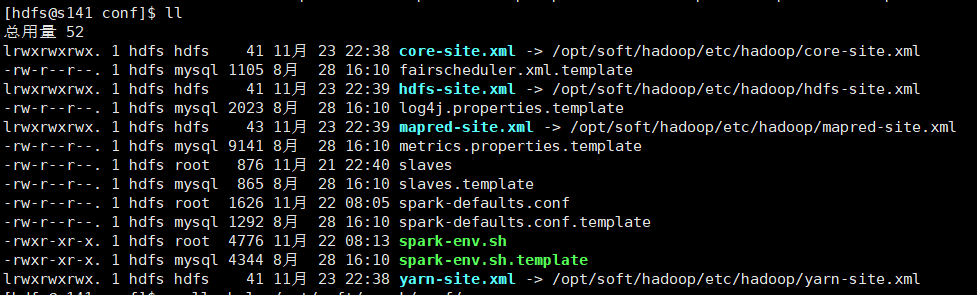
另外在spark conf目录下建立对Hadoop配置文件core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml的软连接,这里使用的是批量创建软连接
xcall.sh ln -s /opt/soft/hadoop/etc/hadoop/core-site.xml /opt/soft/spark/conf/core-site.xml
xcall.sh ln -s /opt/soft/hadoop/etc/hadoop/hdfs-site.xml /opt/soft/spark/conf/hdfs-site.xml
xcall.sh ln -s /opt/soft/hadoop/etc/hadoop/yarn-site.xml /opt/soft/spark/conf/yarn-site.xml
xcall.sh ln -s /opt/soft/hadoop/etc/hadoop/mapred-site.xml /opt/soft/spark/conf/mapred-site.xml
启动Hadoop历史服务器
# 启动Hadoop 历史服务器
mr-jobhistory-daemon.sh start historyserver
修改spark-defaults.conf.template文件名为spark-defaults.conf
spark.eventLog.enabled true #HDFS的节点和端口和目录(HDFS上的目录需要提前存在) spark.eventLog.dir hdfs://mycluster/spark/logs #spark的历史服务器,在spark所在节点,端口18080 spark.yarn.historyServer.address=192.168.30.141:18080 spark.history.ui.port=18080
修改spark-env.sh文件,配置日志存储路径
#spark的历史服务器 export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://mycluster/spark/logs -Dspark.history.retainedApplications=30"
启动spark历史服务器,在s141集群上执行如下命令:
sbin/start-history-server.sh
8>测试官方demo
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.12-3.0.1.jar 10
查看yarn调度UI界面:http://192.168.30.141:8088/

