一、介绍
MyBatis是一个半自动的持久层框架,对JDBC的操作数据库过程进行了封装,使开发者只需要关注SQL本身,而不需要自己实现JDBC(注册驱动、创建Connection、创建Statement、设置参数、结果收集等处理)。Mybatis通过注解或者xml文件对JDBC各种操作进行配置,并将结果映射成Java对象返回。

面试题:Mybatis & Hibrenate
Mybatis
好处: 1、通过直接编写SQL语句,可以直接对SQL进行性能的优化; 2、学习门槛低,学习成本低。只要有SQL基础,就可以学习mybatis,而且很容易上手; 3、由于直接编写SQL语句,所以灵活多变,代码维护性更好。 缺点: 4、不能支持数据库无关性,即数据库发生变更,要写多套代码进行支持,移植性不好。 a)Mysql:limit b)Oracle:rownum 5、需要编写结果映射。
Hibernate技术特点: 好处: 1、标准的orm框架,程序员不需要编写SQL语句。 2、具有良好的数据库无关性,即数据库发生变化的话,代码无需再次编写。 a)以后,mysql数据迁移到oracle,只需要改方言配置 缺点: 3、学习门槛高,需要对数据关系模型有良好的基础,而且在设置OR映射的时候,需要考虑好性能和对象模型的权衡。 4、程序员不能自主的去进行SQL性能优化。
二、Mybatis执行流程
1、 mybatis配置文件,包括Mybatis全局配置文件和Mybatis映射文件.。其中全局配置文件配置了数据源、事务等信息;映射文件配置了SQL执行相关的 信息。
2、 mybatis通过读取配置文件信息(全局配置文件和映射文件),构造出SqlSessionFactory,即会话工厂。
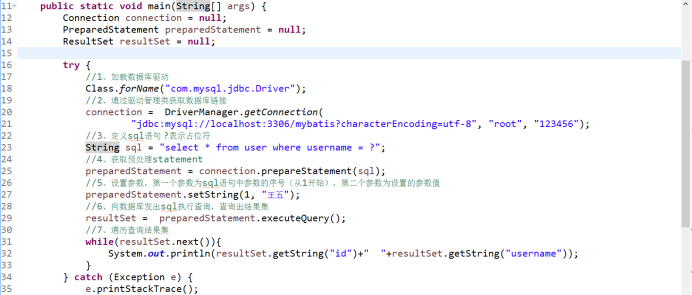
3、 通过SqlSessionFactory,可以创建SqlSession即会话。Mybatis是通过SqlSession来操作数据库的。
4、 SqlSession本身不能直接操作数据库,它是通过底层的Executor执行器接口来操作数据库的。Executor接口有两个实现类,一个是普通执行器,一个是缓存执行器(默认)。
5 Executor执行器要处理的SQL信息是封装到一个底层对象MappedStatement中。该对象包括:SQL语句、输入参数映射信息、输出结果集映射信息。其中输入参数和输出结果的映射类型包括HashMap集合对象、POJO对象类型。
配置文件&映射文件 =》 SqlSessionFactory =》 SqlSession =》 Executor执行器 =》 MappedStatement
三、示例
1. 全局配置文件:SqlMapConfig.xml
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!-- 配置mybatis的环境信息 --> <environments default="development"> <environment id="development"> <!-- 配置JDBC事务控制,由mybatis进行管理 --> <transactionManager type="JDBC"></transactionManager> <!-- 配置数据源,采用dbcp连接池 --> <dataSource type="POOLED"> <property name="driver" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf8"/> <property name="username" value="root"/> <property name="password" value="123456"/> </dataSource> </environment> </environments>
<mappers>
<mapper resource = "sqlmap/User.xml"/>
</mappers> </configuration>
2. 映射文件 Usermapper.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- namespace:命名空间,它的作用就是对SQL进行分类化管理,可以理解为SQL隔离 注意:使用mapper代理开发时,namespace有特殊且重要的作用 --> <mapper namespace="com.qq.Usermapper.xml"> <!-- [id]:statement的id,要求在命名空间内唯一 [parameterType]:入参的java类型 [resultType]:查询出的单条结果集对应的java类型 [#{}]: 表示一个占位符? [#{id}]:表示该占位符待接收参数的名称为id。注意:如果参数为简单类型时,#{}里面的参数名称可以是任意定义
模糊查询
[${}]:表示拼接SQL字符串
[${value}]:表示要拼接的是简单类型参数。
注意:1、如果参数为简单类型时,${}里面的参数名称必须为value
2、${}会引起SQL注入,一般情况下不推荐使用。但是有些场景必须使用${},比如order by ${colname}
-->
<select id="findUserById" parameterType="int" resultType="com.gyf.domain.User">
SELECT * FROM USER WHERE id = #{id}
</select>
<!--
[${}]:表示拼接SQL字符串
[${value}]:表示要拼接的是简单类型参数。
注意:1、如果参数为简单类型时,${}里面的参数名称必须为value
2、${}会引起SQL注入,一般情况下不推荐使用。但是有些场景必须使用${},比如order by ${colname}
-->
<select id="findUserByName" parameterType="String" resultType="com.gyf.domain.User">
SELECT * FROM USER WHERE username like '%${value}%'
</select>
</mapper>
面试题:#{}和${}
#{}:相当于预处理中的占位符?。
#{}里面的参数表示接收java输入参数的名称。
#{}可以接受HashMap、POJO类型的参数。
当接受简单类型的参数时,#{}里面可以是value,也可以是其他。
#{}可以防止SQL注入。
${}:相当于拼接SQL串,对传入的值不做任何解释的原样输出。
${}会引起SQL注入,所以要谨慎使用。
${}可以接受HashMap、POJO类型的参数。
当接受简单类型的参数时,${}里面只能是value。
3. 返回主键--自增&UUID
MySQL返回自增主键,是指在insert之前MySQL会自动生成一个自增的主键。我们可以通过MySQL的函数获取到刚插入的自增主键:LAST_INSERT_ID()
<insert id="insertUser" parameterType="com.gyf.domain.User"> <!-- [selectKey标签]:通过select查询来生成主键 [keyProperty]:指定存放生成主键的属性 [resultType]:生成主键所对应的Java类型 [order]:指定该查询主键SQL语句的执行顺序,相对于insert语句 [last_insert_id]:MySQL的函数,要配合insert语句一起使用 --> <selectKey keyProperty="id" resultType="int" order="AFTER"> SELECT LAST_INSERT_ID() </selectKey> <!-- 如果主键的值是通过MySQL自增机制生成的,那么我们此处不需要再显示的给ID赋值 --> INSERT INTO USER (username,sex,birthday,address) VALUES(#{username},#{sex},#{birthday},#{address}) </insert>
MySQL返回UUID
<insert id="insertUser" parameterType="com.gyf.domain.User"> <selectKey keyProperty="id" resultType="String" order="BEFORE"> SELECT UUID() </selectKey> INSERT INTO USER (username,sex,birthday,address) VALUES(#{username},#{sex},#{birthday},#{address}) </insert>
4. Dao层 UserMapper.java

