Python爬虫代码:
1 import re
2 import time
3 import traceback
4
5 from bs4 import BeautifulSoup
6 from lxml import etree
7 import pymysql
8 import requests
9 #连接数据库 获取游标
10 def get_conn():
11 """
12 :return: 连接,游标
13 """
14 # 创建连接
15 conn = pymysql.connect(host="82.157.112.34",
16 user="root",
17 password="root",
18 db="MovieRankings",
19 charset="utf8")
20 # 创建游标
21 cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
22 if ((conn != None) & (cursor != None)):
23 print("数据库连接成功!游标创建成功!")
24 else:
25 print("数据库连接失败!")
26 return conn, cursor
27 #关闭数据库连接和游标
28 def close_conn(conn, cursor):
29 if cursor:
30 cursor.close()
31 if conn:
32 conn.close()
33 return 1
34 def get_imdb():
35
36 # url='https://www.imdb.cn/feature-film/1-0-0-0/?page=1'
37 headers={
38 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
39 }
40 dataRes=[] #最终结果集
41 temp_list=[] #暂时结果集
42
43 # print(all_li)
44
45 for i in range(200,202):
46 url_='https://www.imdb.cn/feature-film/1-0-0-0/?page='+str(i)
47 response = requests.get(url=url_, headers=headers)
48 # print(response)
49 response.encoding = 'utf-8'
50 page_text = response.text
51 # print(page_text)
52 etree_ = etree.HTML(page_text)
53 all_li = etree_.xpath('//div[@class="hot_box"]/ul/li') #获取所有li
54 #判断all_li是否为空
55 if(len(all_li)==0):
56 print("爬取结束,all_list为空!")
57 if(len(dataRes)!=0):
58 return dataRes;
59 else:
60 return ;
61 print(url_)
62 for li in all_li:
63 name=li.xpath('./a[1]/img/@alt')
64 if(len(name)==0):
65 name.append("电影名错误")
66 # print(name)
67 #存姓名
68 temp_list.append(name[0])
69
70 score=li.xpath('./span[@class="img_score"]/@title')
71 if(len(score)==0):
72 score.append("imdb暂无评分")
73 # print(score)
74 #存分数
75 temp_list.append(score[0])
76 # print(temp_list)
77 #存到dataRes 把temp_list置为空
78 dataRes.append(temp_list)
79 temp_list=[]
80 print(dataRes)
81 return dataRes
82 def insert_imdb():
83 """
84 插入imdb数据
85 :return:
86 """
87 cursor = None
88 conn = None
89 try:
90 list_=[]
91 list = get_imdb()
92 if(type(list)!=type(list_)):
93 return ;
94 print(f"{time.asctime()}开始插入imdb数据")
95 conn, cursor = get_conn()
96 sql = "insert into movieimdb (id,name,score) values(%s,%s,%s)"
97 for item in list:
98 try:
99 print(item)
100 cursor.execute(sql, [0, item[0], item[1]])
101 except pymysql.err.IntegrityError:
102 print("重复!跳过!")
103 conn.commit() # 提交事务 update delete insert操作
104 print(f"{time.asctime()}插入imdb数据完毕")
105 finally:
106 close_conn(conn, cursor)
107 return;
108 # def get_dblen():
109 # conn,cursor=
110 # num_=
111
112 if __name__ == '__main__':
113 # get_imdb()
114 insert_imdb()

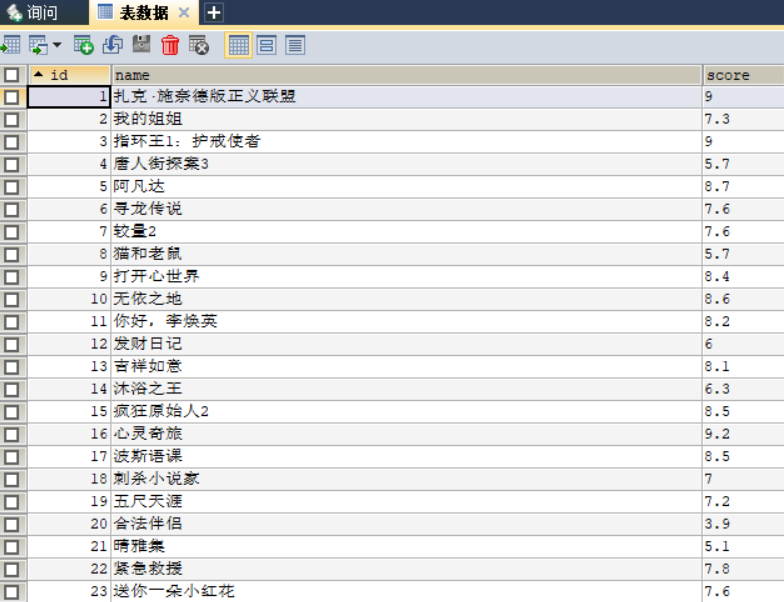
数据库