spark任务

spark各阶段执行耗时详情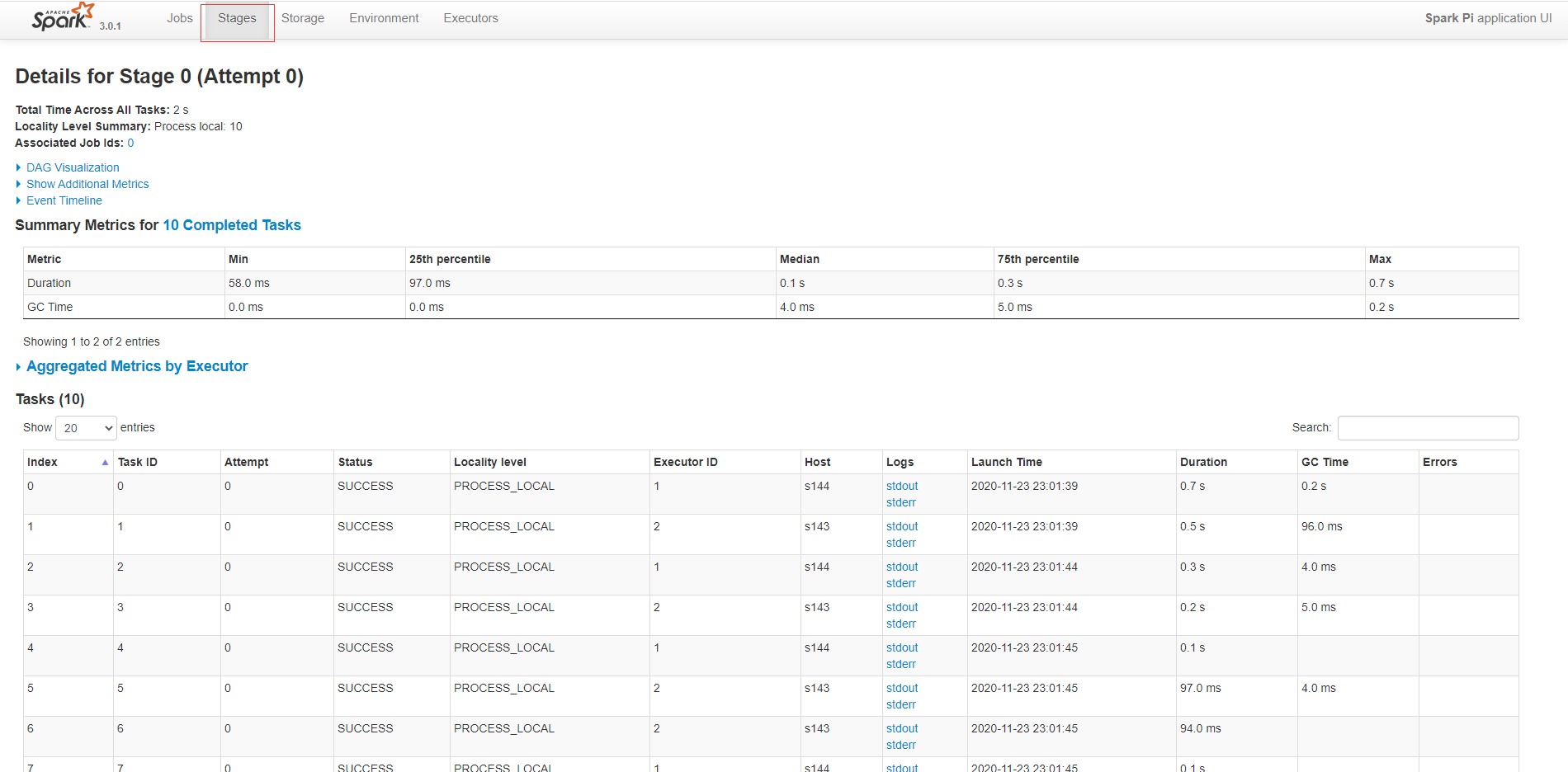
spark执行状态及日志查看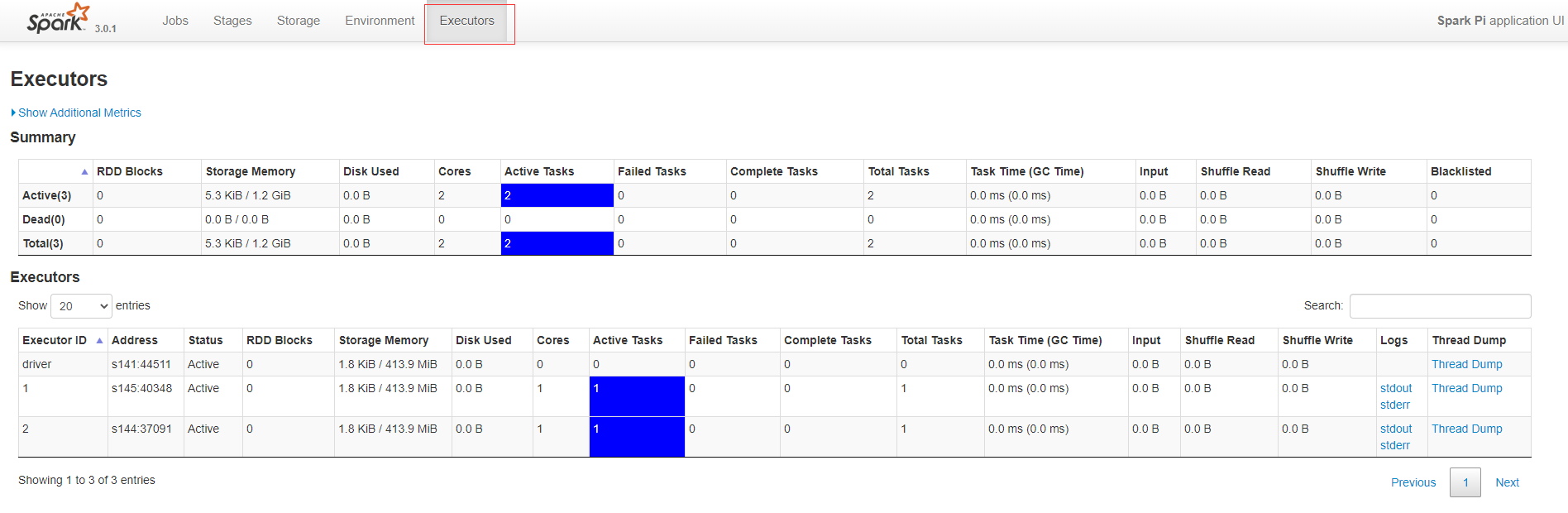
日志信息

启动流程:
# 启动HDFS start-all.sh # 启动Hadoop 历史服务器 mr-jobhistory-daemon.sh start historyserver # 启动Spark 集群 sbin/start-all.sh # 启动Spark 历史服务器 sbin/start-history-server.sh