四、关联查询
1. 一对一:User - Orders
resultType
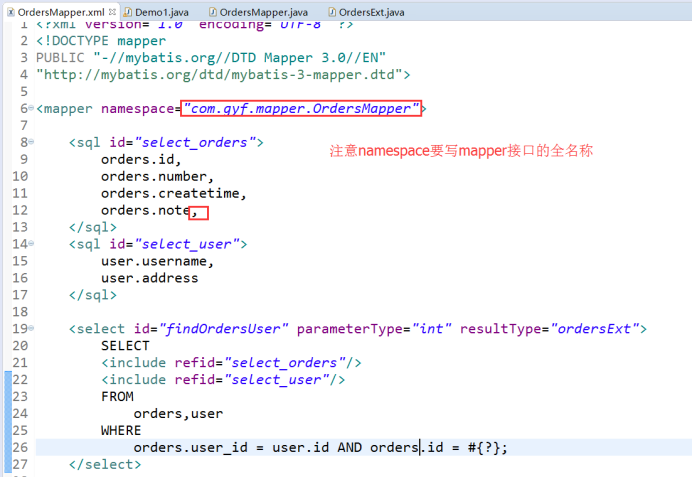
resultMap
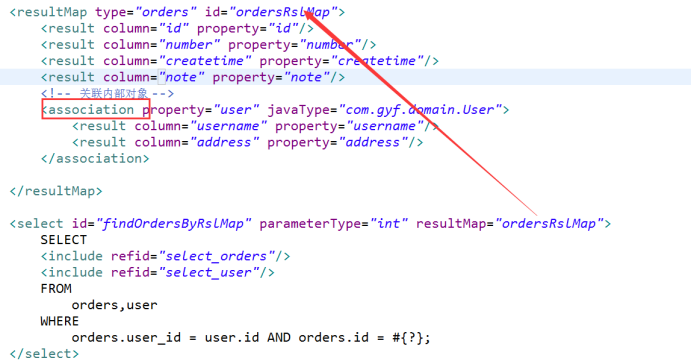
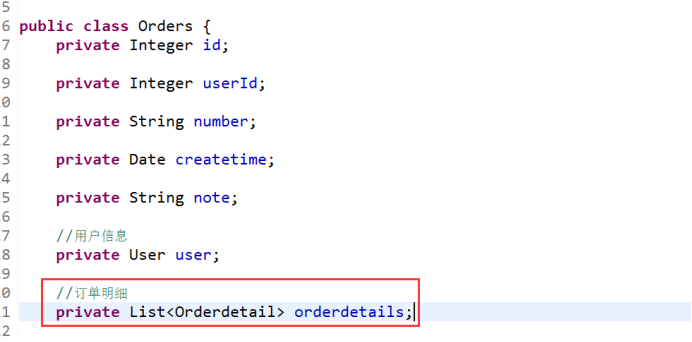
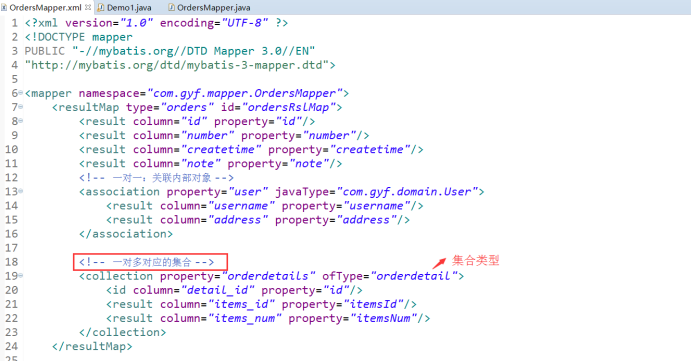
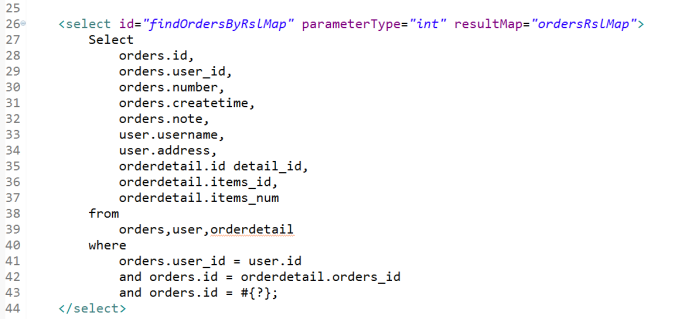
2. 一对多: Orders - OrdersDdetail
mybatis使用resultMap的collection对关联查询的多条记录映射到一个list集合属性中。
使用resultType实现:需要对结果集进行二次处理。将订单明细映射到orders中的orderdetails中,需要自己处理,使用双重循环遍历,去掉重复记录,将订单明细放在orderdetails中。
i
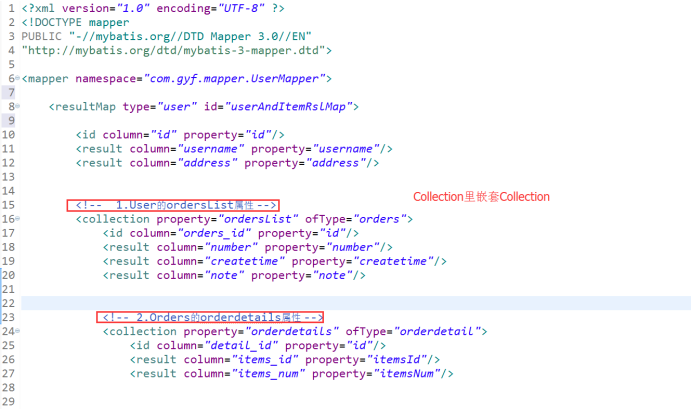
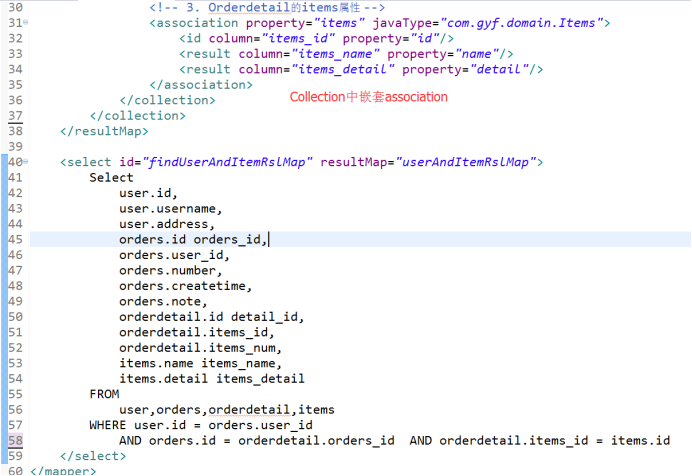
3. 多对多: OrderDetail - items
4. 总结
① 输入参数 ParameterType
可以使用别名或者类的全限定名。它可以接收简单类型,POJO对象、HashMap。
② 输出映射 resultType / resultMap
resultType:将查询结果按照sql列名pojo属性名一致性映射到pojo中。
resultMap:使用association和collection完成一对一和一对多高级映射(对结果有特殊的映射要求)。
association:将关联查询信息映射到一个pojo对象中。
collection:将关联查询信息映射到一个list集合中。
resultMap可以实现延迟加载,resultType无法实现延迟加载
五、延时加载
延迟加载又叫懒加载,也叫按需加载。也就是说先加载主信息,在需要的时候,再去加载从信息。在mybatis中,resultMap标签 的association标签和collection标签具有延迟加载的功能。
1.示例

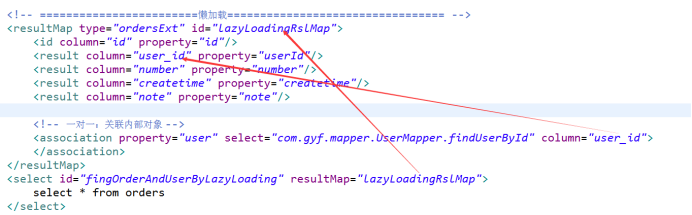
2.实现原理
使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
六、缓存
缓存技术是一种“以空间换时间”的设计理念,是利用内存空间资源来提高数据检索速度的有效手段之一。Mybatis包含一个非常强大的查询缓存特性,可以非常方便地配置和定制。MyBatis将数据缓存设计成两级结构,分为一级缓存、二级缓存,如下图所示:

一级缓存

1. 一级缓存简介
一级缓存基于PrepetualCache的HashMap本地缓存,其存储作用域为Session,位于表示一次数据库会话的SqlSession对象之中。
每当我们使用MyBatis开启一次和数据库的会话,MyBatis会创建出一个SqlSession对象表示一次数据库会话。在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
一级缓存是MyBatis内部实现的一个特性,用户不能配置,默认情况下自动支持的缓存,用户没有定制它的权利(不过这也不是绝对的,可以通过开发插件对它进行修改)。

2. 一级缓存实现
实际上, MyBatis只是一个MyBatis对外的接口,SqlSession将它的工作交给了Executor执行器这个角色来完成,负责完成对数据库的各种操作。当创建了一个SqlSession对象时,MyBatis会为这个SqlSession对象创建一个新的Executor执行器,而缓存信息就被维护在这个Executor执行器中,MyBatis将缓存和对缓存相关的操作封装成了Cache接口中。
Executor接口的实现类BaseExecutor中拥有一个Cache接口的实现类PerpetualCache,则对于BaseExecutor对象而言,它将使用PerpetualCache对象维护缓存。
综上,SqlSession对象、Executor对象、Cache对象之间的关系如下图所示:

3. 一级缓存的生命周期
a. MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
b. 如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
c. 如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用;
d. SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用;
4. 一级缓存的性能分析
Cache最核心的实现其实就是一个Map,将本次查询使用的特征值作为key,将查询结果作为value存储到Map中。所以MyBatis的一级缓存就是使用了简单的HashMap,MyBatis只负责将查询数据库的结果存储到缓存中去, 不会去判断缓存存放的时间是否过长、是否过期,因此也就没有对缓存的结果进行更新这一说了。
此外,Mybatis并没有对HashMap的容量和大小进行限制,有可能导致OutOfMemoryError错误。但是MyBatis这样设计也有它自己的理由:
**a. ** 一般而言SqlSession的生存时间很短。一般情况下使用一个SqlSession对象执行的操作不会太多,执行完就会消亡;
**b. ** 对于某一个SqlSession对象而言,只要执行update操作(update、insert、delete),都会将这个SqlSession对象中对应的一级缓存清空掉,所以一般情况下不会出现缓存过大,影响JVM内存空间的问题;
**c. **可以手动地释放掉SqlSession对象中的缓存。
二级缓存
1. MyBatis二级缓存的介绍和划分
二级缓存和一级缓存的机制相同,默认也是采用PrepetualCache、HashMap存储,但是二级缓存是Application应用级别的缓存,它的是生命周期很长,跟Application的声明周期一样,也就是说它的作用范围是整个Application应用。但是MyBatis并不是简单地对整个Application就只有一个Cache缓存对象,它将缓存划分的更细,即是Mapper(nameSpace)级别的,即每一个Mapper都可以拥有一个Cache对象,具体如下:
a.为每一个Mapper分配一个Cache缓存对象(使用<cache>节点配置)
MyBatis将Application级别的二级缓存细分到Mapper级别,即对于每一个Mapper.xml,如果在其中使用了<cache> 节点,则MyBatis会为这个Mapper创建一个Cache缓存对象,如下图所示:

注: 上述的每一个Cache对象,都会有一个自己所属的namespace命名空间,并且会将Mapper的 namespace作为它们的ID。
b.多个Mapper共用一个Cache缓存对象(使用<cache-ref>节点配置)
如果你想让多个Mapper公用一个Cache的话,你可以使用<cache-ref namespace="">节点,来指定你的这个Mapper使用到了哪一个Mapper的Cache缓存。

在同一个namespace下的mapper文件中,执行相同的查询SQL,第一次会去查询数据库,并写到缓存中;第二次直接从缓存中取。当执行SQL时两次查询中间发生了增删改操作,则二级缓存清空。

2. 二级缓存的工作模式
如上所言,一个SqlSession对象会使用一个Executor对象来完成会话操作,MyBatis的二级缓存机制的关键就是对这个Executor对象做文章。如果用户配置了"cacheEnabled=true",那么MyBatis在为SqlSession对象创建Executor对象时,会对Executor对象加上一个装饰者:CachingExecutor,这时SqlSession使用CachingExecutor对象来完成操作请求。CachingExecutor对于查询请求,会先判断该查询请求在Application级别的二级缓存中是否有缓存结果,如果有查询结果,则直接返回缓存结果;如果缓存中没有,再交给真正的Executor对象来完成查询操作,之后CachingExecutor会将真正Executor返回的查询结果放置到缓存中,然后在返回给用户。

3. 使用二级缓存,必须要具备的条件
MyBatis对二级缓存的支持粒度很细,它会指定某一条查询语句是否使用二级缓存。
虽然在Mapper中配置了<cache>,并且为此Mapper分配了Cache对象,这并不表示我们使用Mapper中定义的查询语句查到的结果都会放置到Cache对象之中,我们必须指定Mapper中的某条选择语句是否支持缓存,即如下所示,在<select>节点中配置useCache="true",Mapper才会对此Select的查询支持缓存特性,否则,不会对此select查询,不会经过Cache缓存。如下所示,select语句配置了useCache="true",则表明这条select语句的查询会使用二级缓存。
<select id="selectByMinSalary" resultMap="BaseResultMap" parameterType="java.util.Map" useCache="true">
总之,要想使某条Select查询支持二级缓存,你需要保证:
- MyBatis支持二级缓存的总开关:全局配置(mybatis-config.xml)变量参数 cacheEnabled=true。

-
该select语句所在的Mapper,配置了<cache> 或<cached-ref>节点,并且有效。

- 该select语句的参数 useCache=true。
-
Pojo类必须实现序列化接口。




4. 刷新缓存
在mapper的同一个namespace中,如果有其他insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。
设置statement配置中的flushCache="true"属性,默认情况下为true即刷新缓存,如果改成false则不会刷新缓存。

5. 二级缓存实现的选择
MyBatis对二级缓存的设计非常灵活,它自己内部实现了一系列的Cache缓存实现类,并提供了各种缓存刷新策略如LRU,FIFO等等;另外,MyBatis还允许用户自定义Cache接口实现,用户是需要实现org.apache.ibatis.cache.Cache接口,然后将Cache实现类配置在<cache type="">节点的type属性上即可;除此之外,MyBatis还支持跟第三方内存缓存库如Ehcache的集成。
MyBatis自身提供的二级缓存的实现
MyBatis自身提供了丰富的,并且功能强大的二级缓存的实现,它拥有一系列的Cache接口装饰者,可以满足各种对缓存操作和更新的策略。 对于每个Cache而言,都有一个容量限制,MyBatis各供了各种策略来对Cache缓存的容量进行控制,以及对Cache中的数据进行刷新和置换。如下类图所示:

6. Mybatis整合第三方缓存框架
- 我们系统为了提高系统并发性能,一般对系统进行分布式部署(集群部署方式)。
- 不使用分布式缓存,缓存的数据在各个服务单独存储,不方便系统开发,所以要使用分布式缓存对缓存数据进行集中管理。
- 第三方缓存框架一般有ehcache、memcache、redis缓存框架。
七、相关面试题